 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong or Short or Both? An Exploration on Lookback Time Windows of Behavioral Features in Product Search Ranking
Sep 26, 2024



Customer shopping behavioral features are core to product search ranking models in eCommerce. In this paper, we investigate the effect of lookback time windows when aggregating these features at the (query, product) level over history. By studying the pros and cons of using long and short time windows, we propose a novel approach to integrating these historical behavioral features of different time windows. In particular, we address the criticality of using query-level vertical signals in ranking models to effectively aggregate all information from different behavioral features. Anecdotal evidence for the proposed approach is also provided using live product search traffic on Walmart.com.
Towards More Relevant Product Search Ranking Via Large Language Models: An Empirical Study
Sep 26, 2024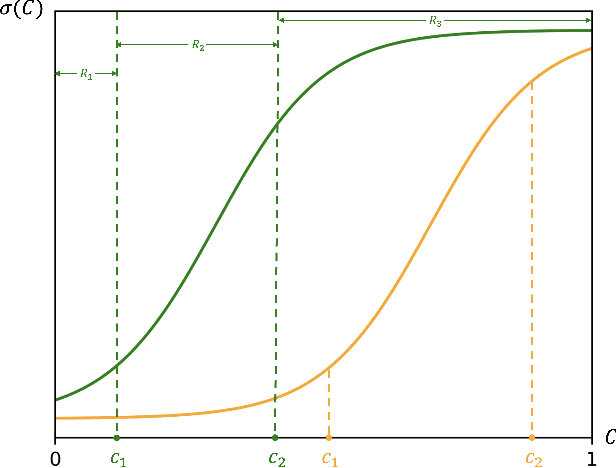

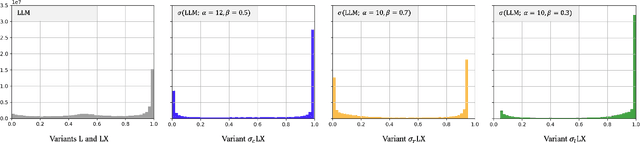
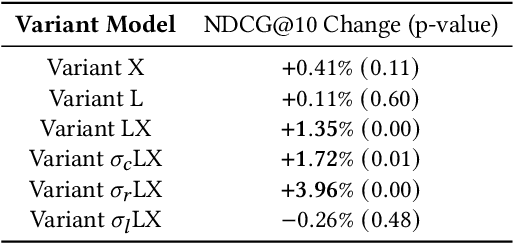
Training Learning-to-Rank models for e-commerce product search ranking can be challenging due to the lack of a gold standard of ranking relevance. In this paper, we decompose ranking relevance into content-based and engagement-based aspects, and we propose to leverage Large Language Models (LLMs) for both label and feature generation in model training, primarily aiming to improve the model's predictive capability for content-based relevance. Additionally, we introduce different sigmoid transformations on the LLM outputs to polarize relevance scores in labeling, enhancing the model's ability to balance content-based and engagement-based relevances and thus prioritize highly relevant items overall. Comprehensive online tests and offline evaluations are also conducted for the proposed design. Our work sheds light on advanced strategies for integrating LLMs into e-commerce product search ranking model training, offering a pathway to more effective and balanced models with improved ranking relevance.
LLM360: Towards Fully Transparent Open-Source LLMs
Dec 11, 2023



The recent surge in open-source Large Language Models (LLMs), such as LLaMA, Falcon, and Mistral, provides diverse options for AI practitioners and researchers. However, most LLMs have only released partial artifacts, such as the final model weights or inference code, and technical reports increasingly limit their scope to high-level design choices and surface statistics. These choices hinder progress in the field by degrading transparency into the training of LLMs and forcing teams to rediscover many details in the training process. We present LLM360, an initiative to fully open-source LLMs, which advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community. The goal of LLM360 is to support open and collaborative AI research by making the end-to-end LLM training process transparent and reproducible by everyone. As a first step of LLM360, we release two 7B parameter LLMs pre-trained from scratch, Amber and CrystalCoder, including their training code, data, intermediate checkpoints, and analyses (at https://www.llm360.ai). We are committed to continually pushing the boundaries of LLMs through this open-source effort. More large-scale and stronger models are underway and will be released in the future.
