 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Reference Need Assessment System for Wikipedia
Mar 17, 2026Wikipedia is a critical source of information for millions of users across the Web. It serves as a key resource for large language models, search engines, question-answering systems, and other Web-based applications. In Wikipedia, content needs to be verifiable, meaning that readers can check that claims are backed by references to reliable sources. This depends on manual verification by editors, an effective but labor-intensive process, especially given the high volume of daily edits. To address this challenge, we introduce a multilingual machine learning system to assist editors in identifying claims requiring citations. Our approach is tested in 10 language editions of Wikipedia, outperforming existing benchmarks for reference need assessment. We not only consider machine learning evaluation metrics but also system requirements, allowing us to explore the trade-offs between model accuracy and computational efficiency under real-world infrastructure constraints. We deploy our system in production and release data and code to support further research.
* Accepted for publication at the Proceedings of the ACM Web Conference 2026 (WWW '26). Author's copy
AToMiC: An Image/Text Retrieval Test Collection to Support Multimedia Content Creation
Apr 04, 2023



This paper presents the AToMiC (Authoring Tools for Multimedia Content) dataset, designed to advance research in image/text cross-modal retrieval. While vision-language pretrained transformers have led to significant improvements in retrieval effectiveness, existing research has relied on image-caption datasets that feature only simplistic image-text relationships and underspecified user models of retrieval tasks. To address the gap between these oversimplified settings and real-world applications for multimedia content creation, we introduce a new approach for building retrieval test collections. We leverage hierarchical structures and diverse domains of texts, styles, and types of images, as well as large-scale image-document associations embedded in Wikipedia. We formulate two tasks based on a realistic user model and validate our dataset through retrieval experiments using baseline models. AToMiC offers a testbed for scalable, diverse, and reproducible multimedia retrieval research. Finally, the dataset provides the basis for a dedicated track at the 2023 Text Retrieval Conference (TREC), and is publicly available at https://github.com/TREC-AToMiC/AToMiC.
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia
Jun 01, 2021
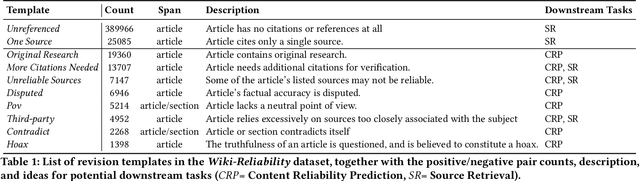
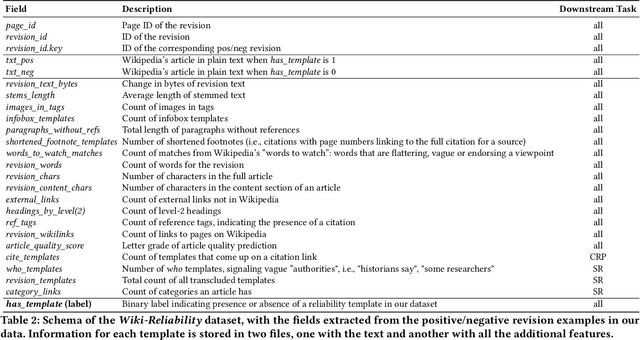
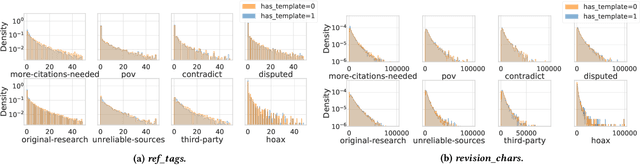
Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors' manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia "templates". Templates are tags used by expert Wikipedia editors to indicate content issues, such as the presence of "non-neutral point of view" or "contradictory articles", and serve as a strong signal for detecting reliability issues in a revision. We select the 10 most popular reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions as positive or negative with respect to each template. Each positive/negative example in the dataset comes with the full article text and 20 features from the revision's metadata. We provide an overview of the possible downstream tasks enabled by such data, and show that Wiki-Reliability can be used to train large-scale models for content reliability prediction. We release all data and code for public use.
