 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTALON: Token-Aligned Lightweight Adapters for 6-DoF Spacecraft Pose Estimation
May 29, 2026Monocular 6-DoF spacecraft pose estimation methods predominantly process individual frames, discarding the temporal information present in an image sequence acquired during spacecraft manoeuvres. Few temporal approaches require full backbone fine-tuning or auxiliary optical flow networks, risking catastrophic forgetting or increasing computational cost, respectively. We propose TALON (Token-Aligned Lightweight adapters for Orbital Navigation): spatiotemporal 3D adapters injected before the self-attention layers of a frozen ViT vision transformer, combined with a patch-token alignment loss that geometrically grounds the adapted features to keypoint structure through a prototype-conditioned KL-divergence objective. Pre-attention placement allows the frozen attention to reason over temporally enriched tokens, achieving stronger performance with a single adapter per block than post-attention alternatives. The alignment loss shapes the intermediate representations so that each keypoint induces a spatially precise activation in the token field, while the framework adds less than 5% parameters to the frozen backbone. On SPADES dataset, TALON reduces the pose error by 50% over the prior state-of-the-art, and on SwissCube dataset it surpasses the prior best by 21.8% in ADD-0.1d accuracy. Zero-shot cross-domain evaluation from sim-to-real on SPARK real data reduces pose error by 4.7x, and ablations characterise the role of adapter depth across in-domain and cross-domain settings.
Efficient Onboard Spacecraft Pose Estimation with Event Cameras and Neuromorphic Hardware
Apr 05, 2026Reliable relative pose estimation is a key enabler for autonomous rendezvous and proximity operations, yet space imagery is notoriously challenging due to extreme illumination, high contrast, and fast target motion. Event cameras provide asynchronous, change-driven measurements that can remain informative when frame-based imagery saturates or blurs, while neuromorphic processors can exploit sparse activations for low-latency, energy-efficient inferences. This paper presents a spacecraft 6-DoF pose-estimation pipeline that couples event-based vision with the BrainChip Akida neuromorphic processor. Using the SPADES dataset, we train compact MobileNet-style keypoint regression networks on lightweight event-frame representations, apply quantization-aware training (8/4-bit), and convert the models to Akida-compatible spiking neural networks. We benchmark three event representations and demonstrate real-time, low-power inference on Akida V1 hardware. We additionally design a heatmap-based model targeting Akida V2 and evaluate it on Akida Cloud, yielding improved pose accuracy. To our knowledge, this is the first end-to-end demonstration of spacecraft pose estimation running on Akida hardware, highlighting a practical route to low-latency, low-power perception for future autonomous space missions.
Annotation Free Spacecraft Detection and Segmentation using Vision Language Models
Feb 04, 2026Vision Language Models (VLMs) have demonstrated remarkable performance in open-world zero-shot visual recognition. However, their potential in space-related applications remains largely unexplored. In the space domain, accurate manual annotation is particularly challenging due to factors such as low visibility, illumination variations, and object blending with planetary backgrounds. Developing methods that can detect and segment spacecraft and orbital targets without requiring extensive manual labeling is therefore of critical importance. In this work, we propose an annotation-free detection and segmentation pipeline for space targets using VLMs. Our approach begins by automatically generating pseudo-labels for a small subset of unlabeled real data with a pre-trained VLM. These pseudo-labels are then leveraged in a teacher-student label distillation framework to train lightweight models. Despite the inherent noise in the pseudo-labels, the distillation process leads to substantial performance gains over direct zero-shot VLM inference. Experimental evaluations on the SPARK-2024, SPEED+, and TANGO datasets on segmentation tasks demonstrate consistent improvements in average precision (AP) by up to 10 points. Code and models are available at https://github.com/giddyyupp/annotation-free-spacecraft-segmentation.
Hybrid Attention for Robust RGB-T Pedestrian Detection in Real-World Conditions
Nov 06, 2024



