 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedTalk: Triplane-Free Talking Head Synthesis using Embedding-Driven Gaussian Deformation
Mar 08, 2026Real-time talking head synthesis increasingly relies on deformable 3D Gaussian Splatting (3DGS) due to its low latency. Tri-planes are the standard choice for encoding Gaussians prior to deformation, since they provide a continuous domain with explicit spatial relationships. However, tri-plane representations are limited by grid resolution and approximation errors introduced by projecting 3D volumetric fields onto 2D subspaces. Recent work has shown the superiority of learnt embeddings for driving temporal deformations in 4D scene reconstruction. We introduce $\textbf{EmbedTalk}$, which shows how such embeddings can be leveraged for modelling speech deformations in talking head synthesis. Through comprehensive experiments, we show that EmbedTalk outperforms existing 3DGS-based methods in rendering quality, lip synchronisation, and motion consistency, while remaining competitive with state-of-the-art generative models. Moreover, replacing the tri-plane encoding with learnt embeddings enables significantly more compact models that achieve over 60 FPS on a mobile GPU (RTX 2060 6 GB). Our code will be placed in the public domain on acceptance.
Score Before You Speak: Improving Persona Consistency in Dialogue Generation using Response Quality Scores
Aug 09, 2025


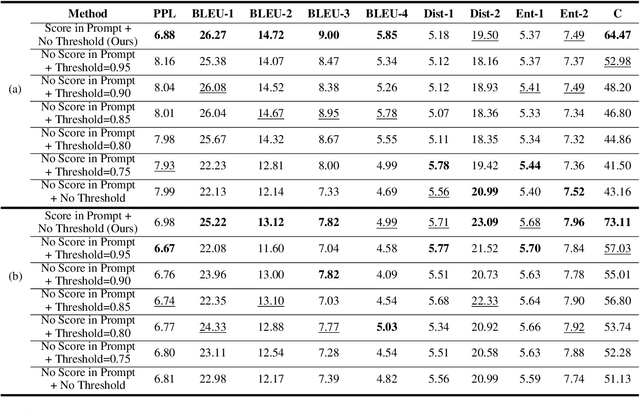
Persona-based dialogue generation is an important milestone towards building conversational artificial intelligence. Despite the ever-improving capabilities of large language models (LLMs), effectively integrating persona fidelity in conversations remains challenging due to the limited diversity in existing dialogue data. We propose a novel framework SBS (Score-Before-Speaking), which outperforms previous methods and yields improvements for both million and billion-parameter models. Unlike previous methods, SBS unifies the learning of responses and their relative quality into a single step. The key innovation is to train a dialogue model to correlate augmented responses with a quality score during training and then leverage this knowledge at inference. We use noun-based substitution for augmentation and semantic similarity-based scores as a proxy for response quality. Through extensive experiments with benchmark datasets (PERSONA-CHAT and ConvAI2), we show that score-conditioned training allows existing models to better capture a spectrum of persona-consistent dialogues. Our ablation studies also demonstrate that including scores in the input prompt during training is superior to conventional training setups. Code and further details are available at https://arpita2512.github.io/score_before_you_speak
Reframing Spatial Reasoning Evaluation in Language Models: A Real-World Simulation Benchmark for Qualitative Reasoning
May 23, 2024



Spatial reasoning plays a vital role in both human cognition and machine intelligence, prompting new research into language models' (LMs) capabilities in this regard. However, existing benchmarks reveal shortcomings in evaluating qualitative spatial reasoning (QSR). These benchmarks typically present oversimplified scenarios or unclear natural language descriptions, hindering effective evaluation. We present a novel benchmark for assessing QSR in LMs, which is grounded in realistic 3D simulation data, offering a series of diverse room layouts with various objects and their spatial relationships. This approach provides a more detailed and context-rich narrative for spatial reasoning evaluation, diverging from traditional, toy-task-oriented scenarios. Our benchmark encompasses a broad spectrum of qualitative spatial relationships, including topological, directional, and distance relations. These are presented with different viewing points, varied granularities, and density of relation constraints to mimic real-world complexities. A key contribution is our logic-based consistency-checking tool, which enables the assessment of multiple plausible solutions, aligning with real-world scenarios where spatial relationships are often open to interpretation. Our benchmark evaluation of advanced LMs reveals their strengths and limitations in spatial reasoning. They face difficulties with multi-hop spatial reasoning and interpreting a mix of different view descriptions, pointing to areas for future improvement.
