 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen, Look, and Learn: Learning Without Forgetting through SAM-Audio
Jun 09, 2026Class-Incremental Learning (CIL) aims to continuously learn new classes without forgetting previously acquired knowledge. While recent CIL advances have spurred significant interest across various modalities, the audio-visual setting remains underexplored. Furthermore, although foundational multimodal models like SAM-Audio encapsulate rich static priors, our empirical analysis reveals that these representations struggle in incremental settings. This work bridges this gap by integrating SAM-Audio's audio-visual priors into the CIL setting. Specifically, we leverage its dense audio and visual representations and employ a novel guided attention strategy where the audio features contextually guide the visual representations. To further mitigate catastrophic forgetting, we introduce dual-level distillation objectives at both the feature and logit levels. Extensive evaluations on audio-visual CIL benchmarks demonstrate that our approach consistently outperforms state-of-the-art methods.
Scaling Laws for Energy Efficiency of Local LLMs
Dec 23, 2025Deploying local large language models and vision-language models on edge devices requires balancing accuracy with constrained computational and energy budgets. Although graphics processors dominate modern artificial-intelligence deployment, most consumer hardware--including laptops, desktops, industrial controllers, and embedded systems--relies on central processing units. Despite this, the computational laws governing central-processing-unit-only inference for local language and vision-language workloads remain largely unexplored. We systematically benchmark large language and vision-language models on two representative central-processing-unit tiers widely used for local inference: a MacBook Pro M2, reflecting mainstream laptop-class deployment, and a Raspberry Pi 5, representing constrained, low-power embedded settings. Using a unified methodology based on continuous sampling of processor and memory usage together with area-under-curve integration, we characterize how computational load scales with input text length for language models and with image resolution for vision-language models. We uncover two empirical scaling laws: (1) computational cost for language-model inference scales approximately linearly with token length; and (2) vision-language models exhibit a preprocessing-driven "resolution knee", where compute remains constant above an internal resolution clamp and decreases sharply below it. Beyond these laws, we show that quantum-inspired compression reduces processor and memory usage by up to 71.9% and energy consumption by up to 62%, while preserving or improving semantic accuracy. These results provide a systematic quantification of multimodal central-processing-unit-only scaling for local language and vision-language workloads, and they identify model compression and input-resolution preprocessing as effective, low-cost levers for sustainable edge inference.
Ultralight Signal Classification Model for Automatic Modulation Recognition
Dec 27, 2024The growing complexity of radar signals demands responsive and accurate detection systems that can operate efficiently on resource-constrained edge devices. Existing models, while effective, often rely on substantial computational resources and large datasets, making them impractical for edge deployment. In this work, we propose an ultralight hybrid neural network optimized for edge applications, delivering robust performance across unfavorable signal-to-noise ratios (mean accuracy of 96.3% at 0 dB) using less than 100 samples per class, and significantly reducing computational overhead.
Multi-Objective Hardware Aware Neural Architecture Search using Hardware Cost Diversity
Apr 15, 2024Hardware-aware Neural Architecture Search approaches (HW-NAS) automate the design of deep learning architectures, tailored specifically to a given target hardware platform. Yet, these techniques demand substantial computational resources, primarily due to the expensive process of assessing the performance of identified architectures. To alleviate this problem, a recent direction in the literature has employed representation similarity metric for efficiently evaluating architecture performance. Nonetheless, since it is inherently a single objective method, it requires multiple runs to identify the optimal architecture set satisfying the diverse hardware cost constraints, thereby increasing the search cost. Furthermore, simply converting the single objective into a multi-objective approach results in an under-explored architectural search space. In this study, we propose a Multi-Objective method to address the HW-NAS problem, called MO-HDNAS, to identify the trade-off set of architectures in a single run with low computational cost. This is achieved by optimizing three objectives: maximizing the representation similarity metric, minimizing hardware cost, and maximizing the hardware cost diversity. The third objective, i.e. hardware cost diversity, is used to facilitate a better exploration of the architecture search space. Experimental results demonstrate the effectiveness of our proposed method in efficiently addressing the HW-NAS problem across six edge devices for the image classification task.