An Empirical Comparison of FAISS and FENSHSES for Nearest Neighbor Search in Hamming Space
Jul 28, 2019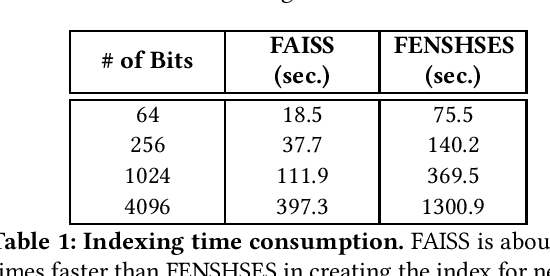
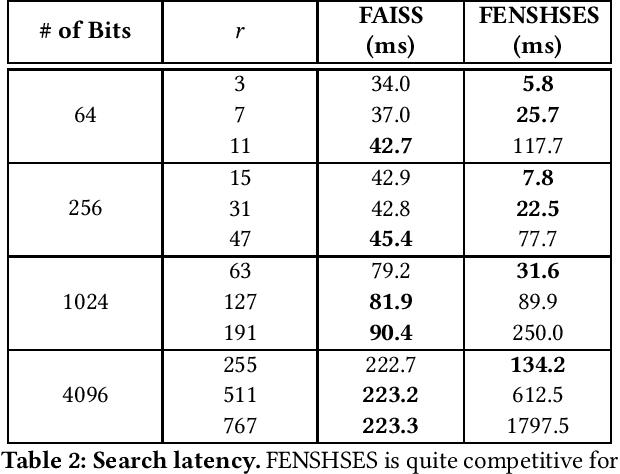
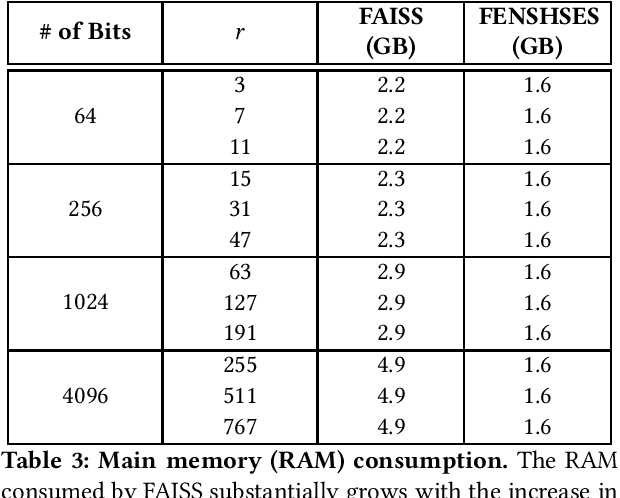
In this paper, we compare the performances of FAISS and FENSHSES on nearest neighbor search in Hamming space--a fundamental task with ubiquitous applications in nowadays eCommerce. Comprehensive evaluations are made in terms of indexing speed, search latency and RAM consumption. This comparison is conducted towards a better understanding on trade-offs between nearest neighbor search systems implemented in main memory and the ones implemented in secondary memory, which is largely unaddressed in literature.