Advancing Spatial Reasoning in Large Language Models: An In-Depth Evaluation and Enhancement Using the StepGame Benchmark
Jan 08, 2024



Artificial intelligence (AI) has made remarkable progress across various domains, with large language models like ChatGPT gaining substantial attention for their human-like text-generation capabilities. Despite these achievements, spatial reasoning remains a significant challenge for these models. Benchmarks like StepGame evaluate AI spatial reasoning, where ChatGPT has shown unsatisfactory performance. However, the presence of template errors in the benchmark has an impact on the evaluation results. Thus there is potential for ChatGPT to perform better if these template errors are addressed, leading to more accurate assessments of its spatial reasoning capabilities. In this study, we refine the StepGame benchmark, providing a more accurate dataset for model evaluation. We analyze GPT's spatial reasoning performance on the rectified benchmark, identifying proficiency in mapping natural language text to spatial relations but limitations in multi-hop reasoning. We provide a flawless solution to the benchmark by combining template-to-relation mapping with logic-based reasoning. This combination demonstrates proficiency in performing qualitative reasoning on StepGame without encountering any errors. We then address the limitations of GPT models in spatial reasoning. We deploy Chain-of-thought and Tree-of-thoughts prompting strategies, offering insights into GPT's ``cognitive process", and achieving remarkable improvements in accuracy. Our investigation not only sheds light on model deficiencies but also proposes enhancements, contributing to the advancement of AI with more robust spatial reasoning capabilities.
Bayesian uncertainty-weighted loss for improved generalisability on polyp segmentation task
Sep 13, 2023



While several previous studies have devised methods for segmentation of polyps, most of these methods are not rigorously assessed on multi-center datasets. Variability due to appearance of polyps from one center to another, difference in endoscopic instrument grades, and acquisition quality result in methods with good performance on in-distribution test data, and poor performance on out-of-distribution or underrepresented samples. Unfair models have serious implications and pose a critical challenge to clinical applications. We adapt an implicit bias mitigation method which leverages Bayesian epistemic uncertainties during training to encourage the model to focus on underrepresented sample regions. We demonstrate the potential of this approach to improve generalisability without sacrificing state-of-the-art performance on a challenging multi-center polyp segmentation dataset (PolypGen) with different centers and image modalities.
3D shape reconstruction of semi-transparent worms
Apr 28, 2023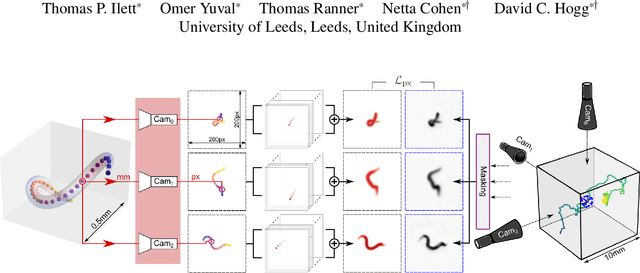
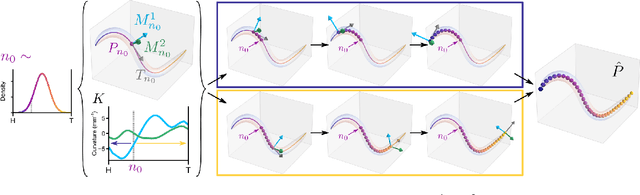
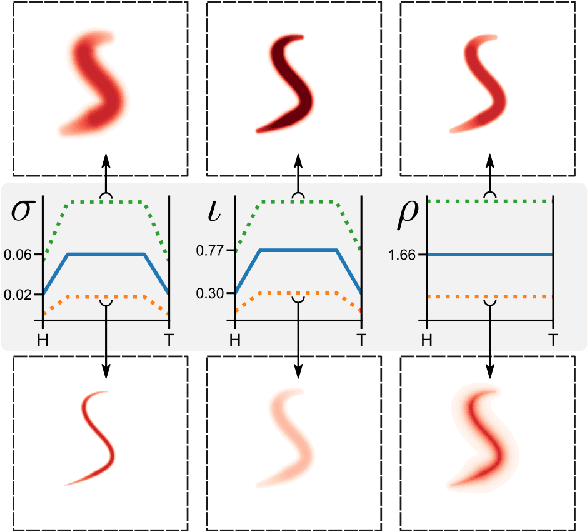
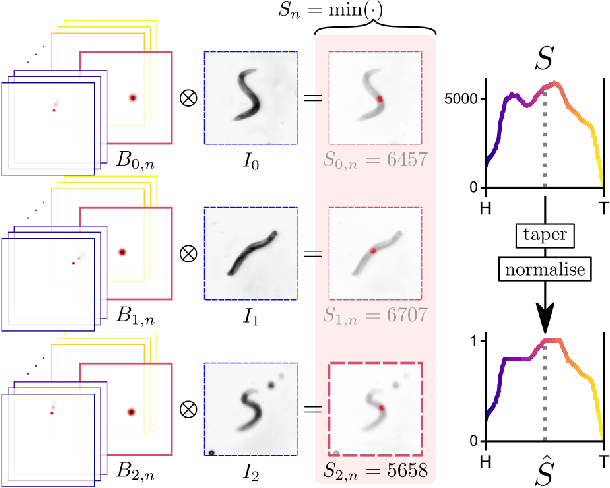
