 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCitation Needed: A Taxonomy and Algorithmic Assessment of Wikipedia's Verifiability
Feb 28, 2019
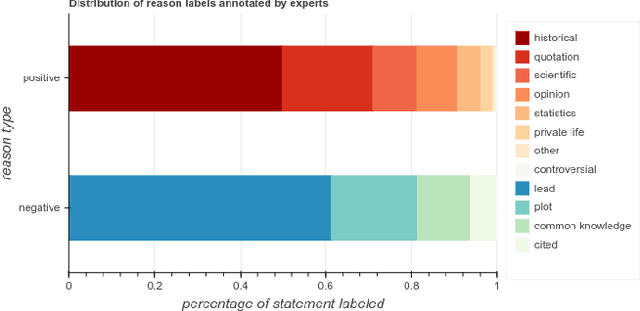


Wikipedia is playing an increasingly central role on the web,and the policies its contributors follow when sourcing and fact-checking content affect million of readers. Among these core guiding principles, verifiability policies have a particularly important role. Verifiability requires that information included in a Wikipedia article be corroborated against reliable secondary sources. Because of the manual labor needed to curate and fact-check Wikipedia at scale, however, its contents do not always evenly comply with these policies. Citations (i.e. reference to external sources) may not conform to verifiability requirements or may be missing altogether, potentially weakening the reliability of specific topic areas of the free encyclopedia. In this paper, we aim to provide an empirical characterization of the reasons why and how Wikipedia cites external sources to comply with its own verifiability guidelines. First, we construct a taxonomy of reasons why inline citations are required by collecting labeled data from editors of multiple Wikipedia language editions. We then collect a large-scale crowdsourced dataset of Wikipedia sentences annotated with categories derived from this taxonomy. Finally, we design and evaluate algorithmic models to determine if a statement requires a citation, and to predict the citation reason based on our taxonomy. We evaluate the robustness of such models across different classes of Wikipedia articles of varying quality, as well as on an additional dataset of claims annotated for fact-checking purposes.
WikiConv: A Corpus of the Complete Conversational History of a Large Online Collaborative Community
Oct 31, 2018
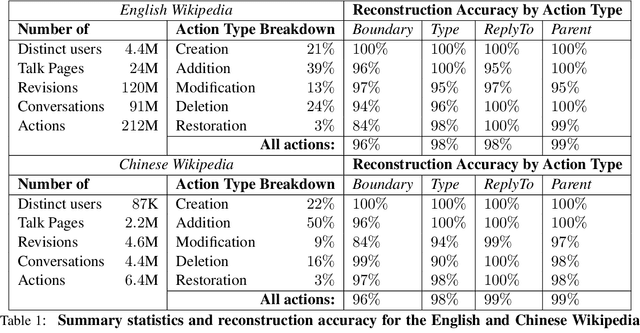

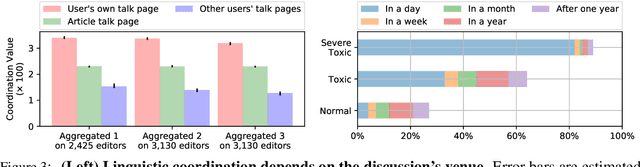
We present a corpus that encompasses the complete history of conversations between contributors to Wikipedia, one of the largest online collaborative communities. By recording the intermediate states of conversations---including not only comments and replies, but also their modifications, deletions and restorations---this data offers an unprecedented view of online conversation. This level of detail supports new research questions pertaining to the process (and challenges) of large-scale online collaboration. We illustrate the corpus' potential with two case studies that highlight new perspectives on earlier work. First, we explore how a person's conversational behavior depends on how they relate to the discussion's venue. Second, we show that community moderation of toxic behavior happens at a higher rate than previously estimated. Finally the reconstruction framework is designed to be language agnostic, and we show that it can extract high quality conversational data in both Chinese and English.
Conversations Gone Awry: Detecting Early Signs of Conversational Failure
May 14, 2018

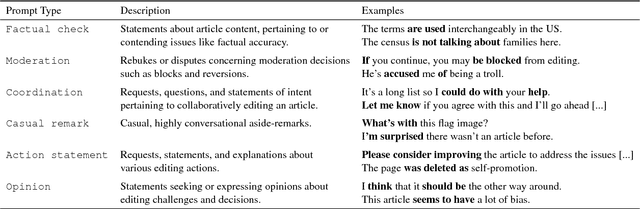
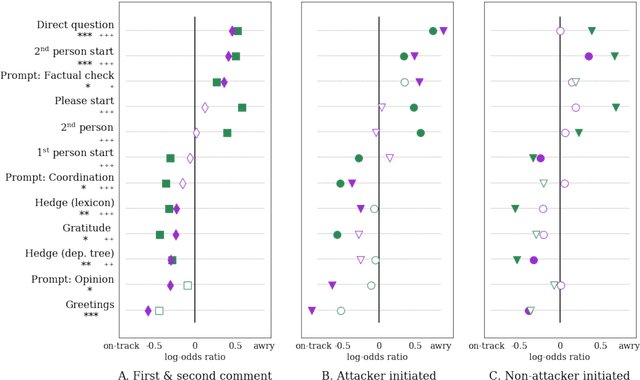
One of the main challenges online social systems face is the prevalence of antisocial behavior, such as harassment and personal attacks. In this work, we introduce the task of predicting from the very start of a conversation whether it will get out of hand. As opposed to detecting undesirable behavior after the fact, this task aims to enable early, actionable prediction at a time when the conversation might still be salvaged. To this end, we develop a framework for capturing pragmatic devices---such as politeness strategies and rhetorical prompts---used to start a conversation, and analyze their relation to its future trajectory. Applying this framework in a controlled setting, we demonstrate the feasibility of detecting early warning signs of antisocial behavior in online discussions.