Empowering Elasticsearch with Exact and Fast $r$-Neighbor Search in Hamming Space
Feb 20, 2019
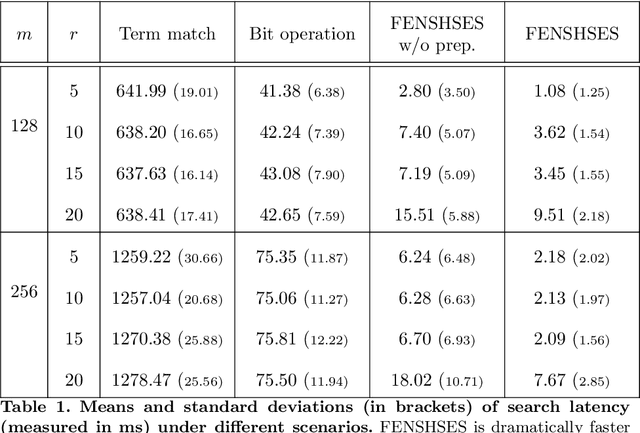

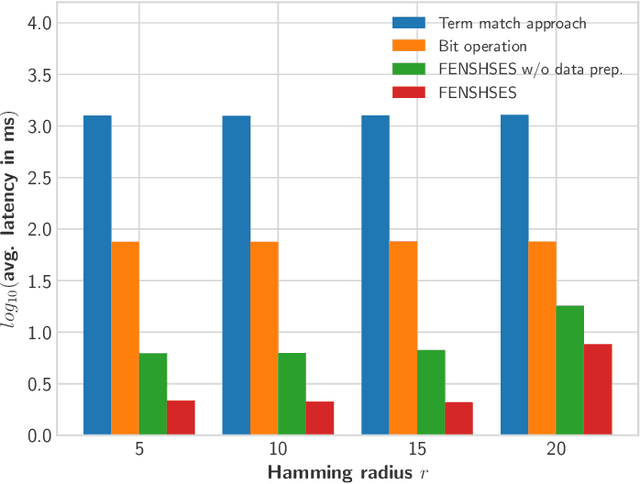
A growing interest has been witnessed recently in building nearest neighbor search solutions within Elasticsearch--one of the most popular full-text search engines. In this paper, we focus specifically on Hamming space nearest neighbor search using Elasticsearch. By combining three techniques: bit operation, substring filtering and data preprocessing with permutation, we develop a novel approach called FENSHSES (Fast Exact Neighbor Search in Hamming Space on Elasticsearch), which achieves dramatic speed-ups over the existing term match baseline. This will empower Elasticsearch with the capability of fast information retrieval even when documents (e.g., texts, images and sounds) are represented with binary codes--a common practice in nowadays semantic representation learning.
A Machine Learning Approach to Shipping Box Design
Sep 29, 2018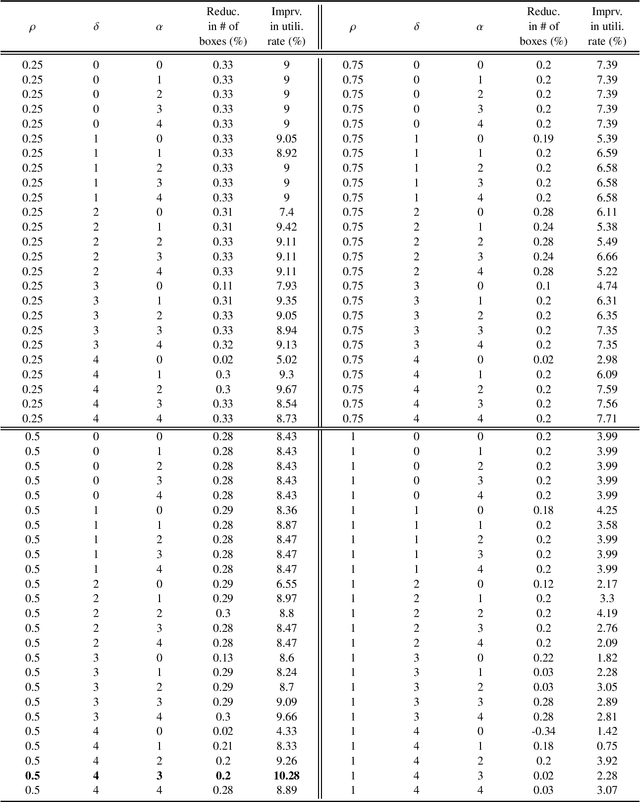
Having the right assortment of shipping boxes in the fulfillment warehouse to pack and ship customer's online orders is an indispensable and integral part of nowadays eCommerce business, as it will not only help maintain a profitable business but also create great experiences for customers. However, it is an extremely challenging operations task to strategically select the best combination of tens of box sizes from thousands of feasible ones to be responsible for hundreds of thousands of orders daily placed on millions of inventory products. In this paper, we present a machine learning approach to tackle the task by formulating the box design problem prescriptively as a generalized version of weighted $k$-medoids clustering problem, where the parameters are estimated through a variety of descriptive analytics. We test this machine learning approach on fulfillment data collected from Walmart U.S. eCommerce, and our approach is shown to be capable of improving the box utilization rate by more than $10\%$.
