 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Geometric Bias in One-Class Anomaly Detection with Adaptive Feature Perturbation
Mar 07, 2025



One-class anomaly detection aims to detect objects that do not belong to a predefined normal class. In practice training data lack those anomalous samples; hence state-of-the-art methods are trained to discriminate between normal and synthetically-generated pseudo-anomalous data. Most methods use data augmentation techniques on normal images to simulate anomalies. However the best-performing ones implicitly leverage a geometric bias present in the benchmarking datasets. This limits their usability in more general conditions. Others are relying on basic noising schemes that may be suboptimal in capturing the underlying structure of normal data. In addition most still favour the image domain to generate pseudo-anomalies training models end-to-end from only the normal class and overlooking richer representations of the information. To overcome these limitations we consider frozen yet rich feature spaces given by pretrained models and create pseudo-anomalous features with a novel adaptive linear feature perturbation technique. It adapts the noise distribution to each sample applies decaying linear perturbations to feature vectors and further guides the classification process using a contrastive learning objective. Experimental evaluation conducted on both standard and geometric bias-free datasets demonstrates the superiority of our approach with respect to comparable baselines. The codebase is accessible via our public repository.
Hybrid Attention for Robust RGB-T Pedestrian Detection in Real-World Conditions
Nov 06, 2024



Multispectral pedestrian detection has gained significant attention in recent years, particularly in autonomous driving applications. To address the challenges posed by adversarial illumination conditions, the combination of thermal and visible images has demonstrated its advantages. However, existing fusion methods rely on the critical assumption that the RGB-Thermal (RGB-T) image pairs are fully overlapping. These assumptions often do not hold in real-world applications, where only partial overlap between images can occur due to sensors configuration. Moreover, sensor failure can cause loss of information in one modality. In this paper, we propose a novel module called the Hybrid Attention (HA) mechanism as our main contribution to mitigate performance degradation caused by partial overlap and sensor failure, i.e. when at least part of the scene is acquired by only one sensor. We propose an improved RGB-T fusion algorithm, robust against partial overlap and sensor failure encountered during inference in real-world applications. We also leverage a mobile-friendly backbone to cope with resource constraints in embedded systems. We conducted experiments by simulating various partial overlap and sensor failure scenarios to evaluate the performance of our proposed method. The results demonstrate that our approach outperforms state-of-the-art methods, showcasing its superiority in handling real-world challenges.
Space Debris: Are Deep Learning-based Image Enhancements part of the Solution?
Aug 01, 2023

The volume of space debris currently orbiting the Earth is reaching an unsustainable level at an accelerated pace. The detection, tracking, identification, and differentiation between orbit-defined, registered spacecraft, and rogue/inactive space ``objects'', is critical to asset protection. The primary objective of this work is to investigate the validity of Deep Neural Network (DNN) solutions to overcome the limitations and image artefacts most prevalent when captured with monocular cameras in the visible light spectrum. In this work, a hybrid UNet-ResNet34 Deep Learning (DL) architecture pre-trained on the ImageNet dataset, is developed. Image degradations addressed include blurring, exposure issues, poor contrast, and noise. The shortage of space-generated data suitable for supervised DL is also addressed. A visual comparison between the URes34P model developed in this work and the existing state of the art in deep learning image enhancement methods, relevant to images captured in space, is presented. Based upon visual inspection, it is determined that our UNet model is capable of correcting for space-related image degradations and merits further investigation to reduce its computational complexity.
Self-Supervised Learning for Place Representation Generalization across Appearance Changes
Mar 09, 2023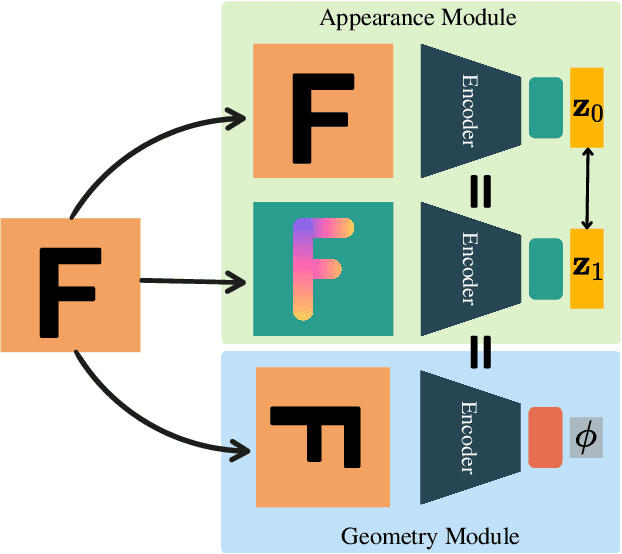
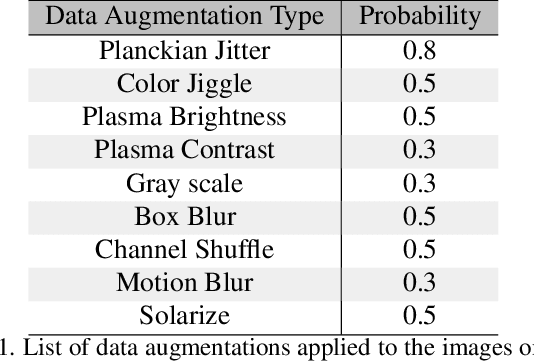

