 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOA-SLAM: Leveraging Objects for Camera Relocalization in Visual SLAM
Sep 17, 2022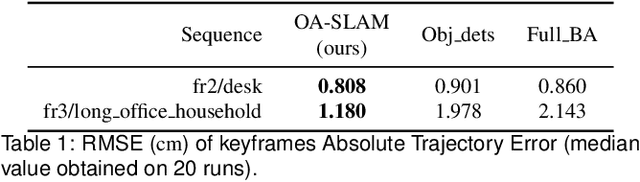



In this work, we explore the use of objects in Simultaneous Localization and Mapping in unseen worlds and propose an object-aided system (OA-SLAM). More precisely, we show that, compared to low-level points, the major benefit of objects lies in their higher-level semantic and discriminating power. Points, on the contrary, have a better spatial localization accuracy than the generic coarse models used to represent objects (cuboid or ellipsoid). We show that combining points and objects is of great interest to address the problem of camera pose recovery. Our main contributions are: (1) we improve the relocalization ability of a SLAM system using high-level object landmarks; (2) we build an automatic system, capable of identifying, tracking and reconstructing objects with 3D ellipsoids; (3) we show that object-based localization can be used to reinitialize or resume camera tracking. Our fully automatic system allows on-the-fly object mapping and enhanced pose tracking recovery, which we think, can significantly benefit to the AR community. Our experiments show that the camera can be relocalized from viewpoints where classical methods fail. We demonstrate that this localization allows a SLAM system to continue working despite a tracking loss, which can happen frequently with an uninitiated user. Our code and test data are released at gitlab.inria.fr/tangram/oa-slam.
Perspective-1-Ellipsoid: Formulation, Analysis and Solutions of the Ellipsoid Pose Estimation Problem in Euclidean Space
Aug 26, 2022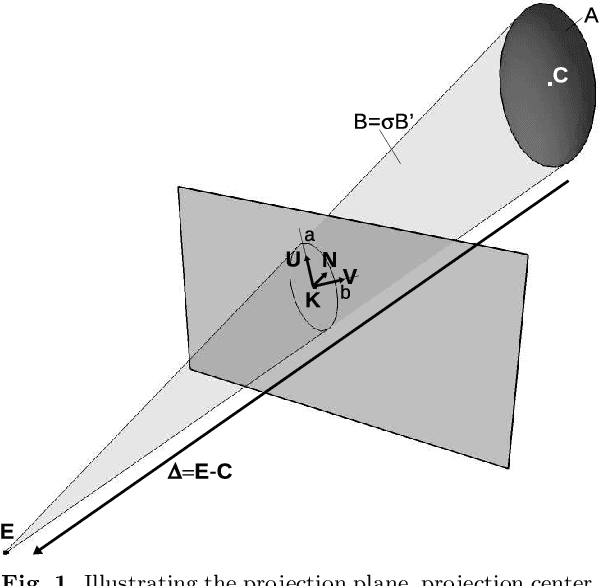


In computer vision, camera pose estimation from correspondences between 3D geometric entities and their projections into the image has been a widely investigated problem. Although most state-of-the-art methods exploit low-level primitives such as points or lines, the emergence of very effective CNN-based object detectors in the recent years has paved the way to the use of higher-level features carrying semantically meaningful information. Pioneering works in that direction have shown that modelling 3D objects by ellipsoids and 2D detections by ellipses offers a convenient manner to link 2D and 3D data. However, the mathematical formalism most often used in the related litterature does not enable to easily distinguish ellipsoids and ellipses from other quadrics and conics, leading to a loss of specificity potentially detrimental in some developments. Moreover, the linearization process of the projection equation creates an over-representation of the camera parameters, also possibly causing an efficiency loss. In this paper, we therefore introduce an ellipsoid-specific theoretical framework and demonstrate its beneficial properties in the context of pose estimation. More precisely, we first show that the proposed formalism enables to reduce the ellipsoid pose estimation problem to a position or orientation-only estimation problem in which the remaining unknowns can be derived in closed-form. Then, we demonstrate that it can be further reduced to a 1 Degree-of-Freedom (1DoF) problem and provide the analytical expression of the pose as a function of that unique scalar unknown. We illustrate our theoretical considerations by visual examples. Finally, we release this work in order to contribute towards more efficient resolutions of ellipsoid-related pose estimation problems.
Level Set-Based Camera Pose Estimation From Multiple 2D/3D Ellipse-Ellipsoid Correspondences
Jul 16, 2022

