 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTER: Latent Pseudo-Anomaly Generation for Unsupervised Time-Series Anomaly Detection
Apr 15, 2026Time-series anomaly detection (TSAD) is critical in domains such as industrial monitoring, healthcare, and cybersecurity, but it remains challenging due to rare and heterogeneous anomalies and the scarcity of labelled data. This scarcity makes unsupervised approaches predominant, yet existing methods often rely on reconstruction or forecasting, which struggle with complex data, or on embedding-based approaches that require domain-specific anomaly synthesis and fixed distance metrics. We propose ASTER, a framework that generates pseudo-anomalies directly in the latent space, avoiding handcrafted anomaly injections and the need for domain expertise. A latent-space decoder produces tailored pseudo-anomalies to train a Transformer-based anomaly classifier, while a pre-trained LLM enriches the temporal and contextual representations of this space. Experiments on three benchmark datasets show that ASTER achieves state-of-the-art performance and sets a new standard for LLM-based TSAD.
Annotation Free Spacecraft Detection and Segmentation using Vision Language Models
Feb 04, 2026Vision Language Models (VLMs) have demonstrated remarkable performance in open-world zero-shot visual recognition. However, their potential in space-related applications remains largely unexplored. In the space domain, accurate manual annotation is particularly challenging due to factors such as low visibility, illumination variations, and object blending with planetary backgrounds. Developing methods that can detect and segment spacecraft and orbital targets without requiring extensive manual labeling is therefore of critical importance. In this work, we propose an annotation-free detection and segmentation pipeline for space targets using VLMs. Our approach begins by automatically generating pseudo-labels for a small subset of unlabeled real data with a pre-trained VLM. These pseudo-labels are then leveraged in a teacher-student label distillation framework to train lightweight models. Despite the inherent noise in the pseudo-labels, the distillation process leads to substantial performance gains over direct zero-shot VLM inference. Experimental evaluations on the SPARK-2024, SPEED+, and TANGO datasets on segmentation tasks demonstrate consistent improvements in average precision (AP) by up to 10 points. Code and models are available at https://github.com/giddyyupp/annotation-free-spacecraft-segmentation.
Training Free Zero-Shot Visual Anomaly Localization via Diffusion Inversion
Jan 12, 2026Zero-Shot image Anomaly Detection (ZSAD) aims to detect and localise anomalies without access to any normal training samples of the target data. While recent ZSAD approaches leverage additional modalities such as language to generate fine-grained prompts for localisation, vision-only methods remain limited to image-level classification, lacking spatial precision. In this work, we introduce a simple yet effective training-free vision-only ZSAD framework that circumvents the need for fine-grained prompts by leveraging the inversion of a pretrained Denoising Diffusion Implicit Model (DDIM). Specifically, given an input image and a generic text description (e.g., "an image of an [object class]"), we invert the image to obtain latent representations and initiate the denoising process from a fixed intermediate timestep to reconstruct the image. Since the underlying diffusion model is trained solely on normal data, this process yields a normal-looking reconstruction. The discrepancy between the input image and the reconstructed one highlights potential anomalies. Our method achieves state-of-the-art performance on VISA dataset, demonstrating strong localisation capabilities without auxiliary modalities and facilitating a shift away from prompt dependence for zero-shot anomaly detection research. Code is available at https://github.com/giddyyupp/DIVAD.
VLMDiff: Leveraging Vision-Language Models for Multi-Class Anomaly Detection with Diffusion
Nov 11, 2025



Detecting visual anomalies in diverse, multi-class real-world images is a significant challenge. We introduce \ours, a novel unsupervised multi-class visual anomaly detection framework. It integrates a Latent Diffusion Model (LDM) with a Vision-Language Model (VLM) for enhanced anomaly localization and detection. Specifically, a pre-trained VLM with a simple prompt extracts detailed image descriptions, serving as additional conditioning for LDM training. Current diffusion-based methods rely on synthetic noise generation, limiting their generalization and requiring per-class model training, which hinders scalability. \ours, however, leverages VLMs to obtain normal captions without manual annotations or additional training. These descriptions condition the diffusion model, learning a robust normal image feature representation for multi-class anomaly detection. Our method achieves competitive performance, improving the pixel-level Per-Region-Overlap (PRO) metric by up to 25 points on the Real-IAD dataset and 8 points on the COCO-AD dataset, outperforming state-of-the-art diffusion-based approaches. Code is available at https://github.com/giddyyupp/VLMDiff.
