 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMcARL:Morphology-Control-Aware Reinforcement Learning for Generalizable Quadrupedal Locomotion
May 23, 2025We present Morphology-Control-Aware Reinforcement Learning (McARL), a new approach to overcome challenges of hyperparameter tuning and transfer loss, enabling generalizable locomotion across robot morphologies. We use a morphology-conditioned policy by incorporating a randomized morphology vector, sampled from a defined morphology range, into both the actor and critic networks. This allows the policy to learn parameters that generalize to robots with similar characteristics. We demonstrate that a single policy trained on a Unitree Go1 robot using McARL can be transferred to a different morphology (e.g., Unitree Go2 robot) and can achieve zero-shot transfer velocity of up to 3.5 m/s without retraining or fine-tuning. Moreover, it achieves 6.0 m/s on the training Go1 robot and generalizes to other morphologies like A1 and Mini Cheetah. We also analyze the impact of morphology distance on transfer performance and highlight McARL's advantages over prior approaches. McARL achieves 44-150% higher transfer performance on Go2, Mini Cheetah, and A1 compared to PPO variants.
HACL: History-Aware Curriculum Learning for Fast Locomotion
May 23, 2025We address the problem of agile and rapid locomotion, a key characteristic of quadrupedal and bipedal robots. We present a new algorithm that maintains stability and generates high-speed trajectories by considering the temporal aspect of locomotion. Our formulation takes into account past information based on a novel history-aware curriculum Learning (HACL) algorithm. We model the history of joint velocity commands with respect to the observed linear and angular rewards using a recurrent neural net (RNN). The hidden state helps the curriculum learn the relationship between the forward linear velocity and angular velocity commands and the rewards over a given time-step. We validate our approach on the MIT Mini Cheetah,Unitree Go1, and Go2 robots in a simulated environment and on a Unitree Go1 robot in real-world scenarios. In practice, HACL achieves peak forward velocity of 6.7 m/s for a given command velocity of 7m/s and outperforms prior locomotion algorithms by nearly 20%.
SuryaKiran at MEDIQA-Sum 2023: Leveraging LoRA for Clinical Dialogue Summarization
Jul 11, 2023
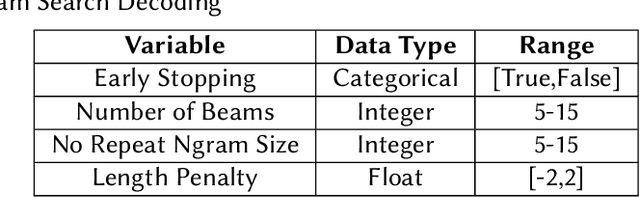
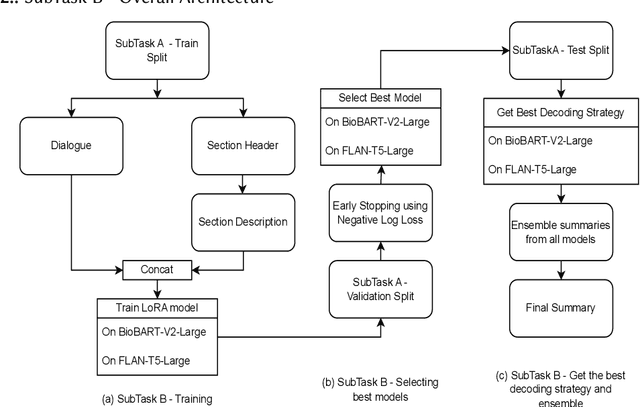
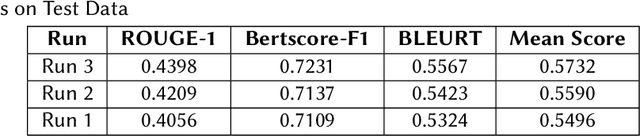
Finetuning Large Language Models helps improve the results for domain-specific use cases. End-to-end finetuning of large language models is time and resource intensive and has high storage requirements to store the finetuned version of the large language model. Parameter Efficient Fine Tuning (PEFT) methods address the time and resource challenges by keeping the large language model as a fixed base and add additional layers, which the PEFT methods finetune. This paper demonstrates the evaluation results for one such PEFT method Low Rank Adaptation (LoRA), for Clinical Dialogue Summarization. The evaluation results show that LoRA works at par with end-to-end finetuning for a large language model. The paper presents the evaluations done for solving both the Subtask A and B from ImageCLEFmedical {https://www.imageclef.org/2023/medical}
AI based approach to Trailer Generation for Online Educational Courses
Jan 10, 2023



In this paper, we propose an AI based approach to Trailer Generation in the form of short videos for online educational courses. Trailers give an overview of the course to the learners and help them make an informed choice about the courses they want to learn. It also helps to generate curiosity and interest among the learners and encourages them to pursue a course. While it is possible to manually generate the trailers, it requires extensive human efforts and skills over a broad spectrum of design, span selection, video editing, domain knowledge, etc., thus making it time-consuming and expensive, especially in an academic setting. The framework we propose in this work is a template based method for video trailer generation, where most of the textual content of the trailer is auto-generated and the trailer video is automatically generated, by leveraging Machine Learning and Natural Language Processing techniques. The proposed trailer is in the form of a timeline consisting of various fragments created by selecting, para-phrasing or generating content using various proposed techniques. The fragments are further enhanced by adding voice-over text, subtitles, animations, etc., to create a holistic experience. Finally, we perform user evaluation with 63 human evaluators for evaluating the trailers generated by our system and the results obtained were encouraging.
Language Models sounds the Death Knell of Knowledge Graphs
Jan 10, 2023



Healthcare domain generates a lot of unstructured and semi-structured text. Natural Language processing (NLP) has been used extensively to process this data. Deep Learning based NLP especially Large Language Models (LLMs) such as BERT have found broad acceptance and are used extensively for many applications. A Language Model is a probability distribution over a word sequence. Self-supervised Learning on a large corpus of data automatically generates deep learning-based language models. BioBERT and Med-BERT are language models pre-trained for the healthcare domain. Healthcare uses typical NLP tasks such as question answering, information extraction, named entity recognition, and search to simplify and improve processes. However, to ensure robust application of the results, NLP practitioners need to normalize and standardize them. One of the main ways of achieving normalization and standardization is the use of Knowledge Graphs. A Knowledge Graph captures concepts and their relationships for a specific domain, but their creation is time-consuming and requires manual intervention from domain experts, which can prove expensive. SNOMED CT (Systematized Nomenclature of Medicine -- Clinical Terms), Unified Medical Language System (UMLS), and Gene Ontology (GO) are popular ontologies from the healthcare domain. SNOMED CT and UMLS capture concepts such as disease, symptoms and diagnosis and GO is the world's largest source of information on the functions of genes. Healthcare has been dealing with an explosion in information about different types of drugs, diseases, and procedures. This paper argues that using Knowledge Graphs is not the best solution for solving problems in this domain. We present experiments using LLMs for the healthcare domain to demonstrate that language models provide the same functionality as knowledge graphs, thereby making knowledge graphs redundant.