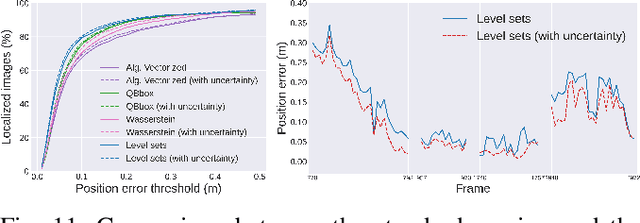

In this paper, we propose an object-based camera pose estimation from a single RGB image and a pre-built map of objects, represented with ellipsoidal models. We show that contrary to point correspondences, the definition of a cost function characterizing the projection of a 3D object onto a 2D object detection is not straightforward. We develop an ellipse-ellipse cost based on level sets sampling, demonstrate its nice properties for handling partially visible objects and compare its performance with other common metrics. Finally, we show that the use of a predictive uncertainty on the detected ellipses allows a fair weighting of the contribution of the correspondences which improves the computed pose. The code is released at https://gitlab.inria.fr/tangram/level-set-based-camera-pose-estimation.
Object-Based Visual Camera Pose Estimation From Ellipsoidal Model and 3D-Aware Ellipse Prediction
Mar 09, 2022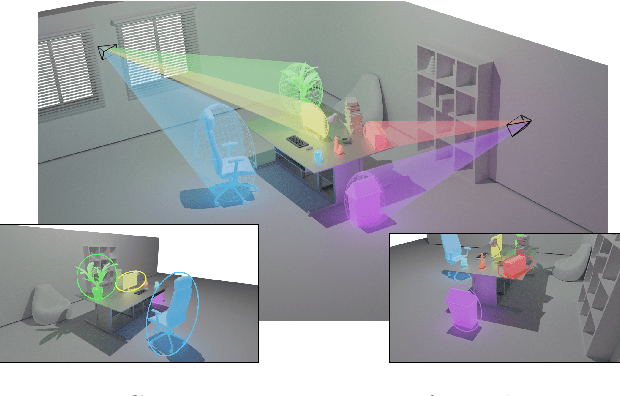

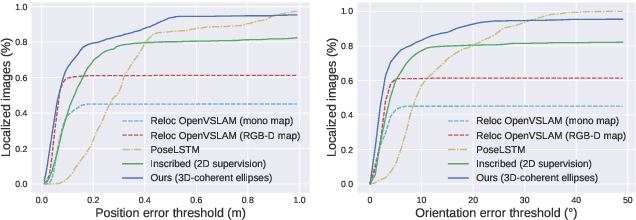

In this paper, we propose a method for initial camera pose estimation from just a single image which is robust to viewing conditions and does not require a detailed model of the scene. This method meets the growing need of easy deployment of robotics or augmented reality applications in any environments, especially those for which no accurate 3D model nor huge amount of ground truth data are available. It exploits the ability of deep learning techniques to reliably detect objects regardless of viewing conditions. Previous works have also shown that abstracting the geometry of a scene of objects by an ellipsoid cloud allows to compute the camera pose accurately enough for various application needs. Though promising, these approaches use the ellipses fitted to the detection bounding boxes as an approximation of the imaged objects. In this paper, we go one step further and propose a learning-based method which detects improved elliptic approximations of objects which are coherent with the 3D ellipsoids in terms of perspective projection. Experiments prove that the accuracy of the computed pose significantly increases thanks to our method. This is achieved with very little effort in terms of training data acquisition - a few hundred calibrated images of which only three need manual object annotation. Code and models are released at https://gitlab.inria.fr/tangram/3d-aware-ellipses-for-visual-localization
3D-Aware Ellipse Prediction for Object-Based Camera Pose Estimation
May 24, 2021