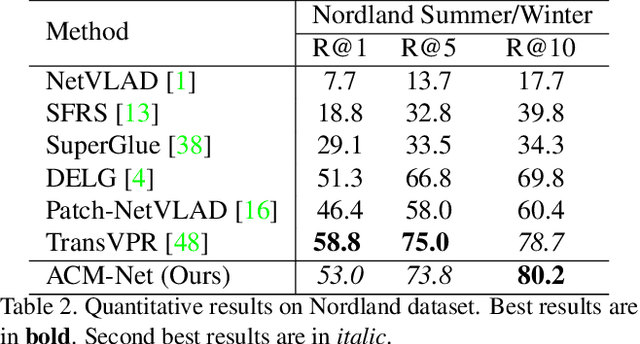
Visual place recognition is a key to unlocking spatial navigation for animals, humans and robots. While state-of-the-art approaches are trained in a supervised manner and therefore hardly capture the information needed for generalizing to unusual conditions, we argue that self-supervised learning may help abstracting the place representation so that it can be foreseen, irrespective of the conditions. More precisely, in this paper, we investigate learning features that are robust to appearance modifications while sensitive to geometric transformations in a self-supervised manner. This dual-purpose training is made possible by combining the two self-supervision main paradigms, \textit{i.e.} contrastive and predictive learning. Our results on standard benchmarks reveal that jointly learning such appearance-robust and geometry-sensitive image descriptors leads to competitive visual place recognition results across adverse seasonal and illumination conditions, without requiring any human-annotated labels.
3D-Aware Object Localization using Gaussian Implicit Occupancy Function
Mar 03, 2023



To automatically localize a target object in an image is crucial for many computer vision applications. Recently ellipse representations have been identified as an alternative to axis-aligned bounding boxes for object localization. This paper considers 3D-aware ellipse labels, i.e., which are projections of a 3D ellipsoidal approximation of the object in the images for 2D target localization. Such generic ellipsoidal models allow for handling coarsely known targets, and 3D-aware ellipse detections carry more geometric information about the object than traditional 3D-agnostic bounding box labels. We propose to have a new look at ellipse regression and replace the geometric ellipse parameters with the parameters of an implicit Gaussian distribution encoding object occupancy in the image. The models are trained to regress the values of this bivariate Gaussian distribution over the image pixels using a continuous statistical loss function. We introduce a novel non-trainable differentiable layer, E-DSNT, to extract the distribution parameters. Also, we describe how to readily generate consistent 3D-aware Gaussian occupancy parameters using only coarse dimensions of the target and relative pose labels. We extend three existing spacecraft pose estimation datasets with 3D-aware Gaussian occupancy labels to validate our hypothesis.
Perspective-1-Ellipsoid: Formulation, Analysis and Solutions of the Ellipsoid Pose Estimation Problem in Euclidean Space
Aug 26, 2022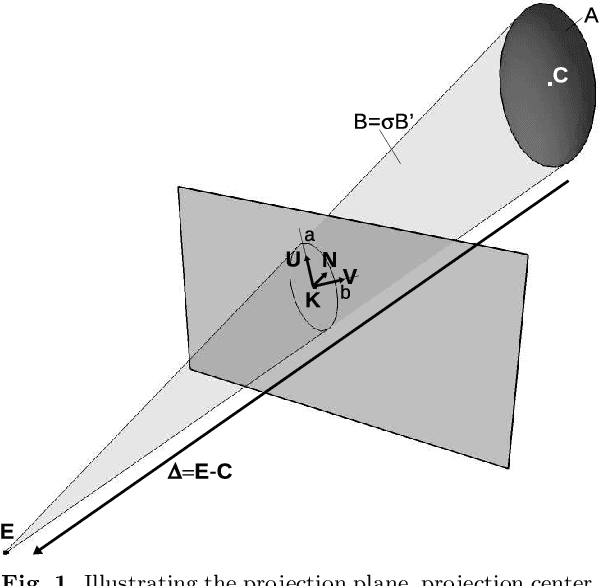


In computer vision, camera pose estimation from correspondences between 3D geometric entities and their projections into the image has been a widely investigated problem. Although most state-of-the-art methods exploit low-level primitives such as points or lines, the emergence of very effective CNN-based object detectors in the recent years has paved the way to the use of higher-level features carrying semantically meaningful information. Pioneering works in that direction have shown that modelling 3D objects by ellipsoids and 2D detections by ellipses offers a convenient manner to link 2D and 3D data. However, the mathematical formalism most often used in the related litterature does not enable to easily distinguish ellipsoids and ellipses from other quadrics and conics, leading to a loss of specificity potentially detrimental in some developments. Moreover, the linearization process of the projection equation creates an over-representation of the camera parameters, also possibly causing an efficiency loss. In this paper, we therefore introduce an ellipsoid-specific theoretical framework and demonstrate its beneficial properties in the context of pose estimation. More precisely, we first show that the proposed formalism enables to reduce the ellipsoid pose estimation problem to a position or orientation-only estimation problem in which the remaining unknowns can be derived in closed-form. Then, we demonstrate that it can be further reduced to a 1 Degree-of-Freedom (1DoF) problem and provide the analytical expression of the pose as a function of that unique scalar unknown. We illustrate our theoretical considerations by visual examples. Finally, we release this work in order to contribute towards more efficient resolutions of ellipsoid-related pose estimation problems.