Removing Geometric Bias in One-Class Anomaly Detection with Adaptive Feature Perturbation
Mar 07, 2025



One-class anomaly detection aims to detect objects that do not belong to a predefined normal class. In practice training data lack those anomalous samples; hence state-of-the-art methods are trained to discriminate between normal and synthetically-generated pseudo-anomalous data. Most methods use data augmentation techniques on normal images to simulate anomalies. However the best-performing ones implicitly leverage a geometric bias present in the benchmarking datasets. This limits their usability in more general conditions. Others are relying on basic noising schemes that may be suboptimal in capturing the underlying structure of normal data. In addition most still favour the image domain to generate pseudo-anomalies training models end-to-end from only the normal class and overlooking richer representations of the information. To overcome these limitations we consider frozen yet rich feature spaces given by pretrained models and create pseudo-anomalous features with a novel adaptive linear feature perturbation technique. It adapts the noise distribution to each sample applies decaying linear perturbations to feature vectors and further guides the classification process using a contrastive learning objective. Experimental evaluation conducted on both standard and geometric bias-free datasets demonstrates the superiority of our approach with respect to comparable baselines. The codebase is accessible via our public repository.
Hybrid Attention for Robust RGB-T Pedestrian Detection in Real-World Conditions
Nov 06, 2024



Multispectral pedestrian detection has gained significant attention in recent years, particularly in autonomous driving applications. To address the challenges posed by adversarial illumination conditions, the combination of thermal and visible images has demonstrated its advantages. However, existing fusion methods rely on the critical assumption that the RGB-Thermal (RGB-T) image pairs are fully overlapping. These assumptions often do not hold in real-world applications, where only partial overlap between images can occur due to sensors configuration. Moreover, sensor failure can cause loss of information in one modality. In this paper, we propose a novel module called the Hybrid Attention (HA) mechanism as our main contribution to mitigate performance degradation caused by partial overlap and sensor failure, i.e. when at least part of the scene is acquired by only one sensor. We propose an improved RGB-T fusion algorithm, robust against partial overlap and sensor failure encountered during inference in real-world applications. We also leverage a mobile-friendly backbone to cope with resource constraints in embedded systems. We conducted experiments by simulating various partial overlap and sensor failure scenarios to evaluate the performance of our proposed method. The results demonstrate that our approach outperforms state-of-the-art methods, showcasing its superiority in handling real-world challenges.
Multi-Objective Hardware Aware Neural Architecture Search using Hardware Cost Diversity
Apr 15, 2024Hardware-aware Neural Architecture Search approaches (HW-NAS) automate the design of deep learning architectures, tailored specifically to a given target hardware platform. Yet, these techniques demand substantial computational resources, primarily due to the expensive process of assessing the performance of identified architectures. To alleviate this problem, a recent direction in the literature has employed representation similarity metric for efficiently evaluating architecture performance. Nonetheless, since it is inherently a single objective method, it requires multiple runs to identify the optimal architecture set satisfying the diverse hardware cost constraints, thereby increasing the search cost. Furthermore, simply converting the single objective into a multi-objective approach results in an under-explored architectural search space. In this study, we propose a Multi-Objective method to address the HW-NAS problem, called MO-HDNAS, to identify the trade-off set of architectures in a single run with low computational cost. This is achieved by optimizing three objectives: maximizing the representation similarity metric, minimizing hardware cost, and maximizing the hardware cost diversity. The third objective, i.e. hardware cost diversity, is used to facilitate a better exploration of the architecture search space. Experimental results demonstrate the effectiveness of our proposed method in efficiently addressing the HW-NAS problem across six edge devices for the image classification task.
Hardware Aware Evolutionary Neural Architecture Search using Representation Similarity Metric
Nov 07, 2023Hardware-aware Neural Architecture Search (HW-NAS) is a technique used to automatically design the architecture of a neural network for a specific task and target hardware. However, evaluating the performance of candidate architectures is a key challenge in HW-NAS, as it requires significant computational resources. To address this challenge, we propose an efficient hardware-aware evolution-based NAS approach called HW-EvRSNAS. Our approach re-frames the neural architecture search problem as finding an architecture with performance similar to that of a reference model for a target hardware, while adhering to a cost constraint for that hardware. This is achieved through a representation similarity metric known as Representation Mutual Information (RMI) employed as a proxy performance evaluator. It measures the mutual information between the hidden layer representations of a reference model and those of sampled architectures using a single training batch. We also use a penalty term that penalizes the search process in proportion to how far an architecture's hardware cost is from the desired hardware cost threshold. This resulted in a significantly reduced search time compared to the literature that reached up to 8000x speedups resulting in lower CO2 emissions. The proposed approach is evaluated on two different search spaces while using lower computational resources. Furthermore, our approach is thoroughly examined on six different edge devices under various hardware cost constraints.