Hardware Aware Evolutionary Neural Architecture Search using Representation Similarity Metric
Nov 07, 2023Hardware-aware Neural Architecture Search (HW-NAS) is a technique used to automatically design the architecture of a neural network for a specific task and target hardware. However, evaluating the performance of candidate architectures is a key challenge in HW-NAS, as it requires significant computational resources. To address this challenge, we propose an efficient hardware-aware evolution-based NAS approach called HW-EvRSNAS. Our approach re-frames the neural architecture search problem as finding an architecture with performance similar to that of a reference model for a target hardware, while adhering to a cost constraint for that hardware. This is achieved through a representation similarity metric known as Representation Mutual Information (RMI) employed as a proxy performance evaluator. It measures the mutual information between the hidden layer representations of a reference model and those of sampled architectures using a single training batch. We also use a penalty term that penalizes the search process in proportion to how far an architecture's hardware cost is from the desired hardware cost threshold. This resulted in a significantly reduced search time compared to the literature that reached up to 8000x speedups resulting in lower CO2 emissions. The proposed approach is evaluated on two different search spaces while using lower computational resources. Furthermore, our approach is thoroughly examined on six different edge devices under various hardware cost constraints.
Impact of Disentanglement on Pruning Neural Networks
Jul 19, 2023Deploying deep learning neural networks on edge devices, to accomplish task specific objectives in the real-world, requires a reduction in their memory footprint, power consumption, and latency. This can be realized via efficient model compression. Disentangled latent representations produced by variational autoencoder (VAE) networks are a promising approach for achieving