 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace Debris: Are Deep Learning-based Image Enhancements part of the Solution?
Aug 01, 2023

The volume of space debris currently orbiting the Earth is reaching an unsustainable level at an accelerated pace. The detection, tracking, identification, and differentiation between orbit-defined, registered spacecraft, and rogue/inactive space ``objects'', is critical to asset protection. The primary objective of this work is to investigate the validity of Deep Neural Network (DNN) solutions to overcome the limitations and image artefacts most prevalent when captured with monocular cameras in the visible light spectrum. In this work, a hybrid UNet-ResNet34 Deep Learning (DL) architecture pre-trained on the ImageNet dataset, is developed. Image degradations addressed include blurring, exposure issues, poor contrast, and noise. The shortage of space-generated data suitable for supervised DL is also addressed. A visual comparison between the URes34P model developed in this work and the existing state of the art in deep learning image enhancement methods, relevant to images captured in space, is presented. Based upon visual inspection, it is determined that our UNet model is capable of correcting for space-related image degradations and merits further investigation to reduce its computational complexity.
Self-Supervised Learning for Place Representation Generalization across Appearance Changes
Mar 09, 2023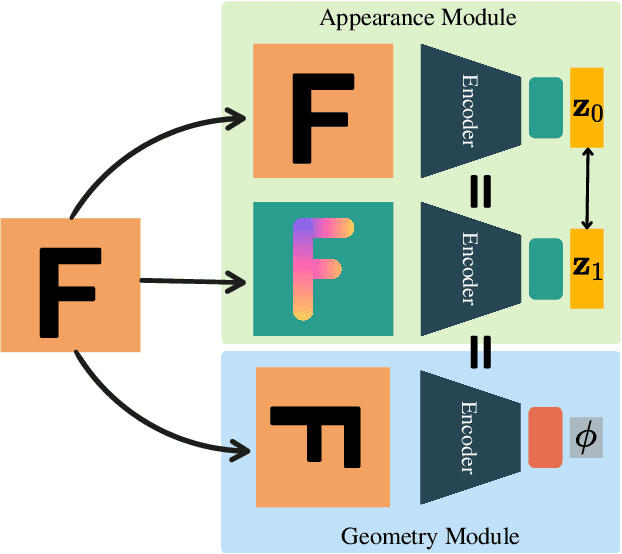
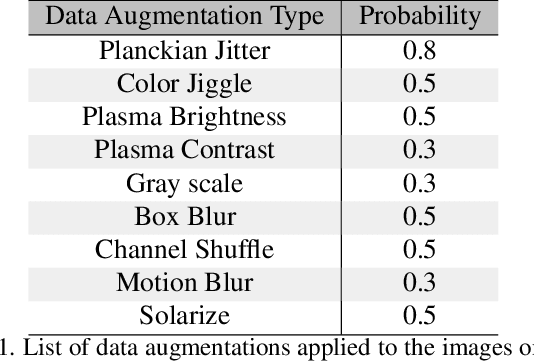

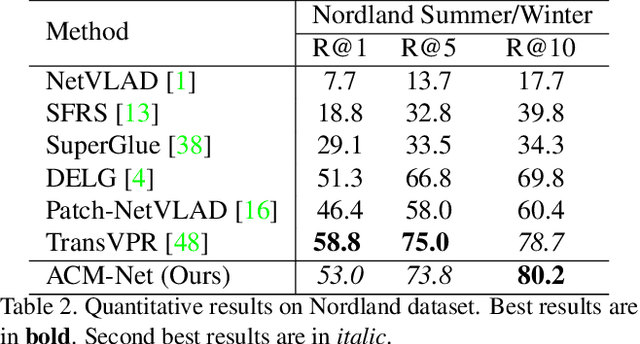
Visual place recognition is a key to unlocking spatial navigation for animals, humans and robots. While state-of-the-art approaches are trained in a supervised manner and therefore hardly capture the information needed for generalizing to unusual conditions, we argue that self-supervised learning may help abstracting the place representation so that it can be foreseen, irrespective of the conditions. More precisely, in this paper, we investigate learning features that are robust to appearance modifications while sensitive to geometric transformations in a self-supervised manner. This dual-purpose training is made possible by combining the two self-supervision main paradigms, \textit{i.e.} contrastive and predictive learning. Our results on standard benchmarks reveal that jointly learning such appearance-robust and geometry-sensitive image descriptors leads to competitive visual place recognition results across adverse seasonal and illumination conditions, without requiring any human-annotated labels.