Towards Practical Visual Search Engine within Elasticsearch
Jun 23, 2018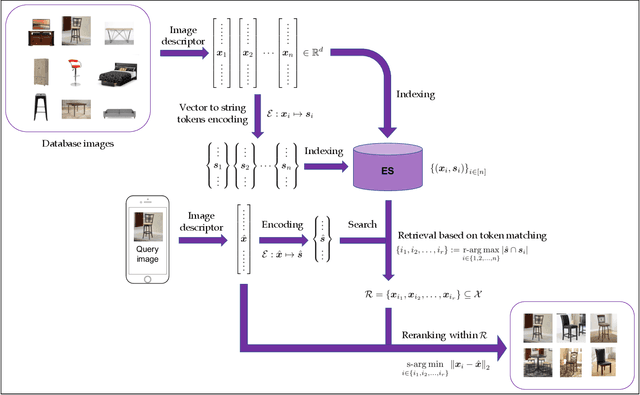
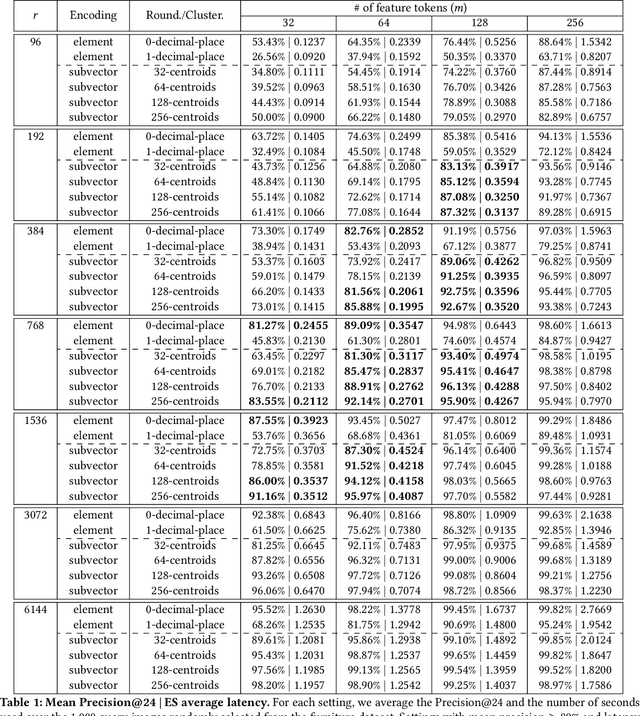

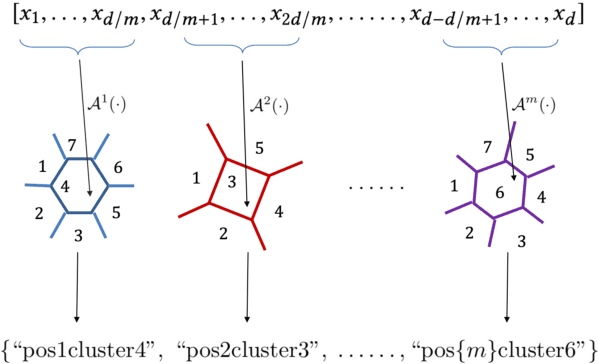
In this paper, we describe our end-to-end content-based image retrieval system built upon Elasticsearch, a well-known and popular textual search engine. As far as we know, this is the first time such a system has been implemented in eCommerce, and our efforts have turned out to be highly worthwhile. We end up with a novel and exciting visual search solution that is extremely easy to be deployed, distributed, scaled and monitored in a cost-friendly manner. Moreover, our platform is intrinsically flexible in supporting multimodal searches, where visual and textual information can be jointly leveraged in retrieval. The core idea is to encode image feature vectors into a collection of string tokens in a way such that closer vectors will share more string tokens in common. By doing that, we can utilize Elasticsearch to efficiently retrieve similar images based on similarities within encoded sting tokens. As part of the development, we propose a novel vector to string encoding method, which is shown to substantially outperform the previous ones in terms of both precision and latency. First-hand experiences in implementing this Elasticsearch-based platform are extensively addressed, which should be valuable to practitioners also interested in building visual search engine on top of Elasticsearch.