3D shape reconstruction typically requires identifying object features or textures in multiple images of a subject. This approach is not viable when the subject is semi-transparent and moving in and out of focus. Here we overcome these challenges by rendering a candidate shape with adaptive blurring and transparency for comparison with the images. We use the microscopic nematode Caenorhabditis elegans as a case study as it freely explores a 3D complex fluid with constantly changing optical properties. We model the slender worm as a 3D curve using an intrinsic parametrisation that naturally admits biologically-informed constraints and regularisation. To account for the changing optics we develop a novel differentiable renderer to construct images from 2D projections and compare against raw images to generate a pixel-wise error to jointly update the curve, camera and renderer parameters using gradient descent. The method is robust to interference such as bubbles and dirt trapped in the fluid, stays consistent through complex sequences of postures, recovers reliable estimates from blurry images and provides a significant improvement on previous attempts to track C. elegans in 3D. Our results demonstrate the potential of direct approaches to shape estimation in complex physical environments in the absence of ground-truth data.
Talking Head from Speech Audio using a Pre-trained Image Generator
Sep 09, 2022
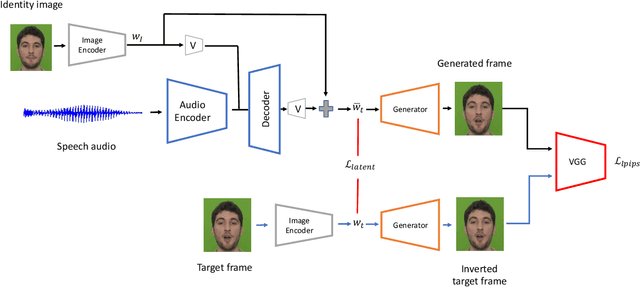
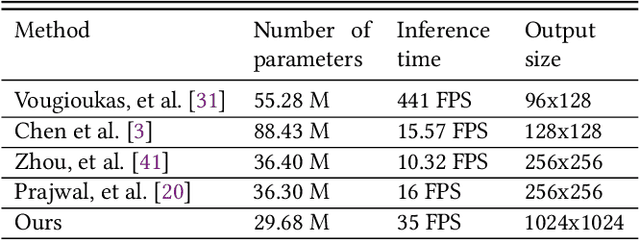

We propose a novel method for generating high-resolution videos of talking-heads from speech audio and a single 'identity' image. Our method is based on a convolutional neural network model that incorporates a pre-trained StyleGAN generator. We model each frame as a point in the latent space of StyleGAN so that a video corresponds to a trajectory through the latent space. Training the network is in two stages. The first stage is to model trajectories in the latent space conditioned on speech utterances. To do this, we use an existing encoder to invert the generator, mapping from each video frame into the latent space. We train a recurrent neural network to map from speech utterances to displacements in the latent space of the image generator. These displacements are relative to the back-projection into the latent space of an identity image chosen from the individuals depicted in the training dataset. In the second stage, we improve the visual quality of the generated videos by tuning the image generator on a single image or a short video of any chosen identity. We evaluate our model on standard measures (PSNR, SSIM, FID and LMD) and show that it significantly outperforms recent state-of-the-art methods on one of two commonly used datasets and gives comparable performance on the other. Finally, we report on ablation experiments that validate the components of the model. The code and videos from experiments can be found at https://mohammedalghamdi.github.io/talking-heads-acm-mm
Exploring the GLIDE model for Human Action-effect Prediction
Aug 01, 2022



We address the following action-effect prediction task. Given an image depicting an initial state of the world and an action expressed in text, predict an image depicting the state of the world following the action. The prediction should have the same scene context as the input image. We explore the use of the recently proposed GLIDE model for performing this task. GLIDE is a generative neural network that can synthesize (inpaint) masked areas of an image, conditioned on a short piece of text. Our idea is to mask-out a region of the input image where the effect of the action is expected to occur. GLIDE is then used to inpaint the masked region conditioned on the required action. In this way, the resulting image has the same background context as the input image, updated to show the effect of the action. We give qualitative results from experiments using the EPIC dataset of ego-centric videos labelled with actions.