Impact of Disentanglement on Pruning Neural Networks
Jul 19, 2023Deploying deep learning neural networks on edge devices, to accomplish task specific objectives in the real-world, requires a reduction in their memory footprint, power consumption, and latency. This can be realized via efficient model compression. Disentangled latent representations produced by variational autoencoder (VAE) networks are a promising approach for achieving model compression because they mainly retain task-specific information, discarding useless information for the task at hand. We make use of the Beta-VAE framework combined with a standard criterion for pruning to investigate the impact of forcing the network to learn disentangled representations on the pruning process for the task of classification. In particular, we perform experiments on MNIST and CIFAR10 datasets, examine disentanglement challenges, and propose a path forward for future works.
Deep Learning Advances on Different 3D Data Representations: A Survey
Aug 04, 2018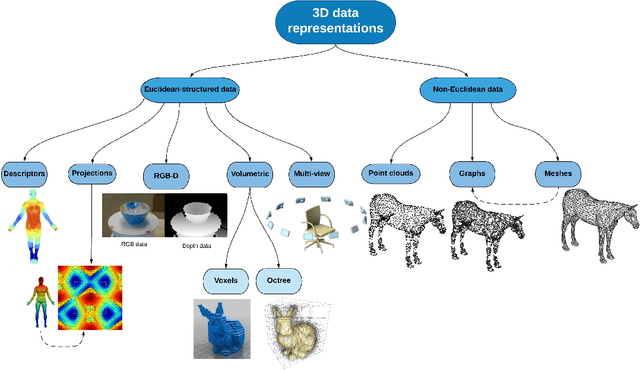
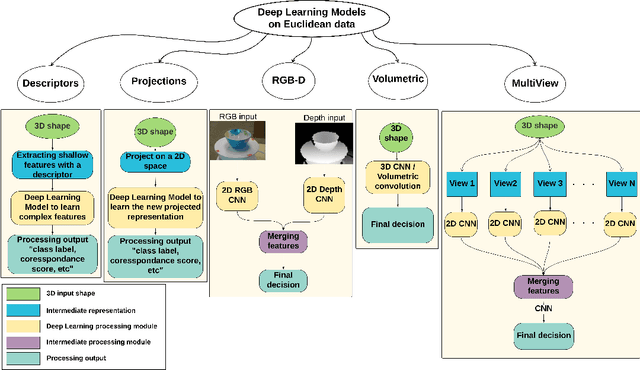
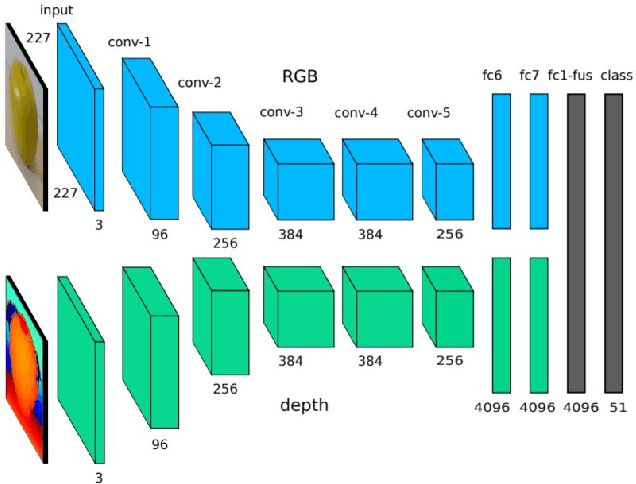
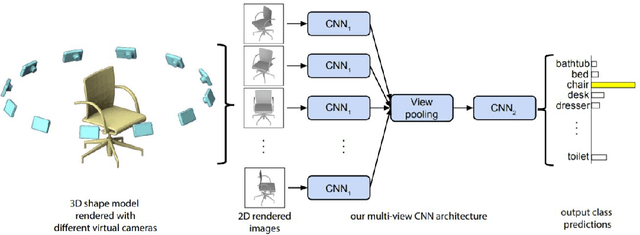
3D data is a valuable asset in the field of computer vision as it provides rich information about the full geometry of sensed objects and scenes. With the recent availability of large 3D datasets and the increase in computational power, it is today possible to consider applying deep learning to learn specific tasks on 3D data such as segmentation, recognition and correspondence. Depending on the considered 3D data representation, different challenges may be foreseen in using existent deep learning architectures. In this paper, we provide a comprehensive overview of various 3D data representations highlighting the difference between Euclidean and non-Euclidean ones. We also discuss how deep learning methods are applied on each representation, analyzing the challenges to overcome.