Citation Needed: A Taxonomy and Algorithmic Assessment of Wikipedia's Verifiability
Feb 28, 2019
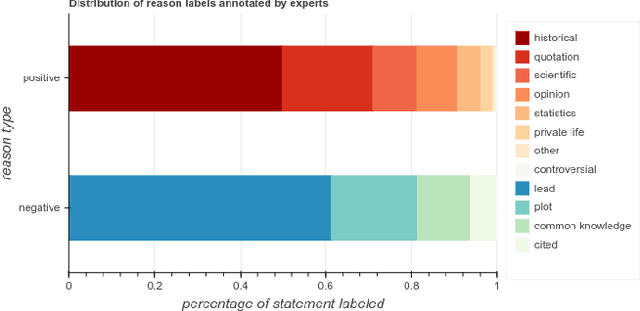


Wikipedia is playing an increasingly central role on the web,and the policies its contributors follow when sourcing and fact-checking content affect million of readers. Among these core guiding principles, verifiability policies have a particularly important role. Verifiability requires that information included in a Wikipedia article be corroborated against reliable secondary sources. Because of the manual labor needed to curate and fact-check Wikipedia at scale, however, its contents do not always evenly comply with these policies. Citations (i.e. reference to external sources) may not conform to verifiability requirements or may be missing altogether, potentially weakening the reliability of specific topic areas of the free encyclopedia. In this paper, we aim to provide an empirical characterization of the reasons why and how Wikipedia cites external sources to comply with its own verifiability guidelines. First, we construct a taxonomy of reasons why inline citations are required by collecting labeled data from editors of multiple Wikipedia language editions. We then collect a large-scale crowdsourced dataset of Wikipedia sentences annotated with categories derived from this taxonomy. Finally, we design and evaluate algorithmic models to determine if a statement requires a citation, and to predict the citation reason based on our taxonomy. We evaluate the robustness of such models across different classes of Wikipedia articles of varying quality, as well as on an additional dataset of claims annotated for fact-checking purposes.
Beautiful and damned. Combined effect of content quality and social ties on user engagement
Nov 01, 2017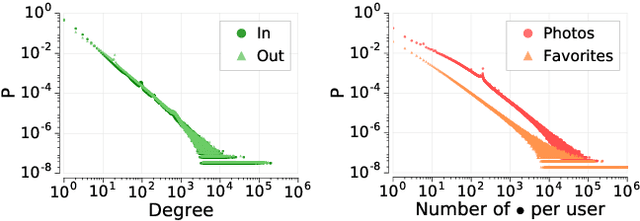
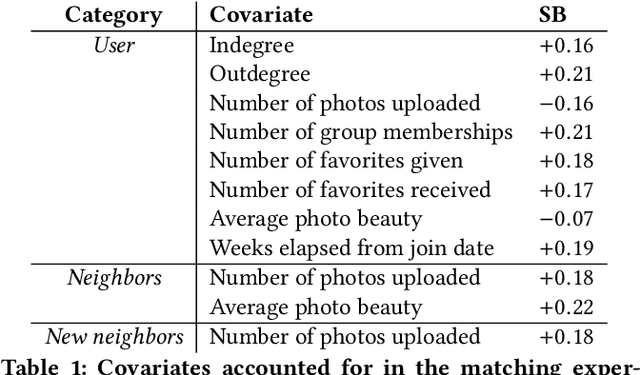
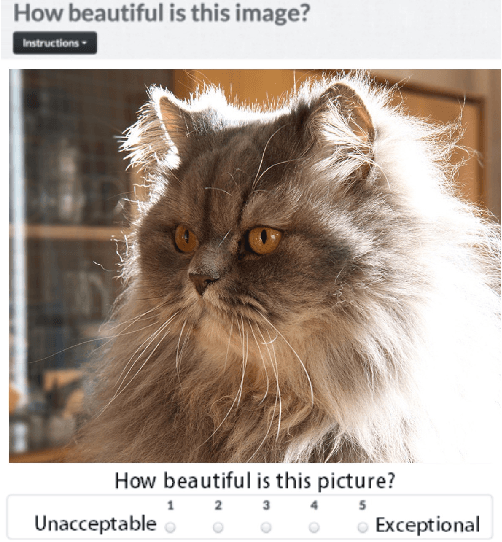
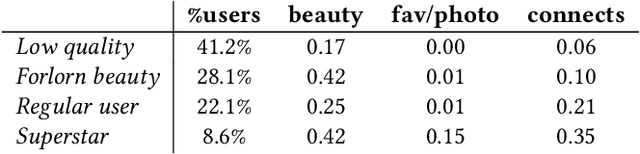
User participation in online communities is driven by the intertwinement of the social network structure with the crowd-generated content that flows along its links. These aspects are rarely explored jointly and at scale. By looking at how users generate and access pictures of varying beauty on Flickr, we investigate how the production of quality impacts the dynamics of online social systems. We develop a deep learning computer vision model to score images according to their aesthetic value and we validate its output through crowdsourcing. By applying it to over 15B Flickr photos, we study for the first time how image beauty is distributed over a large-scale social system. Beautiful images are evenly distributed in the network, although only a small core of people get social recognition for them. To study the impact of exposure to quality on user engagement, we set up matching experiments aimed at detecting causality from observational data. Exposure to beauty is double-edged: following people who produce high-quality content increases one's probability of uploading better photos; however, an excessive imbalance between the quality generated by a user and the user's neighbors leads to a decline in engagement. Our analysis has practical implications for improving link recommender systems.