model compression because they mainly retain task-specific information, discarding useless information for the task at hand. We make use of the Beta-VAE framework combined with a standard criterion for pruning to investigate the impact of forcing the network to learn disentangled representations on the pruning process for the task of classification. In particular, we perform experiments on MNIST and CIFAR10 datasets, examine disentanglement challenges, and propose a path forward for future works.
Novelty Driven Evolutionary Neural Architecture Search
Apr 01, 2022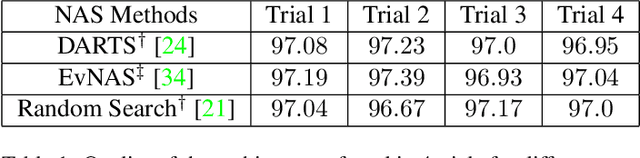
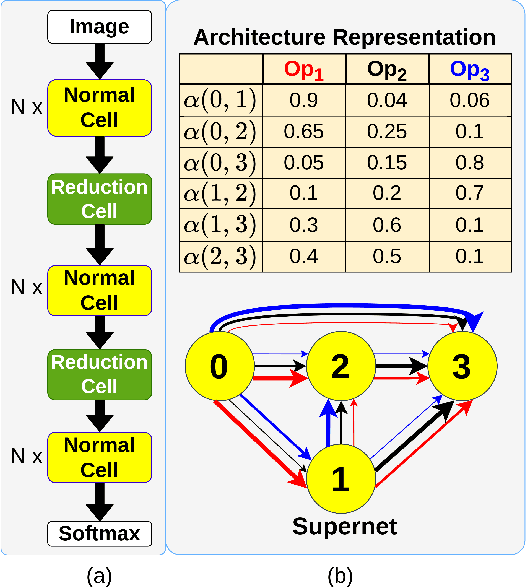
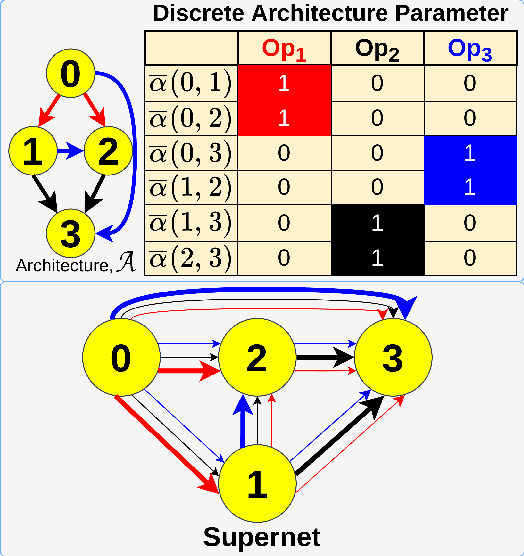
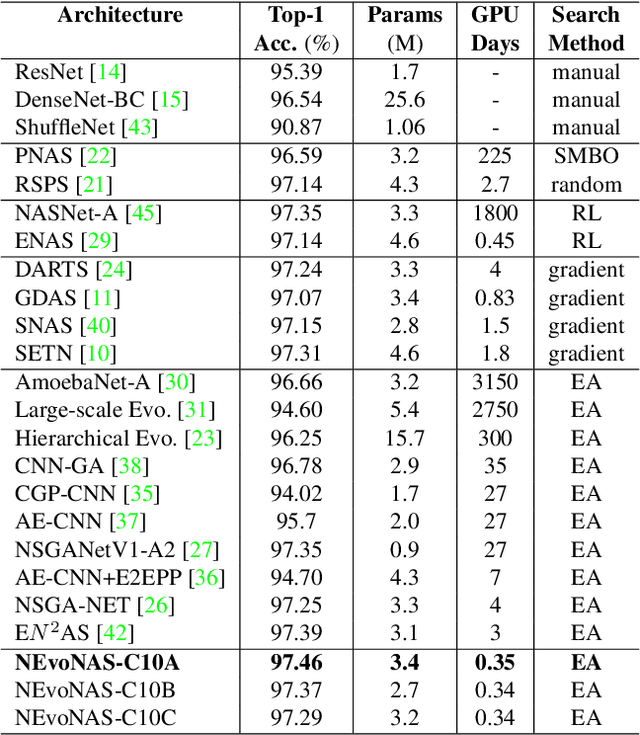
Evolutionary algorithms (EA) based neural architecture search (NAS) involves evaluating each architecture by training it from scratch, which is extremely time-consuming. This can be reduced by using a supernet for estimating the fitness of an architecture due to weight sharing among all architectures in the search space. However, the estimated fitness is very noisy due to the co-adaptation of the operations in the supernet which results in NAS methods getting trapped in local optimum. In this paper, we propose a method called NEvoNAS wherein the NAS problem is posed as a multi-objective problem with 2 objectives: (i) maximize architecture novelty, (ii) maximize architecture fitness/accuracy. The novelty search is used for maintaining a diverse set of solutions at each generation which helps avoiding local optimum traps while the architecture fitness is calculated using supernet. NSGA-II is used for finding the \textit{pareto optimal front} for the NAS problem and the best architecture in the pareto front is returned as the searched architecture. Exerimentally, NEvoNAS gives better results on 2 different search spaces while using significantly less computational resources as compared to previous EA-based methods. The code for our paper can be found in https://github.com/nightstorm0909/NEvoNAS.