Multispectral pedestrian detection has gained significant attention in recent years, particularly in autonomous driving applications. To address the challenges posed by adversarial illumination conditions, the combination of thermal and visible images has demonstrated its advantages. However, existing fusion methods rely on the critical assumption that the RGB-Thermal (RGB-T) image pairs are fully overlapping. These assumptions often do not hold in real-world applications, where only partial overlap between images can occur due to sensors configuration. Moreover, sensor failure can cause loss of information in one modality. In this paper, we propose a novel module called the Hybrid Attention (HA) mechanism as our main contribution to mitigate performance degradation caused by partial overlap and sensor failure, i.e. when at least part of the scene is acquired by only one sensor. We propose an improved RGB-T fusion algorithm, robust against partial overlap and sensor failure encountered during inference in real-world applications. We also leverage a mobile-friendly backbone to cope with resource constraints in embedded systems. We conducted experiments by simulating various partial overlap and sensor failure scenarios to evaluate the performance of our proposed method. The results demonstrate that our approach outperforms state-of-the-art methods, showcasing its superiority in handling real-world challenges.
SPADES: A Realistic Spacecraft Pose Estimation Dataset using Event Sensing
Nov 09, 2023



In recent years, there has been a growing demand for improved autonomy for in-orbit operations such as rendezvous, docking, and proximity maneuvers, leading to increased interest in employing Deep Learning-based Spacecraft Pose Estimation techniques. However, due to limited access to real target datasets, algorithms are often trained using synthetic data and applied in the real domain, resulting in a performance drop due to the domain gap. State-of-the-art approaches employ Domain Adaptation techniques to mitigate this issue. In the search for viable solutions, event sensing has been explored in the past and shown to reduce the domain gap between simulations and real-world scenarios. Event sensors have made significant advancements in hardware and software in recent years. Moreover, the characteristics of the event sensor offer several advantages in space applications compared to RGB sensors. To facilitate further training and evaluation of DL-based models, we introduce a novel dataset, SPADES, comprising real event data acquired in a controlled laboratory environment and simulated event data using the same camera intrinsics. Furthermore, we propose an effective data filtering method to improve the quality of training data, thus enhancing model performance. Additionally, we introduce an image-based event representation that outperforms existing representations. A multifaceted baseline evaluation was conducted using different event representations, event filtering strategies, and algorithmic frameworks, and the results are summarized. The dataset will be made available at http://cvi2.uni.lu/spades.
A Survey on Deep Learning-Based Monocular Spacecraft Pose Estimation: Current State, Limitations and Prospects
May 17, 2023



Estimating the pose of an uncooperative spacecraft is an important computer vision problem for enabling the deployment of automatic vision-based systems in orbit, with applications ranging from on-orbit servicing to space debris removal. Following the general trend in computer vision, more and more works have been focusing on leveraging Deep Learning (DL) methods to address this problem. However and despite promising research-stage results, major challenges preventing the use of such methods in real-life missions still stand in the way. In particular, the deployment of such computation-intensive algorithms is still under-investigated, while the performance drop when training on synthetic and testing on real images remains to mitigate. The primary goal of this survey is to describe the current DL-based methods for spacecraft pose estimation in a comprehensive manner. The secondary goal is to help define the limitations towards the effective deployment of DL-based spacecraft pose estimation solutions for reliable autonomous vision-based applications. To this end, the survey first summarises the existing algorithms according to two approaches: hybrid modular pipelines and direct end-to-end regression methods. A comparison of algorithms is presented not only in terms of pose accuracy but also with a focus on network architectures and models' sizes keeping potential deployment in mind. Then, current monocular spacecraft pose estimation datasets used to train and test these methods are discussed. The data generation methods: simulators and testbeds, the domain gap and the performance drop between synthetically generated and lab/space collected images and the potential solutions are also discussed. Finally, the paper presents open research questions and future directions in the field, drawing parallels with other computer vision applications.
3D-Aware Object Localization using Gaussian Implicit Occupancy Function
Mar 03, 2023



To automatically localize a target object in an image is crucial for many computer vision applications. Recently ellipse representations have been identified as an alternative to axis-aligned bounding boxes for object localization. This paper considers 3D-aware ellipse labels, i.e., which are projections of a 3D ellipsoidal approximation of the object in the images for 2D target localization. Such generic ellipsoidal models allow for handling coarsely known targets, and 3D-aware ellipse detections carry more geometric information about the object than traditional 3D-agnostic bounding box labels. We propose to have a new look at ellipse regression and replace the geometric ellipse parameters with the parameters of an implicit Gaussian distribution encoding object occupancy in the image. The models are trained to regress the values of this bivariate Gaussian distribution over the image pixels using a continuous statistical loss function. We introduce a novel non-trainable differentiable layer, E-DSNT, to extract the distribution parameters. Also, we describe how to readily generate consistent 3D-aware Gaussian occupancy parameters using only coarse dimensions of the target and relative pose labels. We extend three existing spacecraft pose estimation datasets with 3D-aware Gaussian occupancy labels to validate our hypothesis.
Discriminator-free Unsupervised Domain Adaptation for Multi-label Image Classification
Jan 25, 2023