Multilingual Visual Sentiment Concept Matching
Jun 07, 2016
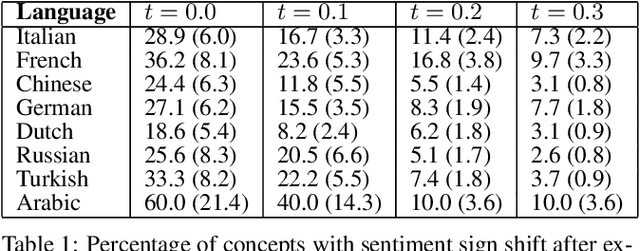
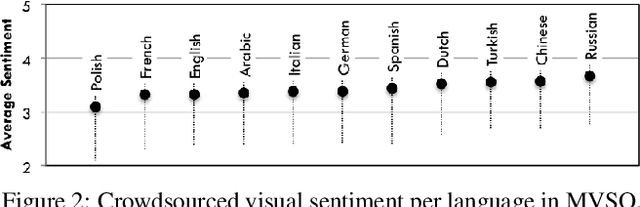
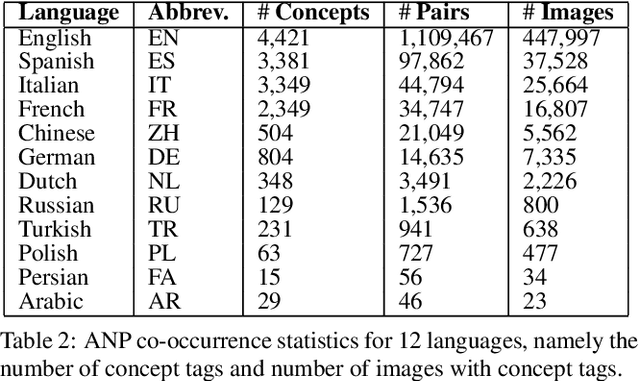
The impact of culture in visual emotion perception has recently captured the attention of multimedia research. In this study, we pro- vide powerful computational linguistics tools to explore, retrieve and browse a dataset of 16K multilingual affective visual concepts and 7.3M Flickr images. First, we design an effective crowdsourc- ing experiment to collect human judgements of sentiment connected to the visual concepts. We then use word embeddings to repre- sent these concepts in a low dimensional vector space, allowing us to expand the meaning around concepts, and thus enabling insight about commonalities and differences among different languages. We compare a variety of concept representations through a novel evaluation task based on the notion of visual semantic relatedness. Based on these representations, we design clustering schemes to group multilingual visual concepts, and evaluate them with novel metrics based on the crowdsourced sentiment annotations as well as visual semantic relatedness. The proposed clustering framework enables us to analyze the full multilingual dataset in-depth and also show an application on a facial data subset, exploring cultural in- sights of portrait-related affective visual concepts.
