 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Approach for Normalizing E-commerce Text Attributes (SANTA)
Jun 12, 2021
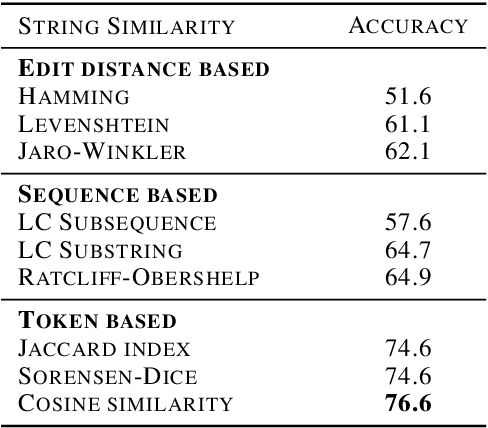
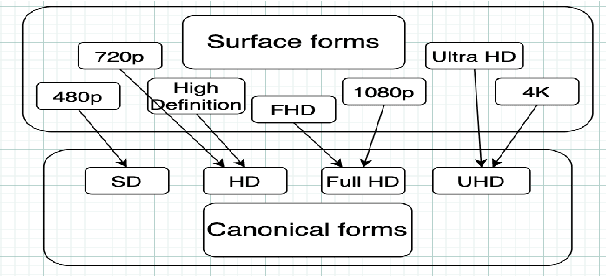

In this paper, we present SANTA, a scalable framework to automatically normalize E-commerce attribute values (e.g. "Win 10 Pro") to a fixed set of pre-defined canonical values (e.g. "Windows 10"). Earlier works on attribute normalization focused on fuzzy string matching (also referred as syntactic matching in this paper). In this work, we first perform an extensive study of nine syntactic matching algorithms and establish that 'cosine' similarity leads to best results, showing 2.7% improvement over commonly used Jaccard index. Next, we argue that string similarity alone is not sufficient for attribute normalization as many surface forms require going beyond syntactic matching (e.g. "720p" and "HD" are synonyms). While semantic techniques like unsupervised embeddings (e.g. word2vec/fastText) have shown good results in word similarity tasks, we observed that they perform poorly to distinguish between close canonical forms, as these close forms often occur in similar contexts. We propose to learn token embeddings using a twin network with triplet loss. We propose an embedding learning task leveraging raw attribute values and product titles to learn these embeddings in a self-supervised fashion. We show that providing supervision using our proposed task improves over both syntactic and unsupervised embeddings based techniques for attribute normalization. Experiments on a real-world attribute normalization dataset of 50 attributes show that the embeddings trained using our proposed approach obtain 2.3% improvement over best string matching and 19.3% improvement over best unsupervised embeddings.
LaTeX-Numeric: Language-agnostic Text attribute eXtraction for E-commerce Numeric Attributes
Apr 23, 2021

