 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Challenges of the Space Environment for Onboard Artificial Intelligence: Design Overview of the Imaging Payload on SpIRIT
Apr 12, 2024



Artificial intelligence (AI) and autonomous edge computing in space are emerging areas of interest to augment capabilities of nanosatellites, where modern sensors generate orders of magnitude more data than can typically be transmitted to mission control. Here, we present the hardware and software design of an onboard AI subsystem hosted on SpIRIT. The system is optimised for on-board computer vision experiments based on visible light and long wave infrared cameras. This paper highlights the key design choices made to maximise the robustness of the system in harsh space conditions, and their motivation relative to key mission requirements, such as limited compute resources, resilience to cosmic radiation, extreme temperature variations, distribution shifts, and very low transmission bandwidths. The payload, called Loris, consists of six visible light cameras, three infrared cameras, a camera control board and a Graphics Processing Unit (GPU) system-on-module. Loris enables the execution of AI models with on-orbit fine-tuning as well as a next-generation image compression algorithm, including progressive coding. This innovative approach not only enhances the data processing capabilities of nanosatellites but also lays the groundwork for broader applications to remote sensing from space.
Leveraging Equivariant Features for Absolute Pose Regression
Apr 05, 2022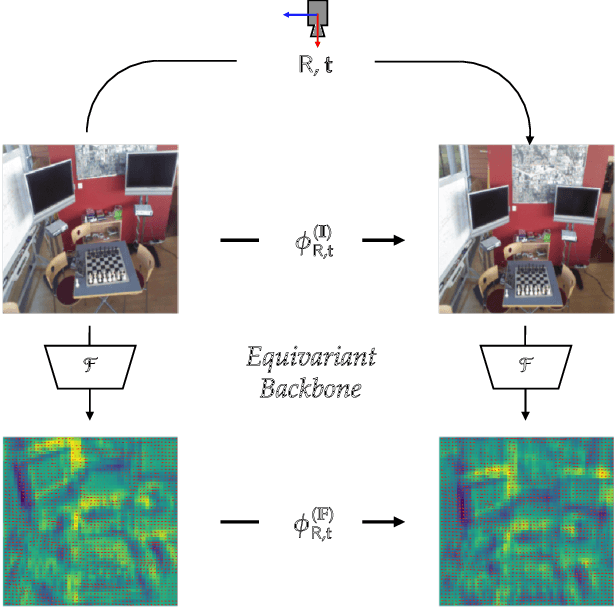
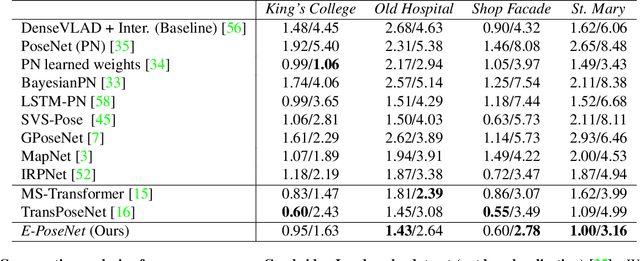
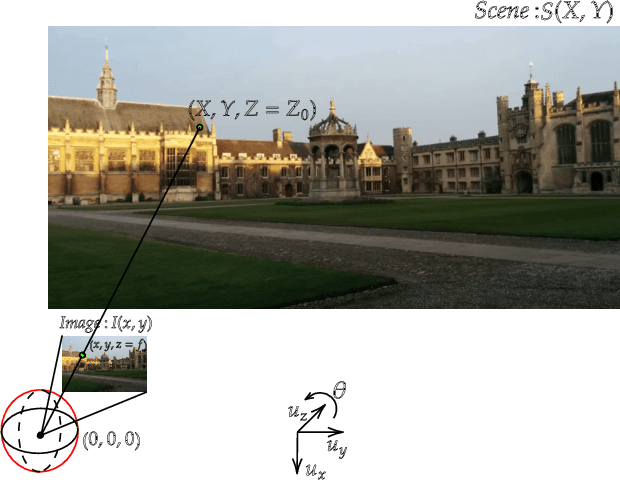
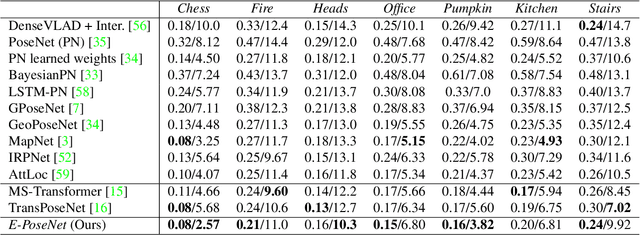
While end-to-end approaches have achieved state-of-the-art performance in many perception tasks, they are not yet able to compete with 3D geometry-based methods in pose estimation. Moreover, absolute pose regression has been shown to be more related to image retrieval. As a result, we hypothesize that the statistical features learned by classical Convolutional Neural Networks do not carry enough geometric information to reliably solve this inherently geometric task. In this paper, we demonstrate how a translation and rotation equivariant Convolutional Neural Network directly induces representations of camera motions into the feature space. We then show that this geometric property allows for implicitly augmenting the training data under a whole group of image plane-preserving transformations. Therefore, we argue that directly learning equivariant features is preferable than learning data-intensive intermediate representations. Comprehensive experimental validation demonstrates that our lightweight model outperforms existing ones on standard datasets.