Visual Affect Around the World: A Large-scale Multilingual Visual Sentiment Ontology
Oct 07, 2015

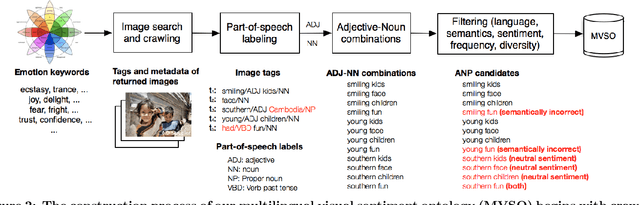
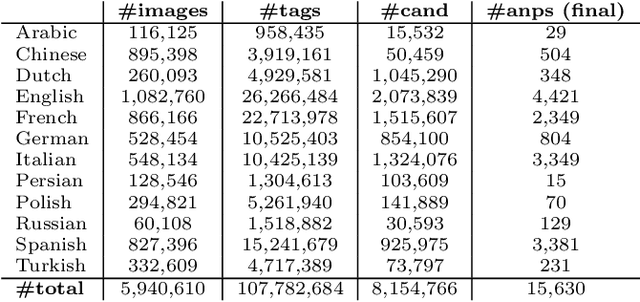
Every culture and language is unique. Our work expressly focuses on the uniqueness of culture and language in relation to human affect, specifically sentiment and emotion semantics, and how they manifest in social multimedia. We develop sets of sentiment- and emotion-polarized visual concepts by adapting semantic structures called adjective-noun pairs, originally introduced by Borth et al. (2013), but in a multilingual context. We propose a new language-dependent method for automatic discovery of these adjective-noun constructs. We show how this pipeline can be applied on a social multimedia platform for the creation of a large-scale multilingual visual sentiment concept ontology (MVSO). Unlike the flat structure in Borth et al. (2013), our unified ontology is organized hierarchically by multilingual clusters of visually detectable nouns and subclusters of emotionally biased versions of these nouns. In addition, we present an image-based prediction task to show how generalizable language-specific models are in a multilingual context. A new, publicly available dataset of >15.6K sentiment-biased visual concepts across 12 languages with language-specific detector banks, >7.36M images and their metadata is also released.
Like Partying? Your Face Says It All. Predicting the Ambiance of Places with Profile Pictures
May 28, 2015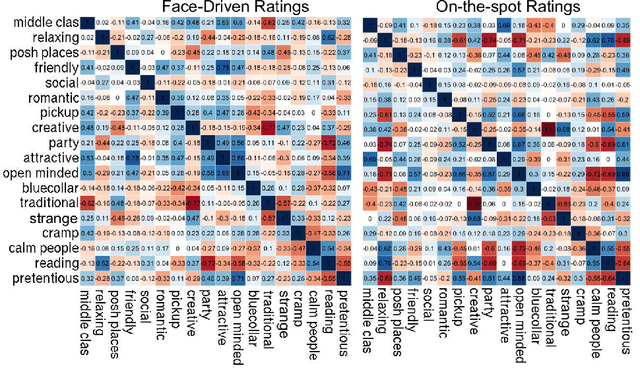
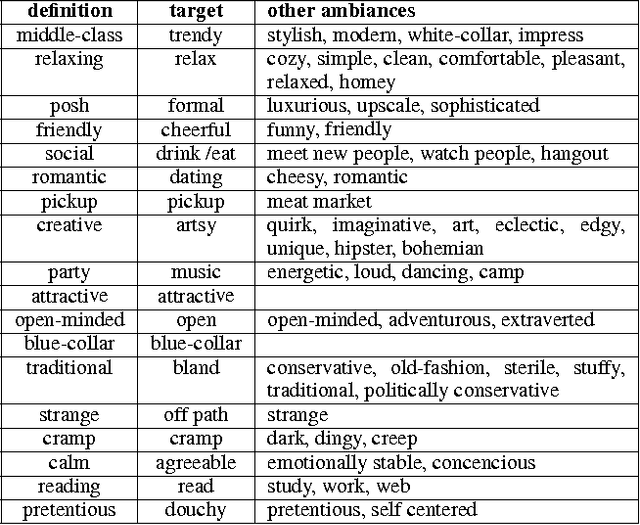

To choose restaurants and coffee shops, people are increasingly relying on social-networking sites. In a popular site such as Foursquare or Yelp, a place comes with descriptions and reviews, and with profile pictures of people who frequent them. Descriptions and reviews have been widely explored in the research area of data mining. By contrast, profile pictures have received little attention. Previous work showed that people are able to partly guess a place's ambiance, clientele, and activities not only by observing the place itself but also by observing the profile pictures of its visitors. Here we further that work by determining which visual cues people may have relied upon to make their guesses; showing that a state-of-the-art algorithm could make predictions more accurately than humans at times; and demonstrating that the visual cues people relied upon partly differ from those of the algorithm.