3D-Aware Object Localization using Gaussian Implicit Occupancy Function
Mar 03, 2023



To automatically localize a target object in an image is crucial for many computer vision applications. Recently ellipse representations have been identified as an alternative to axis-aligned bounding boxes for object localization. This paper considers 3D-aware ellipse labels, i.e., which are projections of a 3D ellipsoidal approximation of the object in the images for 2D target localization. Such generic ellipsoidal models allow for handling coarsely known targets, and 3D-aware ellipse detections carry more geometric information about the object than traditional 3D-agnostic bounding box labels. We propose to have a new look at ellipse regression and replace the geometric ellipse parameters with the parameters of an implicit Gaussian distribution encoding object occupancy in the image. The models are trained to regress the values of this bivariate Gaussian distribution over the image pixels using a continuous statistical loss function. We introduce a novel non-trainable differentiable layer, E-DSNT, to extract the distribution parameters. Also, we describe how to readily generate consistent 3D-aware Gaussian occupancy parameters using only coarse dimensions of the target and relative pose labels. We extend three existing spacecraft pose estimation datasets with 3D-aware Gaussian occupancy labels to validate our hypothesis.
Leveraging Equivariant Features for Absolute Pose Regression
Apr 05, 2022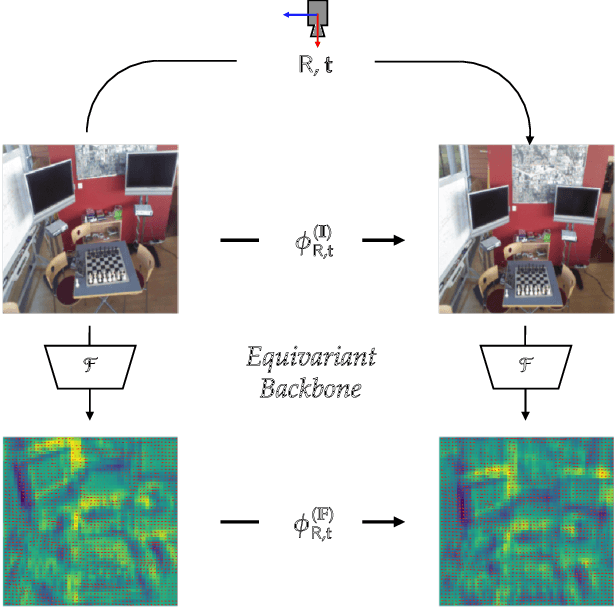
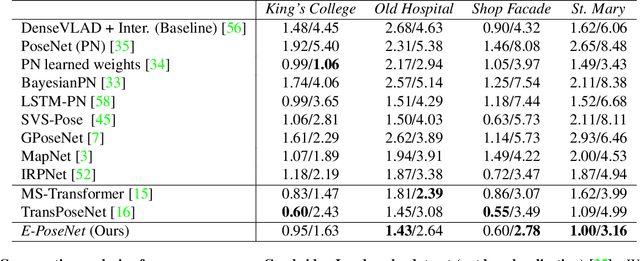
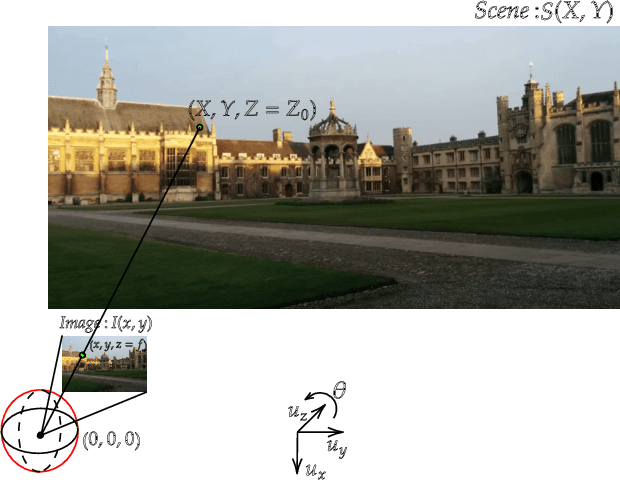
While end-to-end approaches have achieved state-of-the-art performance in many perception tasks, they are not yet able to compete with 3D geometry-based methods in pose estimation. Moreover, absolute pose regression has been shown to be more related to image retrieval. As a result, we hypothesize that the statistical features