 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaTeX-Numeric: Language-agnostic Text attribute eXtraction for E-commerce Numeric Attributes
Apr 23, 2021

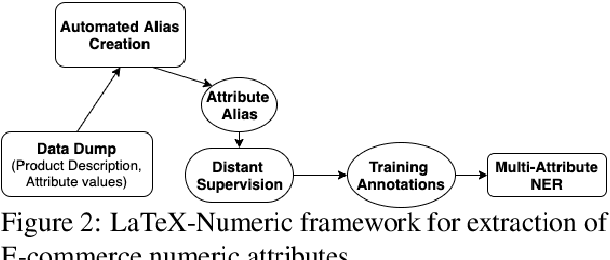

In this paper, we present LaTeX-Numeric - a high-precision fully-automated scalable framework for extracting E-commerce numeric attributes from product text like product description. Most of the past work on attribute extraction is not scalable as they rely on manually curated training data, either with or without the use of active learning. We rely on distant supervision for training data generation, removing dependency on manual labels. One issue with distant supervision is that it leads to incomplete training annotation due to missing attribute values while matching. We propose a multi-task learning architecture to deal with missing labels in the training data, leading to F1 improvement of 9.2% for numeric attributes over single-task architecture. While multi-task architecture benefits both numeric and non-numeric attributes, we present automated techniques to further improve the numeric attributes extraction models. Numeric attributes require a list of units (or aliases) for better matching with distant supervision. We propose an automated algorithm for alias creation using product text and attribute values, leading to a 20.2% F1 improvement. Extensive experiments on real world dataset for 20 numeric attributes across 5 product categories and 3 English marketplaces show that LaTeX-Numeric achieves a high F1-score, without any manual intervention, making it suitable for practical applications. Finally, we show that the improvements are language-agnostic and LaTeX-Numeric achieves 13.9% F1 improvement for 3 Romance languages.