An Image is Worth More than a Thousand Favorites: Surfacing the Hidden Beauty of Flickr Pictures
May 15, 2015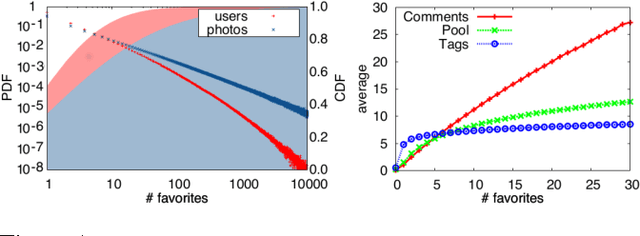


The dynamics of attention in social media tend to obey power laws. Attention concentrates on a relatively small number of popular items and neglecting the vast majority of content produced by the crowd. Although popularity can be an indication of the perceived value of an item within its community, previous research has hinted to the fact that popularity is distinct from intrinsic quality. As a result, content with low visibility but high quality lurks in the tail of the popularity distribution. This phenomenon can be particularly evident in the case of photo-sharing communities, where valuable photographers who are not highly engaged in online social interactions contribute with high-quality pictures that remain unseen. We propose to use a computer vision method to surface beautiful pictures from the immense pool of near-zero-popularity items, and we test it on a large dataset of creative-commons photos on Flickr. By gathering a large crowdsourced ground truth of aesthetics scores for Flickr images, we show that our method retrieves photos whose median perceived beauty score is equal to the most popular ones, and whose average is lower by only 1.5%.
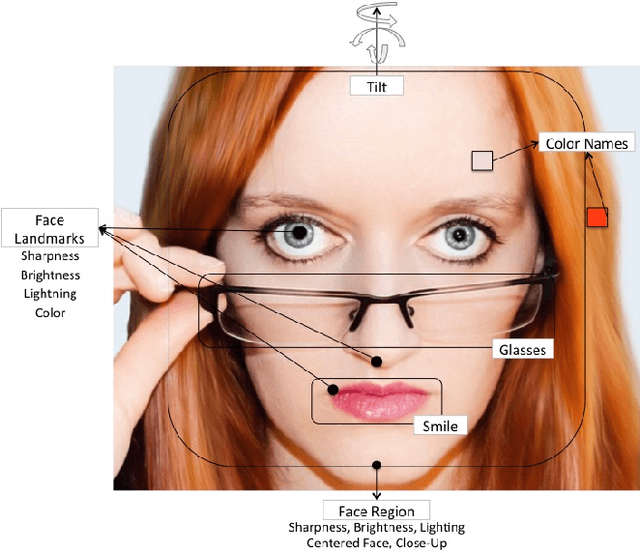
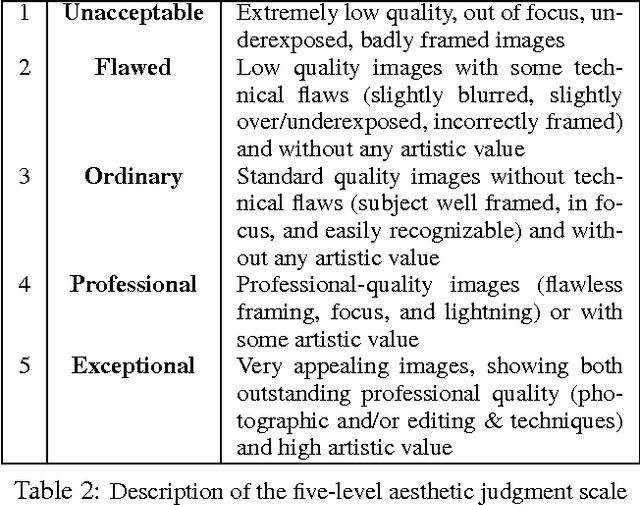
The Beauty of Capturing Faces: Rating the Quality of Digital Portraits
Jan 28, 2015

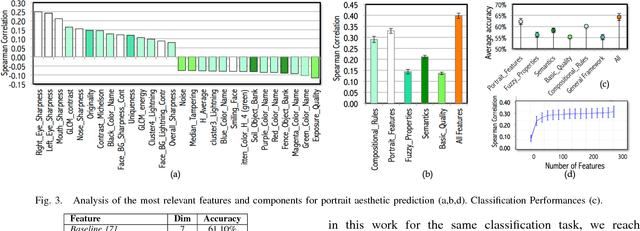

Digital portrait photographs are everywhere, and while the number of face pictures keeps growing, not much work has been done to on automatic portrait beauty assessment. In this paper, we design a specific framework to automatically evaluate the beauty of digital portraits. To this end, we procure a large dataset of face images annotated not only with aesthetic scores but also with information about the traits of the subject portrayed. We design a set of visual features based on portrait photography literature, and extensively analyze their relation with portrait beauty, exposing interesting findings about what makes a portrait beautiful. We find that the beauty of a portrait is linked to its artistic value, and independent from age, race and gender of the subject. We also show that a classifier trained with our features to separate beautiful portraits from non-beautiful portraits outperforms generic aesthetic classifiers.