learned by classical Convolutional Neural Networks do not carry enough geometric information to reliably solve this inherently geometric task. In this paper, we demonstrate how a translation and rotation equivariant Convolutional Neural Network directly induces representations of camera motions into the feature space. We then show that this geometric property allows for implicitly augmenting the training data under a whole group of image plane-preserving transformations. Therefore, we argue that directly learning equivariant features is preferable than learning data-intensive intermediate representations. Comprehensive experimental validation demonstrates that our lightweight model outperforms existing ones on standard datasets.
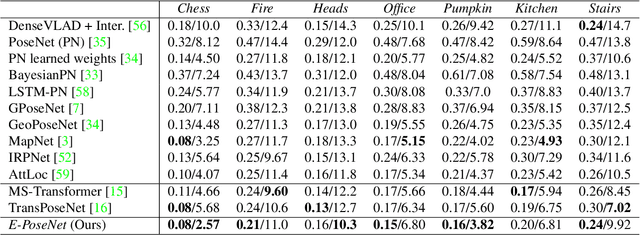
LSPnet: A 2D Localization-oriented Spacecraft Pose Estimation Neural Network
Apr 19, 2021
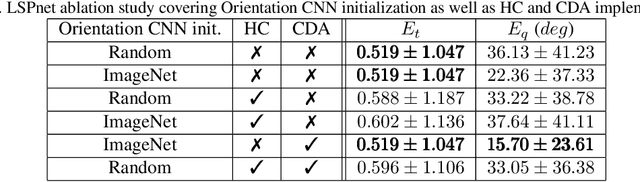
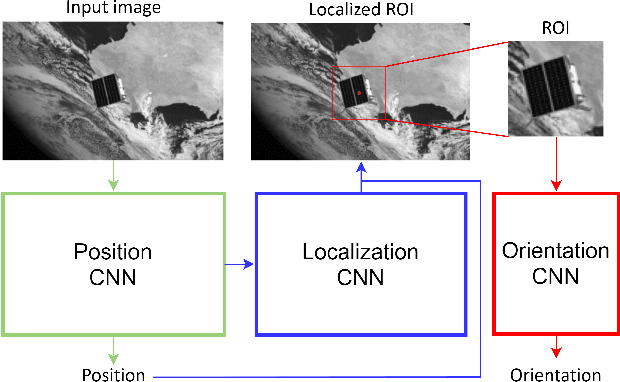
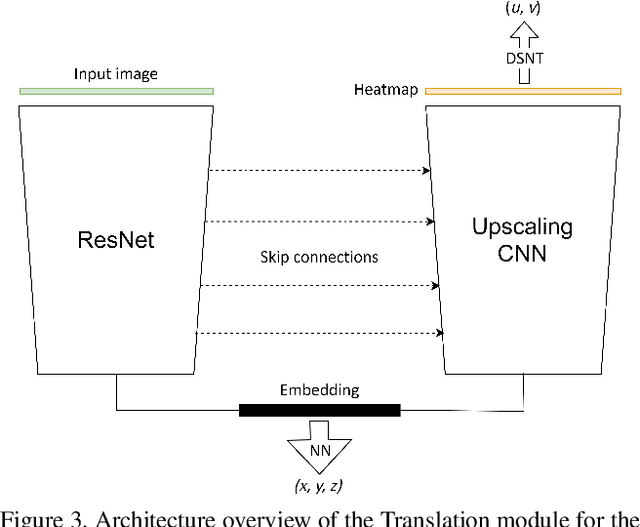
Being capable of estimating the pose of uncooperative objects in space has been proposed as a key asset for enabling safe close-proximity operations such as space rendezvous, in-orbit servicing and active debris removal. Usual approaches for pose estimation involve classical computer vision-based solutions or the application of Deep Learning (DL) techniques. This work explores a novel DL-based methodology, using Convolutional Neural Networks (CNNs), for estimating the pose of uncooperative spacecrafts. Contrary to other approaches, the proposed CNN directly regresses poses without needing any prior 3D information. Moreover, bounding boxes of the spacecraft in the image are predicted in a simple, yet efficient manner. The performed experiments show how this work competes with the state-of-the-art in uncooperative spacecraft pose estimation, including works which require 3D information as well as works which predict bounding boxes through sophisticated CNNs.
