 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAA-X: Unified Localized Artifact Attention for Quality-Agnostic and Generalizable Face Forgery Detection
Apr 05, 2026In this paper, we propose Localized Artifact Attention X (LAA-X), a novel deepfake detection framework that is both robust to high-quality forgeries and capable of generalizing to unseen manipulations. Existing approaches typically rely on binary classifiers coupled with implicit attention mechanisms, which often fail to generalize beyond known manipulations. In contrast, LAA-X introduces an explicit attention strategy based on a multi-task learning framework combined with blending-based data synthesis. Auxiliary tasks are designed to guide the model toward localized, artifact-prone (i.e., vulnerable) regions. The proposed framework is compatible with both CNN and transformer backbones, resulting in two different versions, namely, LAA-Net and LAA-Former, respectively. Despite being trained only on real and pseudo-fake samples, LAA-X competes with state-of-the-art methods across multiple benchmarks. Code and pre-trained weights for LAA-Net\footnote{https://github.com/10Ring/LAA-Net} and LAA-Former\footnote{https://github.com/10Ring/LAA-Former} are publicly available.
Cov2Pose: Leveraging Spatial Covariance for Direct Manifold-aware 6-DoF Object Pose Estimation
Mar 20, 2026In this paper, we address the problem of 6-DoF object pose estimation from a single RGB image. Indirect methods that typically predict intermediate 2D keypoints, followed by a Perspective-n-Point solver, have shown great performance. Direct approaches, which regress the pose in an end-to-end manner, are usually computationally more efficient but less accurate. However, direct heads rely on globally pooled features, ignoring spatial second-order statistics despite their informativeness in pose prediction. They also predict, in most cases, discontinuous pose representations that lack robustness. Herein, we therefore propose a covariance-pooled representation that encodes convolutional feature distributions as a symmetric positive definite (SPD) matrix. Moreover, we propose a novel pose encoding in the form of an SPD matrix via its Cholesky decomposition. Pose is then regressed in an end-to-end manner with a manifold-aware network head, taking into account the Riemannian geometry of SPD matrices. Experiments and ablations consistently demonstrate the relevance of second-order pooling and continuous representations for direct pose regression, including under partial occlusion.
MultiMAE Meets Earth Observation: Pre-training Multi-modal Multi-task Masked Autoencoders for Earth Observation Tasks
May 20, 2025Multi-modal data in Earth Observation (EO) presents a huge opportunity for improving transfer learning capabilities when pre-training deep learning models. Unlike prior work that often overlooks multi-modal EO data, recent methods have started to include it, resulting in more effective pre-training strategies. However, existing approaches commonly face challenges in effectively transferring learning to downstream tasks where the structure of available data differs from that used during pre-training. This paper addresses this limitation by exploring a more flexible multi-modal, multi-task pre-training strategy for EO data. Specifically, we adopt a Multi-modal Multi-task Masked Autoencoder (MultiMAE) that we pre-train by reconstructing diverse input modalities, including spectral, elevation, and segmentation data. The pre-trained model demonstrates robust transfer learning capabilities, outperforming state-of-the-art methods on various EO datasets for classification and segmentation tasks. Our approach exhibits significant flexibility, handling diverse input configurations without requiring modality-specific pre-trained models. Code will be available at: https://github.com/josesosajs/multimae-meets-eo.
Domain Adaptation for Multi-label Image Classification: a Discriminator-free Approach
May 20, 2025This paper introduces a discriminator-free adversarial-based approach termed DDA-MLIC for Unsupervised Domain Adaptation (UDA) in the context of Multi-Label Image Classification (MLIC). While recent efforts have explored adversarial-based UDA methods for MLIC, they typically include an additional discriminator subnet. Nevertheless, decoupling the classification and the discrimination tasks may harm their task-specific discriminative power. Herein, we address this challenge by presenting a novel adversarial critic directly derived from the task-specific classifier. Specifically, we employ a two-component Gaussian Mixture Model (GMM) to model both source and target predictions, distinguishing between two distinct clusters. Instead of using the traditional Expectation Maximization (EM) algorithm, our approach utilizes a Deep Neural Network (DNN) to estimate the parameters of each GMM component. Subsequently, the source and target GMM parameters are leveraged to formulate an adversarial loss using the Fr\'echet distance. The proposed framework is therefore not only fully differentiable but is also cost-effective as it avoids the expensive iterative process usually induced by the standard EM method. The proposed method is evaluated on several multi-label image datasets covering three different types of domain shift. The obtained results demonstrate that DDA-MLIC outperforms existing state-of-the-art methods in terms of precision while requiring a lower number of parameters. The code is made publicly available at github.com/cvi2snt/DDA-MLIC.