Neural Architecture Search using Progressive Evolution
Mar 03, 2022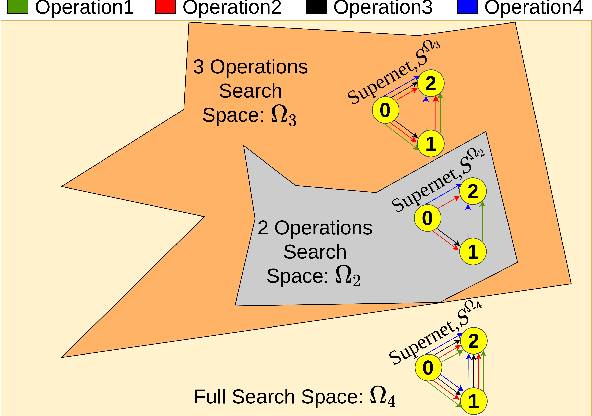
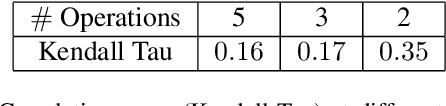
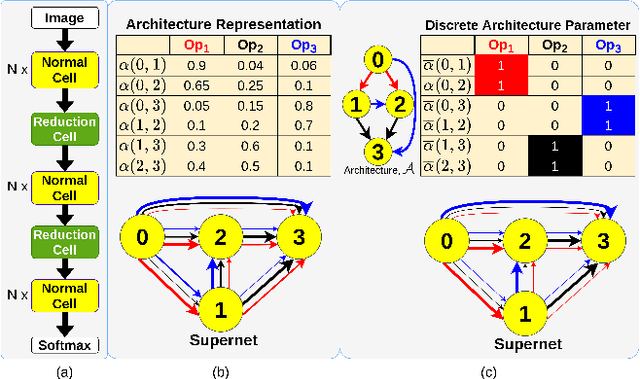
Vanilla neural architecture search using evolutionary algorithms (EA) involves evaluating each architecture by training it from scratch, which is extremely time-consuming. This can be reduced by using a supernet to estimate the fitness of every architecture in the search space due to its weight sharing nature. However, the estimated fitness is very noisy due to the co-adaptation of the operations in the supernet. In this work, we propose a method called pEvoNAS wherein the whole neural architecture search space is progressively reduced to smaller search space regions with good architectures. This is achieved by using a trained supernet for architecture evaluation during the architecture search using genetic algorithm to find search space regions with good architectures. Upon reaching the final reduced search space, the supernet is then used to search for the best architecture in that search space using evolution. The search is also enhanced by using weight inheritance wherein the supernet for the smaller search space inherits its weights from previous trained supernet for the bigger search space. Exerimentally, pEvoNAS gives better results on CIFAR-10 and CIFAR-100 while using significantly less computational resources as compared to previous EA-based methods. The code for our paper can be found in https://github.com/nightstorm0909/pEvoNAS
Neural Architecture Search using Covariance Matrix Adaptation Evolution Strategy