Revisiting Skip-Gram Negative Sampling Model with Regularization
Apr 01, 2018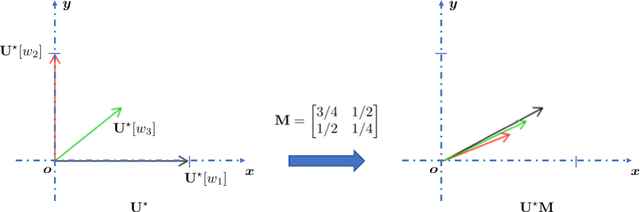
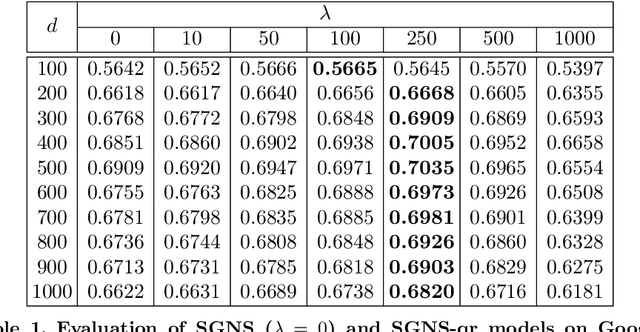
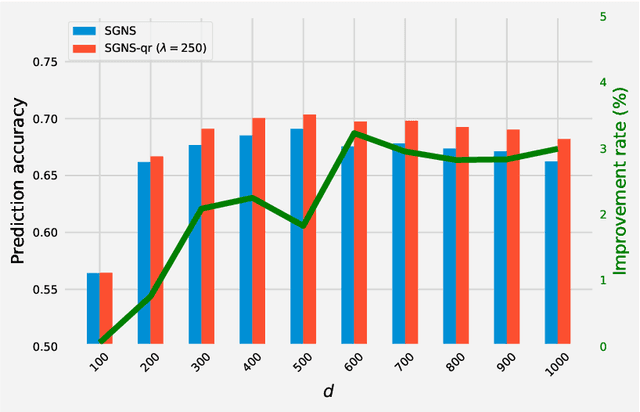
We revisit skip-gram negative sampling (SGNS), a popular neural-network based approach to learning distributed word representation. We first point out the ambiguity issue undermining the SGNS model, in the sense that the word vectors can be entirely distorted without changing the objective value. To resolve this issue, we rectify the SGNS model with quadratic regularization. A theoretical justification, which provides a novel insight into quadratic regularization, is presented. Preliminary experiments are also conducted on Google's analytical reasoning task to support the modified SGNS model.