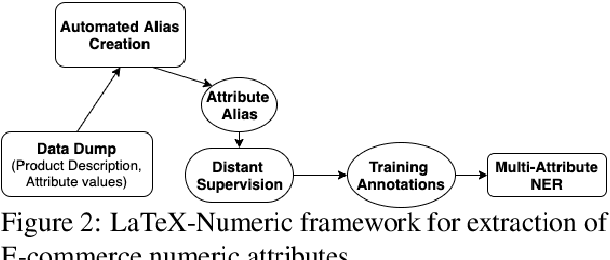

In this paper, we present LaTeX-Numeric - a high-precision fully-automated scalable framework for extracting E-commerce numeric attributes from product text like product description. Most of the past work on attribute extraction is not scalable as they rely on manually curated training data, either with or without the use of active learning. We rely on distant supervision for training data generation, removing dependency on manual labels. One issue with distant supervision is that it leads to incomplete training annotation due to missing attribute values while matching. We propose a multi-task learning architecture to deal with missing labels in the training data, leading to F1 improvement of 9.2% for numeric attributes over single-task architecture. While multi-task architecture benefits both numeric and non-numeric attributes, we present automated techniques to further improve the numeric attributes extraction models. Numeric attributes require a list of units (or aliases) for better matching with distant supervision. We propose an automated algorithm for alias creation using product text and attribute values, leading to a 20.2% F1 improvement. Extensive experiments on real world dataset for 20 numeric attributes across 5 product categories and 3 English marketplaces show that LaTeX-Numeric achieves a high F1-score, without any manual intervention, making it suitable for practical applications. Finally, we show that the improvements are language-agnostic and LaTeX-Numeric achieves 13.9% F1 improvement for 3 Romance languages.
Distantly Supervised Transformers For E-Commerce Product QA
Apr 07, 2021
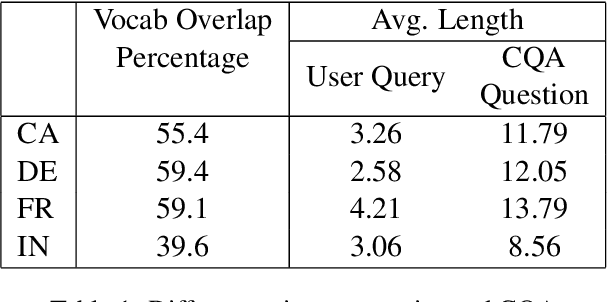
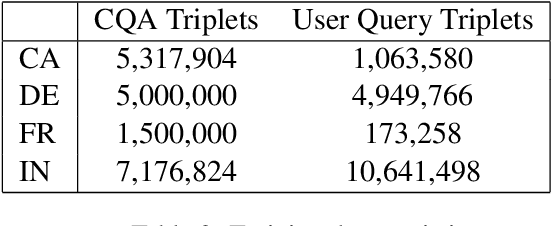
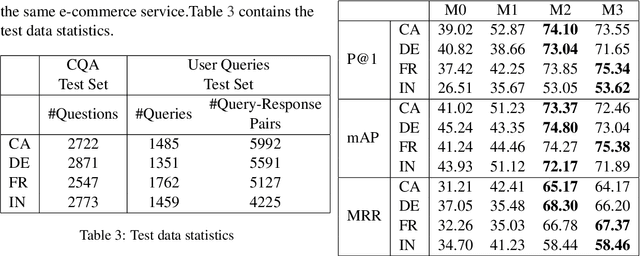
We propose a practical instant question answering (QA) system on product pages of ecommerce services, where for each user query, relevant community question answer (CQA) pairs are retrieved. User queries and CQA pairs differ significantly in language characteristics making relevance learning difficult. Our proposed transformer-based model learns a robust relevance function by jointly learning unified syntactic and semantic representations without the need for human labeled data. This is achieved by distantly supervising our model by distilling from predictions of a syntactic matching system on user queries and simultaneously training with CQA pairs. Training with CQA pairs helps our model learning semantic QA relevance and distant supervision enables learning of syntactic features as well as the nuances of user querying language. Additionally, our model encodes queries and candidate responses independently allowing offline candidate embedding generation thereby minimizing the need for real-time transformer model execution. Consequently, our framework is able to scale to large e-commerce QA traffic. Extensive evaluation on user queries shows that our framework significantly outperforms both syntactic and semantic baselines in offline as well as large scale online A/B setups of a popular e-commerce service.
The Beauty of Capturing Faces: Rating the Quality of Digital Portraits
Jan 28, 2015

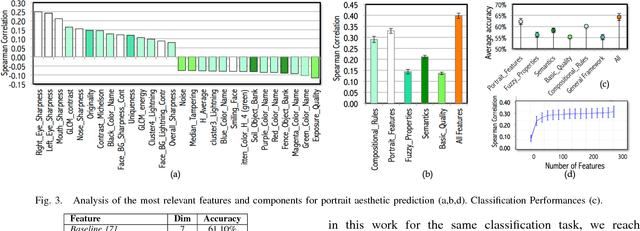

Digital portrait photographs are everywhere, and while the number of face pictures keeps growing, not much work has been done to on automatic portrait beauty assessment. In this paper, we design a specific framework to automatically evaluate the beauty of digital portraits. To this end, we procure a large dataset of face images annotated not only with aesthetic scores but also with information about the traits of the subject portrayed. We design a set of visual features based on portrait photography literature, and extensively analyze their relation with portrait beauty, exposing interesting findings about what makes a portrait beautiful. We find that the beauty of a portrait is linked to its artistic value, and independent from age, race and gender of the subject. We also show that a classifier trained with our features to separate beautiful portraits from non-beautiful portraits outperforms generic aesthetic classifiers.