Jul 15, 2021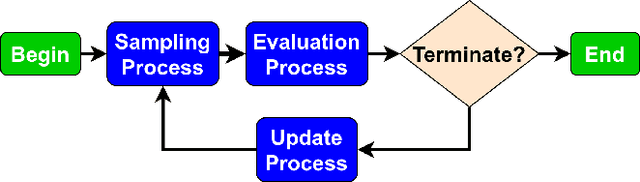
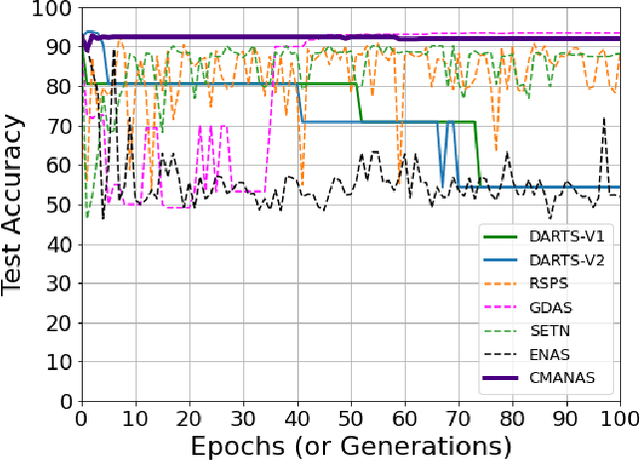
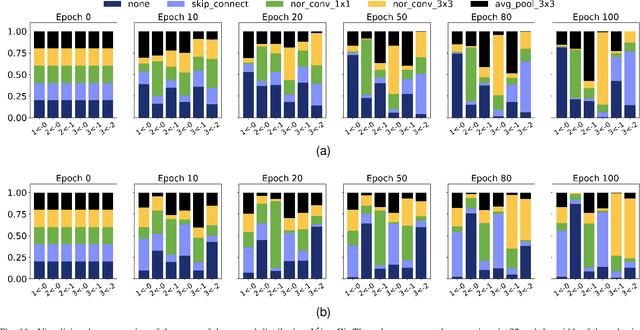
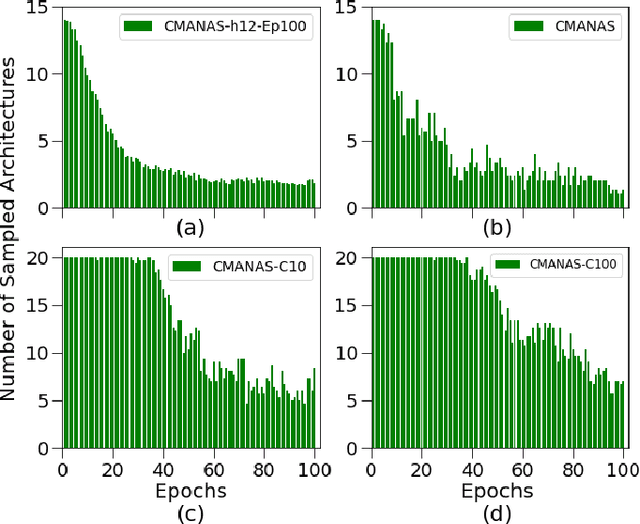
Evolution-based neural architecture search requires high computational resources, resulting in long search time. In this work, we propose a framework of applying the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) to the neural architecture search problem called CMANAS, which achieves better results than previous evolution-based methods while reducing the search time significantly. The architectures are modelled using a normal distribution, which is updated using CMA-ES based on the fitness of the sampled population. We used the accuracy of a trained one shot model (OSM) on the validation data as a prediction of the fitness of an individual architecture to reduce the search time. We also used an architecture-fitness table (AF table) for keeping record of the already evaluated architecture, thus further reducing the search time. CMANAS finished the architecture search on CIFAR-10 with the top-1 test accuracy of 97.44% in 0.45 GPU day and on CIFAR-100 with the top-1 test accuracy of 83.24% for 0.6 GPU day on a single GPU. The top architectures from the searches on CIFAR-10 and CIFAR-100 were then transferred to ImageNet, achieving the top-5 accuracy of 92.6% and 92.1%, respectively.
Evolving Neural Architecture Using One Shot Model
Dec 23, 2020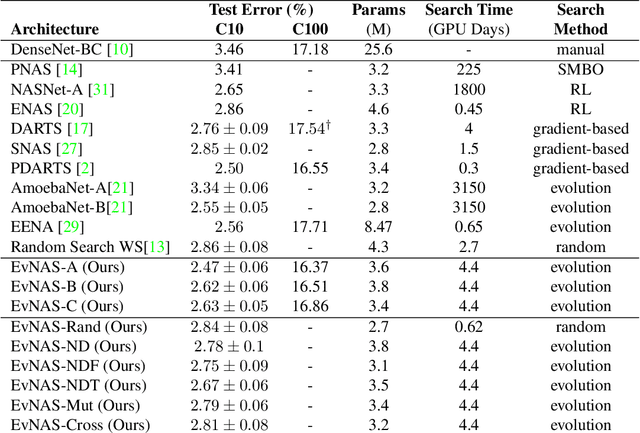
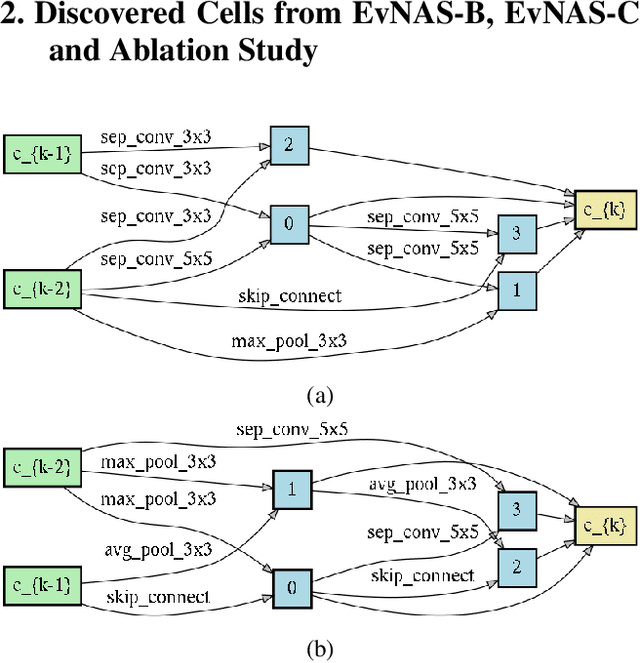
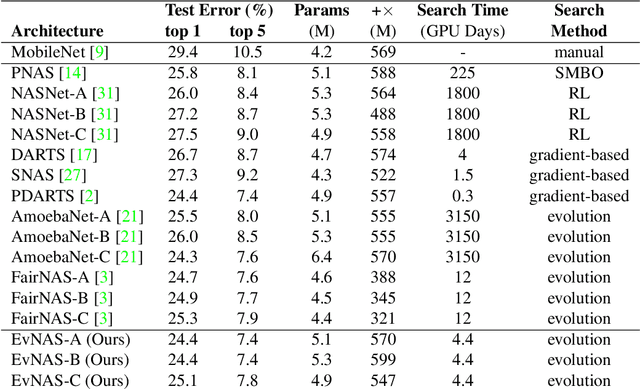
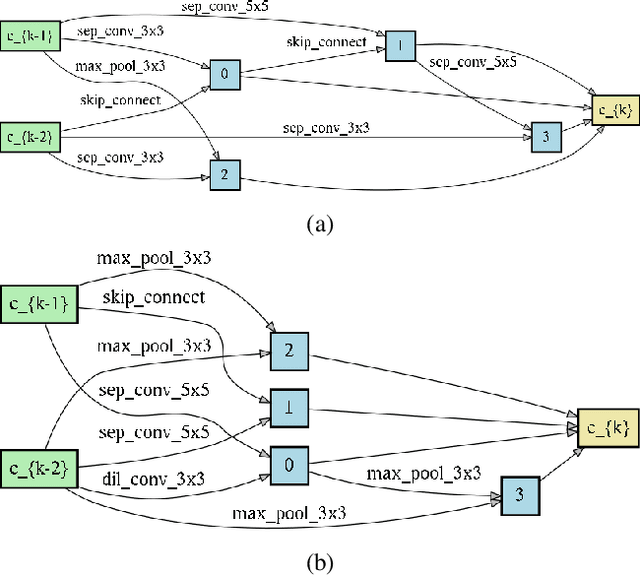
Neural Architecture Search (NAS) is emerging as a new research direction which has the potential to replace the hand-crafted neural architectures designed for specific tasks. Previous evolution based architecture search requires high computational resources resulting in high search time. In this work, we propose a novel way of applying a simple genetic algorithm to the NAS problem called EvNAS (Evolving Neural Architecture using One Shot Model) which reduces the search time significantly while still achieving better result than previous evolution based methods. The architectures are represented by using the architecture parameter of the one shot model which results in the weight sharing among the architectures for a given population of architectures and also weight inheritance from one generation to the next generation of architectures. We propose a decoding technique for the architecture parameter which is used to divert majority of the gradient information towards the given architecture and is also used for improving the performance prediction of the given architecture from the one shot model during the search process. Furthermore, we use the accuracy of the partially trained architecture on the validation data as a prediction of its fitness in order to reduce the search time. EvNAS searches for the architecture on the proxy dataset i.e. CIFAR-10 for 4.4 GPU day on a single GPU and achieves top-1 test error of 2.47% with 3.63M parameters which is then transferred to CIFAR-100 and ImageNet achieving top-1 error of 16.37% and top-5 error of 7.4% respectively. All of these results show the potential of evolutionary methods in solving the architecture search problem.