Uncertainty-Aware Knowledge Distillation for Compact and Efficient 6DoF Pose Estimation
Mar 17, 2025Compact and efficient 6DoF object pose estimation is crucial in applications such as robotics, augmented reality, and space autonomous navigation systems, where lightweight models are critical for real-time accurate performance. This paper introduces a novel uncertainty-aware end-to-end Knowledge Distillation (KD) framework focused on keypoint-based 6DoF pose estimation. Keypoints predicted by a large teacher model exhibit varying levels of uncertainty that can be exploited within the distillation process to enhance the accuracy of the student model while ensuring its compactness. To this end, we propose a distillation strategy that aligns the student and teacher predictions by adjusting the knowledge transfer based on the uncertainty associated with each teacher keypoint prediction. Additionally, the proposed KD leverages this uncertainty-aware alignment of keypoints to transfer the knowledge at key locations of their respective feature maps. Experiments on the widely-used LINEMOD benchmark demonstrate the effectiveness of our method, achieving superior 6DoF object pose estimation with lightweight models compared to state-of-the-art approaches. Further validation on the SPEED+ dataset for spacecraft pose estimation highlights the robustness of our approach under diverse 6DoF pose estimation scenarios.
When Unsupervised Domain Adaptation meets One-class Anomaly Detection: Addressing the Two-fold Unsupervised Curse by Leveraging Anomaly Scarcity
Feb 28, 2025This paper introduces the first fully unsupervised domain adaptation (UDA) framework for unsupervised anomaly detection (UAD). The performance of UAD techniques degrades significantly in the presence of a domain shift, difficult to avoid in a real-world setting. While UDA has contributed to solving this issue in binary and multi-class classification, such a strategy is ill-posed in UAD. This might be explained by the unsupervised nature of the two tasks, namely, domain adaptation and anomaly detection. Herein, we first formulate this problem that we call the two-fold unsupervised curse. Then, we propose a pioneering solution to this curse, considered intractable so far, by assuming that anomalies are rare. Specifically, we leverage clustering techniques to identify a dominant cluster in the target feature space. Posed as the normal cluster, the latter is aligned with the source normal features. Concretely, given a one-class source set and an unlabeled target set composed mostly of normal data and some anomalies, we fit the source features within a hypersphere while jointly aligning them with the features of the dominant cluster from the target set. The paper provides extensive experiments and analysis on common adaptation benchmarks for anomaly detection, demonstrating the relevance of both the newly introduced paradigm and the proposed approach. The code will be made publicly available.
Vulnerability-Aware Spatio-Temporal Learning for Generalizable and Interpretable Deepfake Video Detection
Jan 02, 2025



Detecting deepfake videos is highly challenging due to the complex intertwined spatial and temporal artifacts in forged sequences. Most recent approaches rely on binary classifiers trained on both real and fake data. However, such methods may struggle to focus on important artifacts, which can hinder their generalization capability. Additionally, these models often lack interpretability, making it difficult to understand how predictions are made. To address these issues, we propose FakeSTormer, offering two key contributions. First, we introduce a multi-task learning framework with additional spatial and temporal branches that enable the model to focus on subtle spatio-temporal artifacts. These branches also provide interpretability by highlighting video regions that may contain artifacts. Second, we propose a video-level data synthesis algorithm that generates pseudo-fake videos with subtle artifacts, providing the model with high-quality samples and ground truth data for our spatial and temporal branches. Extensive experiments on several challenging benchmarks demonstrate the competitiveness of our approach compared to recent state-of-the-art methods. The code is available at https://github.com/10Ring/FakeSTormer.
CAD-Assistant: Tool-Augmented VLLMs as Generic CAD Task Solvers?
Dec 18, 2024We propose CAD-Assistant, a general-purpose CAD agent for AI-assisted design. Our approach is based on a powerful Vision and Large Language Model (VLLM) as a planner and a tool-augmentation paradigm using CAD-specific modules. CAD-Assistant addresses multimodal user queries by generating actions that are iteratively executed on a Python interpreter equipped with the FreeCAD software, accessed via its Python API. Our framework is able to assess the impact of generated CAD commands on geometry and adapts subsequent actions based on the evolving state of the CAD design. We consider a wide range of CAD-specific tools including Python libraries, modules of the FreeCAD Python API, helpful routines, rendering functions and other specialized modules. We evaluate our method on multiple CAD benchmarks and qualitatively demonstrate the potential of tool-augmented VLLMs as generic CAD task solvers across diverse CAD workflows.