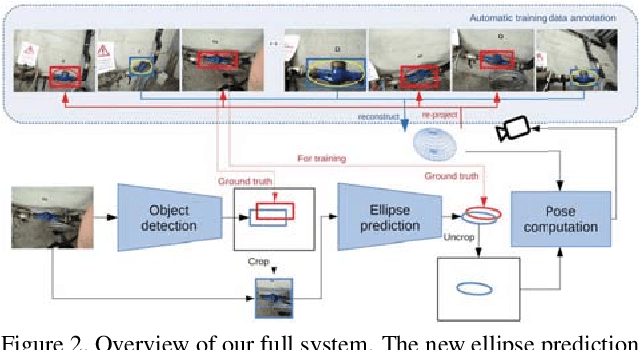
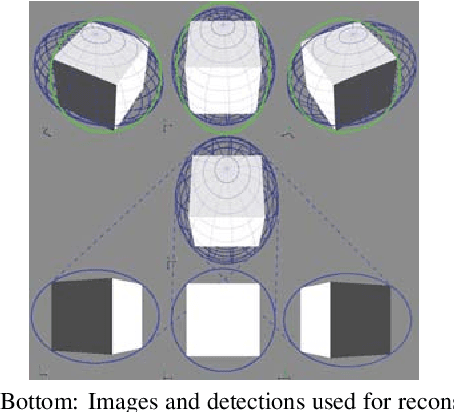
In this paper, we propose a method for coarse camera pose computation which is robust to viewing conditions and does not require a detailed model of the scene. This method meets the growing need of easy deployment of robotics or augmented reality applications in any environments, especially those for which no accurate 3D model nor huge amount of ground truth data are available. It exploits the ability of deep learning techniques to reliably detect objects regardless of viewing conditions. Previous works have also shown that abstracting the geometry of a scene of objects by an ellipsoid cloud allows to compute the camera pose accurately enough for various application needs. Though promising, these approaches use the ellipses fitted to the detection bounding boxes as an approximation of the imaged objects. In this paper, we go one step further and propose a learning-based method which detects improved elliptic approximations of objects which are coherent with the 3D ellipsoid in terms of perspective projection. Experiments prove that the accuracy of the computed pose significantly increases thanks to our method and is more robust to the variability of the boundaries of the detection boxes. This is achieved with very little effort in terms of training data acquisition -- a few hundred calibrated images of which only three need manual object annotation. Code and models are released at https://github.com/zinsmatt/3D-Aware-Ellipses-for-Visual-Localization.
* Presented at 3DV 2020. Code and models released at https://github.com/zinsmatt/3D-Aware-Ellipses-for-Visual-Localization
Elastic registration based on compliance analysis and biomechanical graph matching
Dec 13, 2019

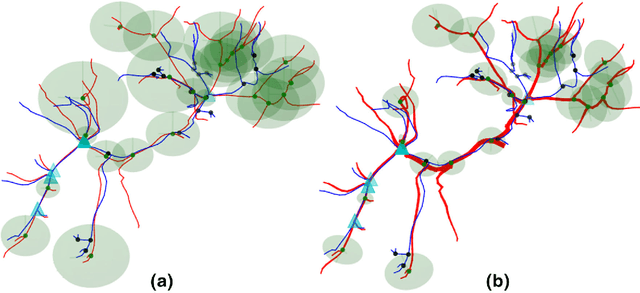

An automatic elastic registration method suited for vascularized organs is proposed. The vasculature in both the preoperative and intra-operative images is represented as a graph. A typical application of this method is the fusion of pre-operative information onto the organ during surgery, to compensate for the limited details provided by the intra-operative imaging modality (e.g. CBCT) and to cope with changes in the shape of the organ. Due to image modalities differences and organ deformation, each graph has a different topology and shape. The Adaptive Compliance Graph Matching (ACGM) method presented does not require any manual initialization, handles intra-operative nonrigid deformations of up to 65 mm and computes a complete displacement field over the organ from only the matched vasculature. ACGM is better than the previous Biomechanical Graph Matching method 3 (BGM) because it uses an efficient biomechanical vascularized liver model to compute the organ's transformation and the vessels bifurcations compliance. This allows to efficiently find the best graph matches with a novel compliance-based adaptive search. These contributions are evaluated on ten realistic synthetic and two real porcine automatically segmented datasets. ACGM obtains better target registration error (TRE) than BGM, with an average TRE in the real datasets of 4.2 mm compared to 6.5 mm, respectively. It also is up to one order of magnitude faster, less dependent on the parameters used and more robust to noise.