 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Attention for Robust RGB-T Pedestrian Detection in Real-World Conditions
Nov 06, 2024



Multispectral pedestrian detection has gained significant attention in recent years, particularly in autonomous driving applications. To address the challenges posed by adversarial illumination conditions, the combination of thermal and visible images has demonstrated its advantages. However, existing fusion methods rely on the critical assumption that the RGB-Thermal (RGB-T) image pairs are fully overlapping. These assumptions often do not hold in real-world applications, where only partial overlap between images can occur due to sensors configuration. Moreover, sensor failure can cause loss of information in one modality. In this paper, we propose a novel module called the Hybrid Attention (HA) mechanism as our main contribution to mitigate performance degradation caused by partial overlap and sensor failure, i.e. when at least part of the scene is acquired by only one sensor. We propose an improved RGB-T fusion algorithm, robust against partial overlap and sensor failure encountered during inference in real-world applications. We also leverage a mobile-friendly backbone to cope with resource constraints in embedded systems. We conducted experiments by simulating various partial overlap and sensor failure scenarios to evaluate the performance of our proposed method. The results demonstrate that our approach outperforms state-of-the-art methods, showcasing its superiority in handling real-world challenges.
A Survey on Deep Learning-Based Monocular Spacecraft Pose Estimation: Current State, Limitations and Prospects
May 17, 2023



Estimating the pose of an uncooperative spacecraft is an important computer vision problem for enabling the deployment of automatic vision-based systems in orbit, with applications ranging from on-orbit servicing to space debris removal. Following the general trend in computer vision, more and more works have been focusing on leveraging Deep Learning (DL) methods to address this problem. However and despite promising research-stage results, major challenges preventing the use of such methods in real-life missions still stand in the way. In particular, the deployment of such computation-intensive algorithms is still under-investigated, while the performance drop when training on synthetic and testing on real images remains to mitigate. The primary goal of this survey is to describe the current DL-based methods for spacecraft pose estimation in a comprehensive manner. The secondary goal is to help define the limitations towards the effective deployment of DL-based spacecraft pose estimation solutions for reliable autonomous vision-based applications. To this end, the survey first summarises the existing algorithms according to two approaches: hybrid modular pipelines and direct end-to-end regression methods. A comparison of algorithms is presented not only in terms of pose accuracy but also with a focus on network architectures and models' sizes keeping potential deployment in mind. Then, current monocular spacecraft pose estimation datasets used to train and test these methods are discussed. The data generation methods: simulators and testbeds, the domain gap and the performance drop between synthetically generated and lab/space collected images and the potential solutions are also discussed. Finally, the paper presents open research questions and future directions in the field, drawing parallels with other computer vision applications.
3D-Aware Object Localization using Gaussian Implicit Occupancy Function
Mar 03, 2023