In this paper, a discriminator-free adversarial-based Unsupervised Domain Adaptation (UDA) for Multi-Label Image Classification (MLIC) referred to as DDA-MLIC is proposed. Over the last two years, some attempts have been made for introducing adversarial-based UDA methods in the context of MLIC. However, these methods which rely on an additional discriminator subnet present two shortcomings. First, the learning of domain-invariant features may harm their task-specific discriminative power, since the classification and discrimination tasks are decoupled. Moreover, the use of an additional discriminator usually induces an increase of the network size. Herein, we propose to overcome these issues by introducing a novel adversarial critic that is directly deduced from the task-specific classifier. Specifically, a two-component Gaussian Mixture Model (GMM) is fitted on the source and target predictions, allowing the distinction of two clusters. This allows extracting a Gaussian distribution for each component. The resulting Gaussian distributions are then used for formulating an adversarial loss based on a Frechet distance. The proposed method is evaluated on three multi-label image datasets. The obtained results demonstrate that DDA-MLIC outperforms existing state-of-the-art methods while requiring a lower number of parameters.
Lessons from a Space Lab -- An Image Acquisition Perspective
Aug 18, 2022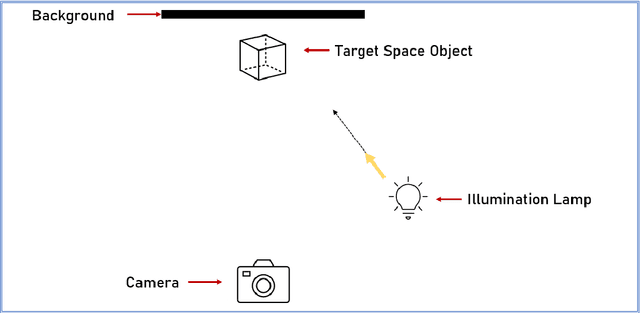
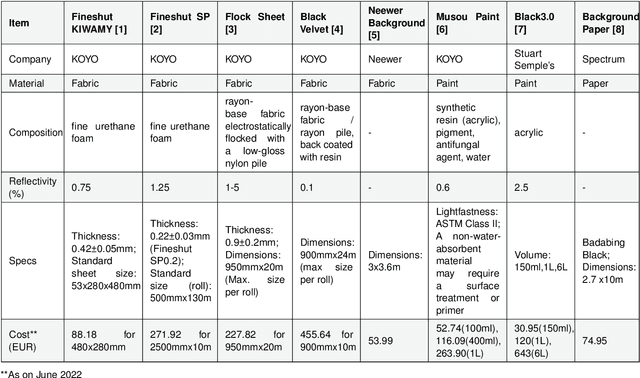
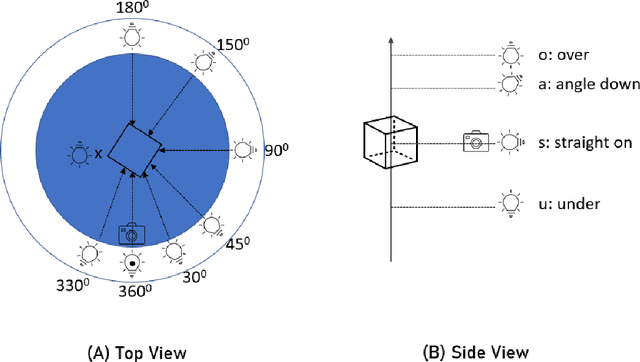
The use of Deep Learning (DL) algorithms has improved the performance of vision-based space applications in recent years. However, generating large amounts of annotated data for training these DL algorithms has proven challenging. While synthetically generated images can be used, the DL models trained on synthetic data are often susceptible to performance degradation, when tested in real-world environments. In this context, the Interdisciplinary Center of Security, Reliability and Trust (SnT) at the University of Luxembourg has developed the 'SnT Zero-G Lab', for training and validating vision-based space algorithms in conditions emulating real-world space environments. An important aspect of the SnT Zero-G Lab development was the equipment selection. From the lessons learned during the lab development, this article presents a systematic approach combining market survey and experimental analyses for equipment selection. In particular, the article focus on the image acquisition equipment in a space lab: background materials, cameras and illumination lamps. The results from the experiment analyses show that the market survey complimented by experimental analyses is required for effective equipment selection in a space lab development project.