 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Effective is Pre-training of Large Masked Autoencoders for Downstream Earth Observation Tasks?
Sep 27, 2024
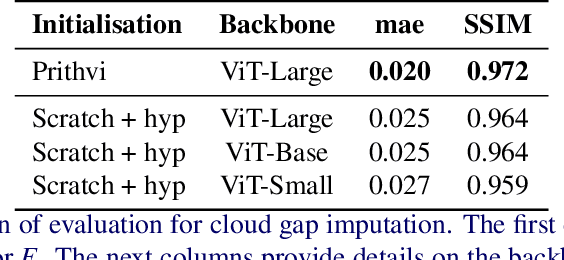


Self-supervised pre-training has proven highly effective for many computer vision tasks, particularly when labelled data are scarce. In the context of Earth Observation (EO), foundation models and various other Vision Transformer (ViT)-based approaches have been successfully applied for transfer learning to downstream tasks. However, it remains unclear under which conditions pre-trained models offer significant advantages over training from scratch. In this study, we investigate the effectiveness of pre-training ViT-based Masked Autoencoders (MAE) for downstream EO tasks, focusing on reconstruction, segmentation, and classification. We consider two large ViT-based MAE pre-trained models: a foundation model (Prithvi) and SatMAE. We evaluate Prithvi on reconstruction and segmentation-based downstream tasks, and for SatMAE we assess its performance on a classification downstream task. Our findings suggest that pre-training is particularly beneficial when the fine-tuning task closely resembles the pre-training task, e.g. reconstruction. In contrast, for tasks such as segmentation or classification, training from scratch with specific hyperparameter adjustments proved to be equally or more effective.