SPARK: SPAcecraft Recognition leveraging Knowledge of Space Environment
Apr 14, 2021
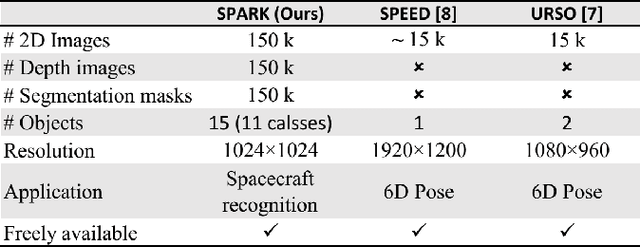
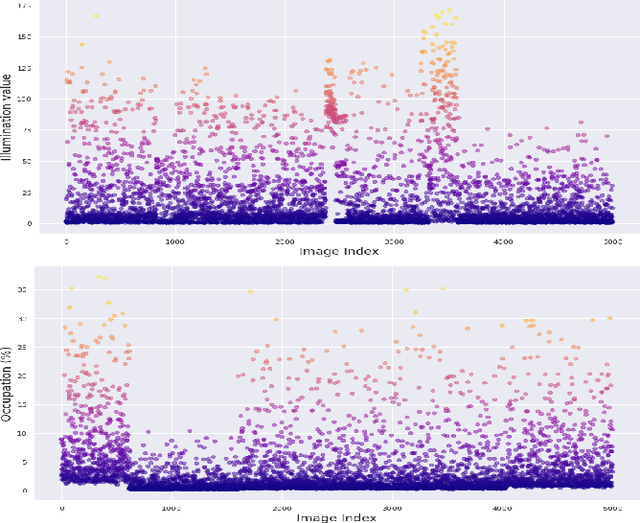
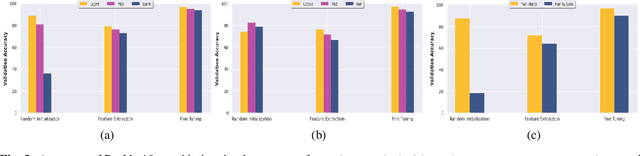
This paper proposes the SPARK dataset as a new unique space object multi-modal image dataset. Image-based object recognition is an important component of Space Situational Awareness, especially for applications such as on-orbit servicing, active debris removal, and satellite formation. However, the lack of sufficient annotated space data has limited research efforts in developing data-driven spacecraft recognition approaches. The SPARK dataset has been generated under a realistic space simulation environment, with a large diversity in sensing conditions for different orbital scenarios. It provides about 150k images per modality, RGB and depth, and 11 classes for spacecrafts and debris. This dataset offers an opportunity to benchmark and further develop object recognition, classification and detection algorithms, as well as multi-modal RGB-Depth approaches under space sensing conditions. Preliminary experimental evaluation validates the relevance of the data, and highlights interesting challenging scenarios specific to the space environment.