To automatically localize a target object in an image is crucial for many computer vision applications. Recently ellipse representations have been identified as an alternative to axis-aligned bounding boxes for object localization. This paper considers 3D-aware ellipse labels, i.e., which are projections of a 3D ellipsoidal approximation of the object in the images for 2D target localization. Such generic ellipsoidal models allow for handling coarsely known targets, and 3D-aware ellipse detections carry more geometric information about the object than traditional 3D-agnostic bounding box labels. We propose to have a new look at ellipse regression and replace the geometric ellipse parameters with the parameters of an implicit Gaussian distribution encoding object occupancy in the image. The models are trained to regress the values of this bivariate Gaussian distribution over the image pixels using a continuous statistical loss function. We introduce a novel non-trainable differentiable layer, E-DSNT, to extract the distribution parameters. Also, we describe how to readily generate consistent 3D-aware Gaussian occupancy parameters using only coarse dimensions of the target and relative pose labels. We extend three existing spacecraft pose estimation datasets with 3D-aware Gaussian occupancy labels to validate our hypothesis.
Lessons from a Space Lab -- An Image Acquisition Perspective
Aug 18, 2022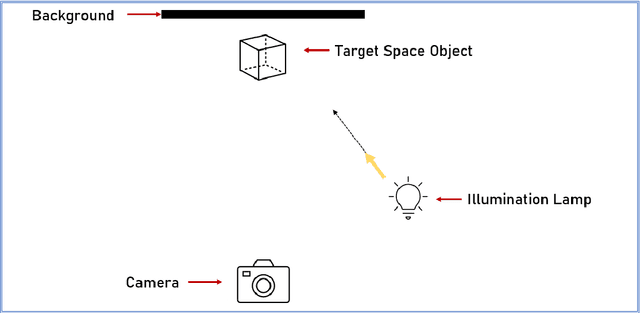
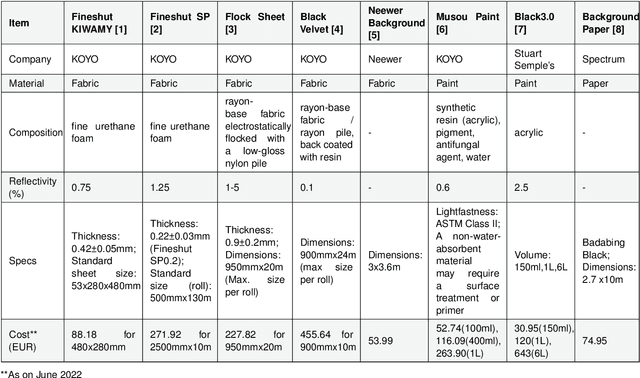
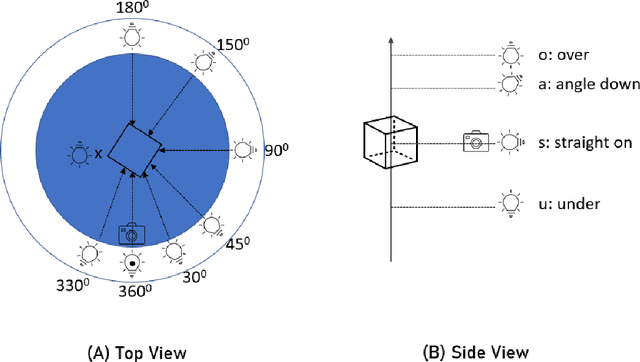
The use of Deep Learning (DL) algorithms has improved the performance of vision-based space applications in recent years. However, generating large amounts of annotated data for training these DL algorithms has proven challenging. While synthetically generated images can be used, the DL models trained on synthetic data are often susceptible to performance degradation, when tested in real-world environments. In this context, the Interdisciplinary Center of Security, Reliability and Trust (SnT) at the University of Luxembourg has developed the 'SnT Zero-G Lab', for training and validating vision-based space algorithms in conditions emulating real-world space environments. An important aspect of the SnT Zero-G Lab development was the equipment selection. From the lessons learned during the lab development, this article presents a systematic approach combining market survey and experimental analyses for equipment selection. In particular, the article focus on the image acquisition equipment in a space lab: background materials, cameras and illumination lamps. The results from the experiment analyses show that the market survey complimented by experimental analyses is required for effective equipment selection in a space lab development project.
One-Shot Observation Learning
Oct 17, 2018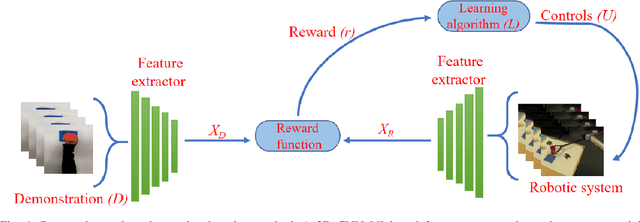
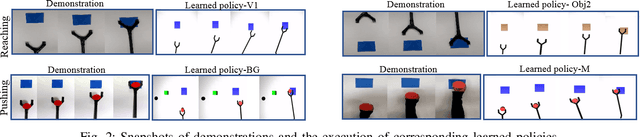
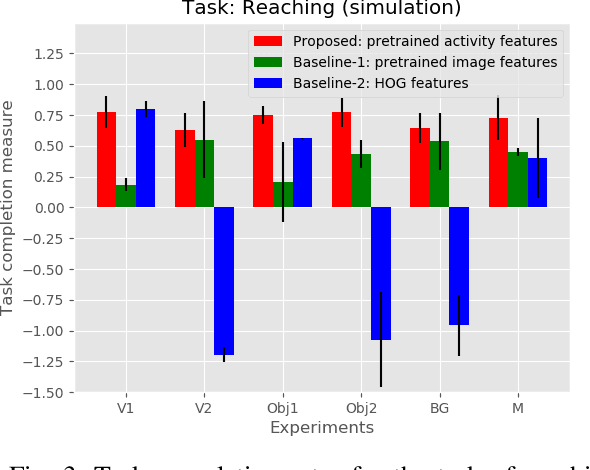
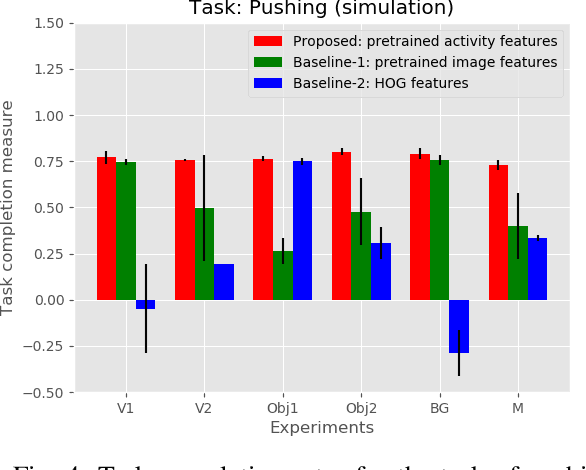
Observation learning is the process of learning a task by observing an expert demonstrator. We present a robust observation learning method for robotic systems. Our principle contributions are in introducing a one shot learning method where only a single demonstration is needed for learning and in proposing a novel feature extraction method for extracting unique activity features from the demonstration. Reward values are then generated from these demonstrations. We use a learning algorithm with these rewards to learn the controls for a robotic manipulator to perform the demonstrated task. With simulation and real robot experiments, we show that the proposed method can be used to learn tasks from a single demonstration under varying conditions of viewpoints, object properties, morphology of manipulators and scene backgrounds.
Defining the problem of Observation Learning
Oct 16, 2018



This article defines and formulates the problem of observation learning in robotic systems.