 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Challenges of the Space Environment for Onboard Artificial Intelligence: Design Overview of the Imaging Payload on SpIRIT
Apr 12, 2024



Artificial intelligence (AI) and autonomous edge computing in space are emerging areas of interest to augment capabilities of nanosatellites, where modern sensors generate orders of magnitude more data than can typically be transmitted to mission control. Here, we present the hardware and software design of an onboard AI subsystem hosted on SpIRIT. The system is optimised for on-board computer vision experiments based on visible light and long wave infrared cameras. This paper highlights the key design choices made to maximise the robustness of the system in harsh space conditions, and their motivation relative to key mission requirements, such as limited compute resources, resilience to cosmic radiation, extreme temperature variations, distribution shifts, and very low transmission bandwidths. The payload, called Loris, consists of six visible light cameras, three infrared cameras, a camera control board and a Graphics Processing Unit (GPU) system-on-module. Loris enables the execution of AI models with on-orbit fine-tuning as well as a next-generation image compression algorithm, including progressive coding. This innovative approach not only enhances the data processing capabilities of nanosatellites but also lays the groundwork for broader applications to remote sensing from space.
Citation Needed: A Taxonomy and Algorithmic Assessment of Wikipedia's Verifiability
Feb 28, 2019
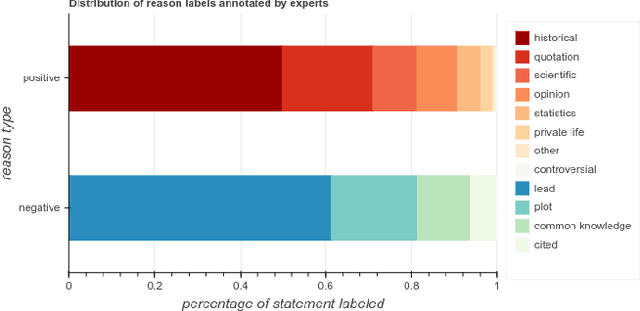


Wikipedia is playing an increasingly central role on the web,and the policies its contributors follow when sourcing and fact-checking content affect million of readers. Among these core guiding principles, verifiability policies have a particularly important role. Verifiability requires that information included in a Wikipedia article be corroborated against reliable secondary sources. Because of the manual labor needed to curate and fact-check Wikipedia at scale, however, its contents do not always evenly comply with these policies. Citations (i.e. reference to external sources) may not conform to verifiability requirements or may be missing altogether, potentially weakening the reliability of specific topic areas of the free encyclopedia. In this paper, we aim to provide an empirical characterization of the reasons why and how Wikipedia cites external sources to comply with its own verifiability guidelines. First, we construct a taxonomy of reasons why inline citations are required by collecting labeled data from editors of multiple Wikipedia language editions. We then collect a large-scale crowdsourced dataset of Wikipedia sentences annotated with categories derived from this taxonomy. Finally, we design and evaluate algorithmic models to determine if a statement requires a citation, and to predict the citation reason based on our taxonomy. We evaluate the robustness of such models across different classes of Wikipedia articles of varying quality, as well as on an additional dataset of claims annotated for fact-checking purposes.