CAD-Recode: Reverse Engineering CAD Code from Point Clouds
Dec 18, 2024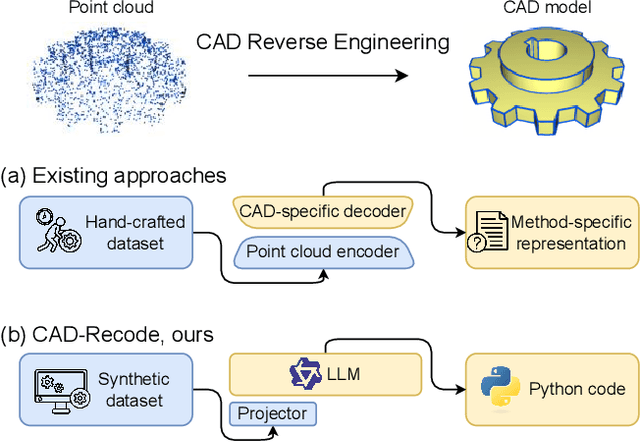
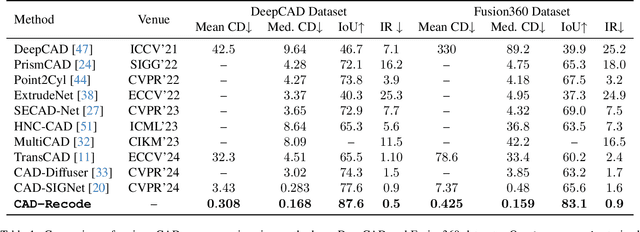

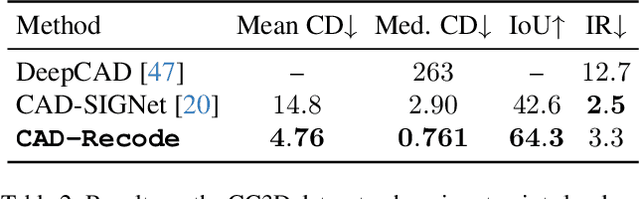
Computer-Aided Design (CAD) models are typically constructed by sequentially drawing parametric sketches and applying CAD operations to obtain a 3D model. The problem of 3D CAD reverse engineering consists of reconstructing the sketch and CAD operation sequences from 3D representations such as point clouds. In this paper, we address this challenge through novel contributions across three levels: CAD sequence representation, network design, and dataset. In particular, we represent CAD sketch-extrude sequences as Python code. The proposed CAD-Recode translates a point cloud into Python code that, when executed, reconstructs the CAD model. Taking advantage of the exposure of pre-trained Large Language Models (LLMs) to Python code, we leverage a relatively small LLM as a decoder for CAD-Recode and combine it with a lightweight point cloud projector. CAD-Recode is trained solely on a proposed synthetic dataset of one million diverse CAD sequences. CAD-Recode significantly outperforms existing methods across three datasets while requiring fewer input points. Notably, it achieves 10 times lower mean Chamfer distance than state-of-the-art methods on DeepCAD and Fusion360 datasets. Furthermore, we show that our CAD Python code output is interpretable by off-the-shelf LLMs, enabling CAD editing and CAD-specific question answering from point clouds.
Hybrid Attention for Robust RGB-T Pedestrian Detection in Real-World Conditions
Nov 06, 2024



Multispectral pedestrian detection has gained significant attention in recent years, particularly in autonomous driving applications. To address the challenges posed by adversarial illumination conditions, the combination of thermal and visible images has demonstrated its advantages. However, existing fusion methods rely on the critical assumption that the RGB-Thermal (RGB-T) image pairs are fully overlapping. These assumptions often do not hold in real-world applications, where only partial overlap between images can occur due to sensors configuration. Moreover, sensor failure can cause loss of information in one modality. In this paper, we propose a novel module called the Hybrid Attention (HA) mechanism as our main contribution to mitigate performance degradation caused by partial overlap and sensor failure, i.e. when at least part of the scene is acquired by only one sensor. We propose an improved RGB-T fusion algorithm, robust against partial overlap and sensor failure encountered during inference in real-world applications. We also leverage a mobile-friendly backbone to cope with resource constraints in embedded systems. We conducted experiments by simulating various partial overlap and sensor failure scenarios to evaluate the performance of our proposed method. The results demonstrate that our approach outperforms state-of-the-art methods, showcasing its superiority in handling real-world challenges.