 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphTok: Morphologically Grounded Tokenization for Indian Languages
Apr 14, 2025



Tokenization is a crucial step in NLP, especially with the rise of large language models (LLMs), impacting downstream performance, computational cost, and efficiency. Existing LLMs rely on the classical Byte-pair Encoding (BPE) algorithm for subword tokenization that greedily merges frequent character bigrams. This often leads to segmentation that does not align with linguistically meaningful units. To address this, we propose morphology-aware segmentation as a pre-tokenization step prior to applying BPE. To facilitate morphology-aware segmentation, we create a novel dataset for Hindi and Marathi, incorporating sandhi splitting to enhance the subword tokenization. Experiments on downstream tasks show that morphologically grounded tokenization improves performance for machine translation and language modeling. Additionally, to handle the ambiguity in the Unicode characters for diacritics, particularly dependent vowels in syllable-based writing systems, we introduce Constrained BPE (CBPE), an extension to the traditional BPE algorithm that incorporates script-specific constraints. Specifically, CBPE handles dependent vowels. Our results show that CBPE achieves a 1.68\% reduction in fertility scores while maintaining comparable or improved downstream performance in machine translation, offering a computationally efficient alternative to standard BPE. Moreover, to evaluate segmentation across different tokenization algorithms, we introduce a new human evaluation metric, \textit{EvalTok}, enabling more human-grounded assessment.
Semantically Cohesive Word Grouping in Indian Languages
Jan 07, 2025
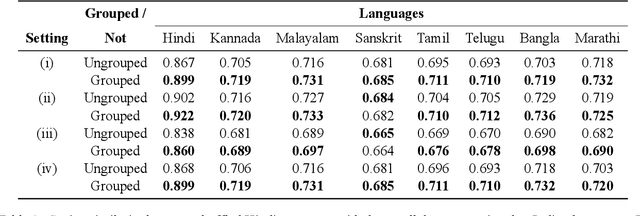
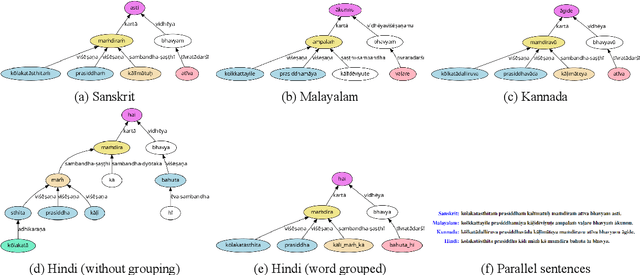

Indian languages are inflectional and agglutinative and typically follow clause-free word order. The structure of sentences across most major Indian languages are similar when their dependency parse trees are considered. While some differences in the parsing structure occur due to peculiarities of a language or its preferred natural way of conveying meaning, several apparent differences are simply due to the granularity of representation of the smallest semantic unit of processing in a sentence. The semantic unit is typically a word, typographically separated by whitespaces. A single whitespace-separated word in one language may correspond to a group of words in another. Hence, grouping of words based on semantics helps unify the parsing structure of parallel sentences across languages and, in the process, morphology. In this work, we propose word grouping as a major preprocessing step for any computational or linguistic processing of sentences for Indian languages. Among Indian languages, since Hindi is one of the least agglutinative, we expect it to benefit the most from word-grouping. Hence, in this paper, we focus on Hindi to study the effects of grouping. We perform quantitative assessment of our proposal with an intrinsic method that perturbs sentences by shuffling words as well as an extrinsic evaluation that verifies the importance of word grouping for the task of Machine Translation (MT) using decomposed prompting. We also qualitatively analyze certain aspects of the syntactic structure of sentences. Our experiments and analyses show that the proposed grouping technique brings uniformity in the syntactic structures, as well as aids underlying NLP tasks.