 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation Free Spacecraft Detection and Segmentation using Vision Language Models
Feb 04, 2026Vision Language Models (VLMs) have demonstrated remarkable performance in open-world zero-shot visual recognition. However, their potential in space-related applications remains largely unexplored. In the space domain, accurate manual annotation is particularly challenging due to factors such as low visibility, illumination variations, and object blending with planetary backgrounds. Developing methods that can detect and segment spacecraft and orbital targets without requiring extensive manual labeling is therefore of critical importance. In this work, we propose an annotation-free detection and segmentation pipeline for space targets using VLMs. Our approach begins by automatically generating pseudo-labels for a small subset of unlabeled real data with a pre-trained VLM. These pseudo-labels are then leveraged in a teacher-student label distillation framework to train lightweight models. Despite the inherent noise in the pseudo-labels, the distillation process leads to substantial performance gains over direct zero-shot VLM inference. Experimental evaluations on the SPARK-2024, SPEED+, and TANGO datasets on segmentation tasks demonstrate consistent improvements in average precision (AP) by up to 10 points. Code and models are available at https://github.com/giddyyupp/annotation-free-spacecraft-segmentation.
MultiMAE Meets Earth Observation: Pre-training Multi-modal Multi-task Masked Autoencoders for Earth Observation Tasks
May 20, 2025Multi-modal data in Earth Observation (EO) presents a huge opportunity for improving transfer learning capabilities when pre-training deep learning models. Unlike prior work that often overlooks multi-modal EO data, recent methods have started to include it, resulting in more effective pre-training strategies. However, existing approaches commonly face challenges in effectively transferring learning to downstream tasks where the structure of available data differs from that used during pre-training. This paper addresses this limitation by exploring a more flexible multi-modal, multi-task pre-training strategy for EO data. Specifically, we adopt a Multi-modal Multi-task Masked Autoencoder (MultiMAE) that we pre-train by reconstructing diverse input modalities, including spectral, elevation, and segmentation data. The pre-trained model demonstrates robust transfer learning capabilities, outperforming state-of-the-art methods on various EO datasets for classification and segmentation tasks. Our approach exhibits significant flexibility, handling diverse input configurations without requiring modality-specific pre-trained models. Code will be available at: https://github.com/josesosajs/multimae-meets-eo.
How Effective is Pre-training of Large Masked Autoencoders for Downstream Earth Observation Tasks?
Sep 27, 2024
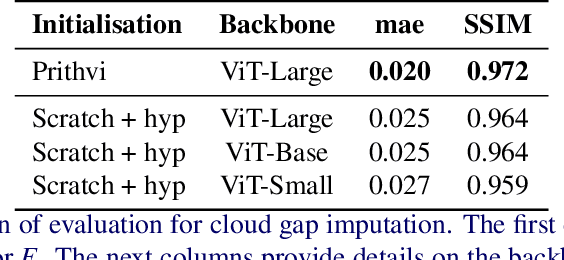


Self-supervised pre-training has proven highly effective for many computer vision tasks, particularly when labelled data are scarce. In the context of Earth Observation (EO), foundation models and various other Vision Transformer (ViT)-based approaches have been successfully applied for transfer learning to downstream tasks. However, it remains unclear under which conditions pre-trained models offer significant advantages over training from scratch. In this study, we investigate the effectiveness of pre-training ViT-based Masked Autoencoders (MAE) for downstream EO tasks, focusing on reconstruction, segmentation, and classification. We consider two large ViT-based MAE pre-trained models: a foundation model (Prithvi) and SatMAE. We evaluate Prithvi on reconstruction and segmentation-based downstream tasks, and for SatMAE we assess its performance on a classification downstream task. Our findings suggest that pre-training is particularly beneficial when the fine-tuning task closely resembles the pre-training task, e.g. reconstruction. In contrast, for tasks such as segmentation or classification, training from scratch with specific hyperparameter adjustments proved to be equally or more effective.
A Horse with no Labels: Self-Supervised Horse Pose Estimation from Unlabelled Images and Synthetic Prior
Aug 07, 2023Obtaining labelled data to train deep learning methods for estimating animal pose is challenging. Recently, synthetic data has been widely used for pose estimation tasks, but most methods still rely on supervised learning paradigms utilising synthetic images and labels. Can training be fully unsupervised? Is a tiny synthetic dataset sufficient? What are the minimum assumptions that we could make for estimating animal pose? Our proposal addresses these questions through a simple yet effective self-supervised method that only assumes the availability of unlabelled images and a small set of synthetic 2D poses. We completely remove the need for any 3D or 2D pose annotations (or complex 3D animal models), and surprisingly our approach can still learn accurate 3D and 2D poses simultaneously. We train our method with unlabelled images of horses mainly collected for YouTube videos and a prior consisting of 2D synthetic poses. The latter is three times smaller than the number of images needed for training. We test our method on a challenging set of horse images and evaluate the predicted 3D and 2D poses. We demonstrate that it is possible to learn accurate animal poses even with as few assumptions as unlabelled images and a small set of 2D poses generated from synthetic data. Given the minimum requirements and the abundance of unlabelled data, our method could be easily deployed to different animals.
Of Mice and Pose: 2D Mouse Pose Estimation from Unlabelled Data and Synthetic Prior
Jul 25, 2023Numerous fields, such as ecology, biology, and neuroscience, use animal recordings to track and measure animal behaviour. Over time, a significant volume of such data has been produced, but some computer vision techniques cannot explore it due to the lack of annotations. To address this, we propose an approach for estimating 2D mouse body pose from unlabelled images using a synthetically generated empirical pose prior. Our proposal is based on a recent self-supervised method for estimating 2D human pose that uses single images and a set of unpaired typical 2D poses within a GAN framework. We adapt this method to the limb structure of the mouse and generate the empirical prior of 2D poses from a synthetic 3D mouse model, thereby avoiding manual annotation. In experiments on a new mouse video dataset, we evaluate the performance of the approach by comparing pose predictions to a manually obtained ground truth. We also compare predictions with those from a supervised state-of-the-art method for animal pose estimation. The latter evaluation indicates promising results despite the lack of paired training data. Finally, qualitative results using a dataset of horse images show the potential of the setting to adapt to other animal species.
Self-supervised 3D Human Pose Estimation from a Single Image
Apr 05, 2023We propose a new self-supervised method for predicting 3D human body pose from a single image. The prediction network is trained from a dataset of unlabelled images depicting people in typical poses and a set of unpaired 2D poses. By minimising the need for annotated data, the method has the potential for rapid application to pose estimation of other articulated structures (e.g. animals). The self-supervision comes from an earlier idea exploiting consistency between predicted pose under 3D rotation. Our method is a substantial advance on state-of-the-art self-supervised methods in training a mapping directly from images, without limb articulation constraints or any 3D empirical pose prior. We compare performance with state-of-the-art self-supervised methods using benchmark datasets that provide images and ground-truth 3D pose (Human3.6M, MPI-INF-3DHP). Despite the reduced requirement for annotated data, we show that the method outperforms on Human3.6M and matches performance on MPI-INF-3DHP. Qualitative results on a dataset of human hands show the potential for rapidly learning to predict 3D pose for articulated structures other than the human body.