Scalable Robust Matrix Recovery: Frank-Wolfe Meets Proximal Methods
May 29, 2017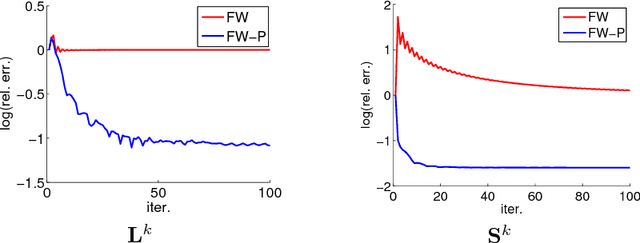
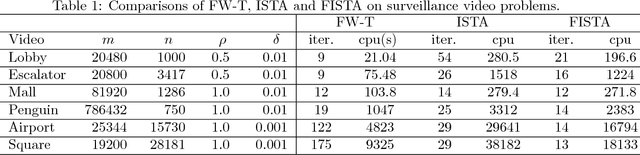
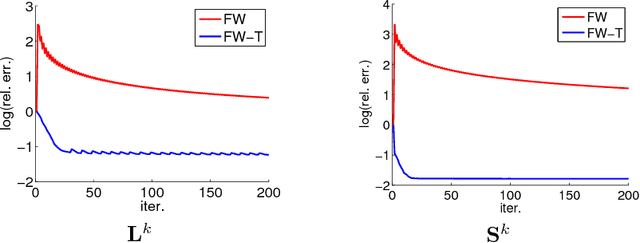
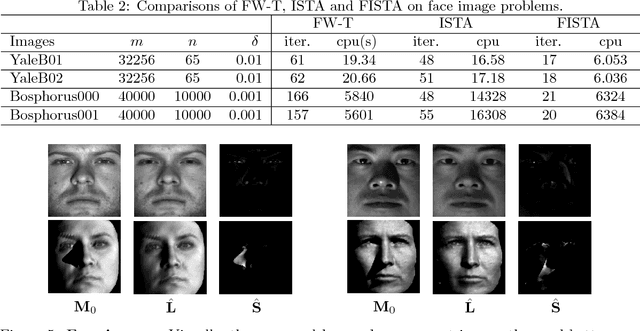
Recovering matrices from compressive and grossly corrupted observations is a fundamental problem in robust statistics, with rich applications in computer vision and machine learning. In theory, under certain conditions, this problem can be solved in polynomial time via a natural convex relaxation, known as Compressive Principal Component Pursuit (CPCP). However, all existing provable algorithms for CPCP suffer from superlinear per-iteration cost, which severely limits their applicability to large scale problems. In this paper, we propose provable, scalable and efficient methods to solve CPCP with (essentially) linear per-iteration cost. Our method combines classical ideas from Frank-Wolfe and proximal methods. In each iteration, we mainly exploit Frank-Wolfe to update the low-rank component with rank-one SVD and exploit the proximal step for the sparse term. Convergence results and implementation details are also discussed. We demonstrate the scalability of the proposed approach with promising numerical experiments on visual data.
Square Deal: Lower Bounds and Improved Relaxations for Tensor Recovery
Aug 15, 2013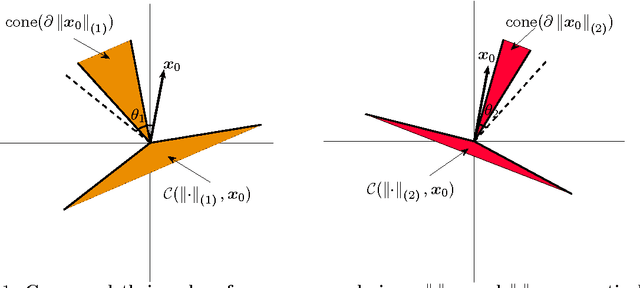


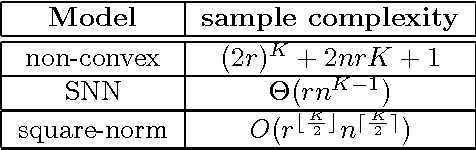
Recovering a low-rank tensor from incomplete information is a recurring problem in signal processing and machine learning. The most popular convex relaxation of this problem minimizes the sum of the nuclear norms of the unfoldings of the tensor. We show that this approach can be substantially suboptimal: reliably recovering a $K$-way tensor of length $n$ and Tucker rank $r$ from Gaussian measurements requires $\Omega(r n^{K-1})$ observations. In contrast, a certain (intractable) nonconvex formulation needs only $O(r^K + nrK)$ observations. We introduce a very simple, new convex relaxation, which partially bridges this gap. Our new formulation succeeds with $O(r^{\lfloor K/2 \rfloor}n^{\lceil K/2 \rceil})$ observations. While these results pertain to Gaussian measurements, simulations strongly suggest that the new norm also outperforms the sum of nuclear norms for tensor completion from a random subset of entries. Our lower bound for the sum-of-nuclear-norms model follows from a new result on recovering signals with multiple sparse structures (e.g. sparse, low rank), which perhaps surprisingly demonstrates the significant suboptimality of the commonly used recovery approach via minimizing the sum of individual sparsity inducing norms (e.g. $l_1$, nuclear norm). Our new formulation for low-rank tensor recovery however opens the possibility in reducing the sample complexity by exploiting several structures jointly.