One-Shot Observation Learning
Oct 17, 2018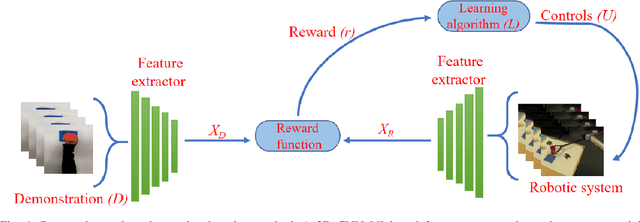
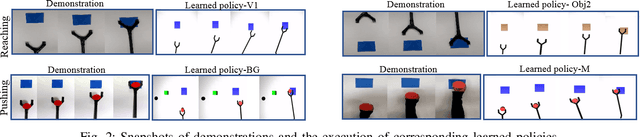
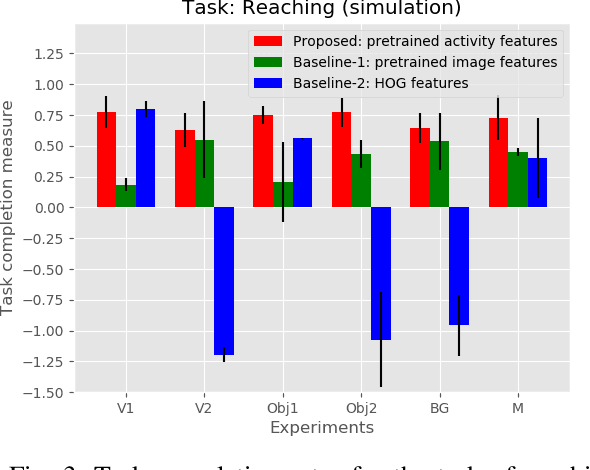
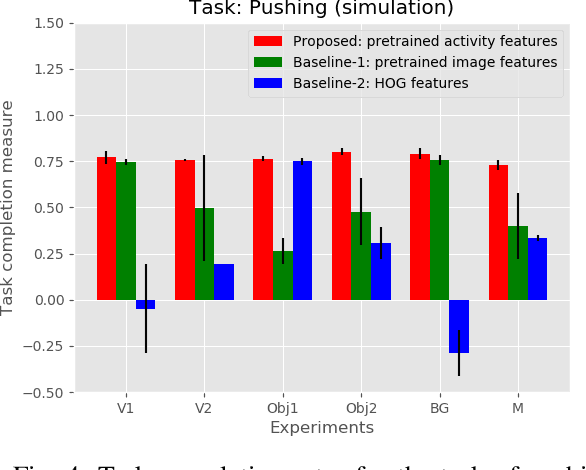
Observation learning is the process of learning a task by observing an expert demonstrator. We present a robust observation learning method for robotic systems. Our principle contributions are in introducing a one shot learning method where only a single demonstration is needed for learning and in proposing a novel feature extraction method for extracting unique activity features from the demonstration. Reward values are then generated from these demonstrations. We use a learning algorithm with these rewards to learn the controls for a robotic manipulator to perform the demonstrated task. With simulation and real robot experiments, we show that the proposed method can be used to learn tasks from a single demonstration under varying conditions of viewpoints, object properties, morphology of manipulators and scene backgrounds.
CLAD: A Complex and Long Activities Dataset with Rich Crowdsourced Annotations
Sep 21, 2017
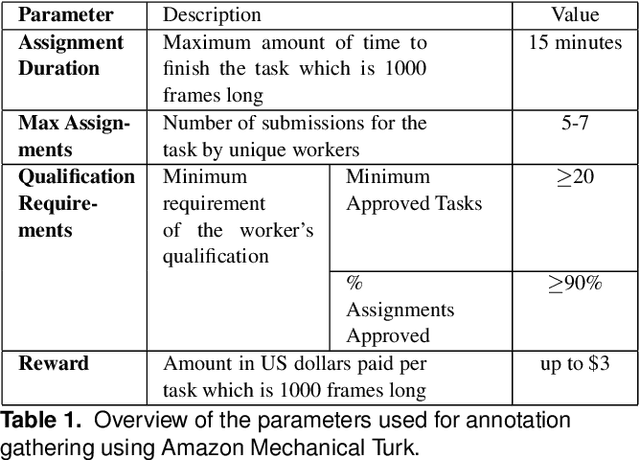
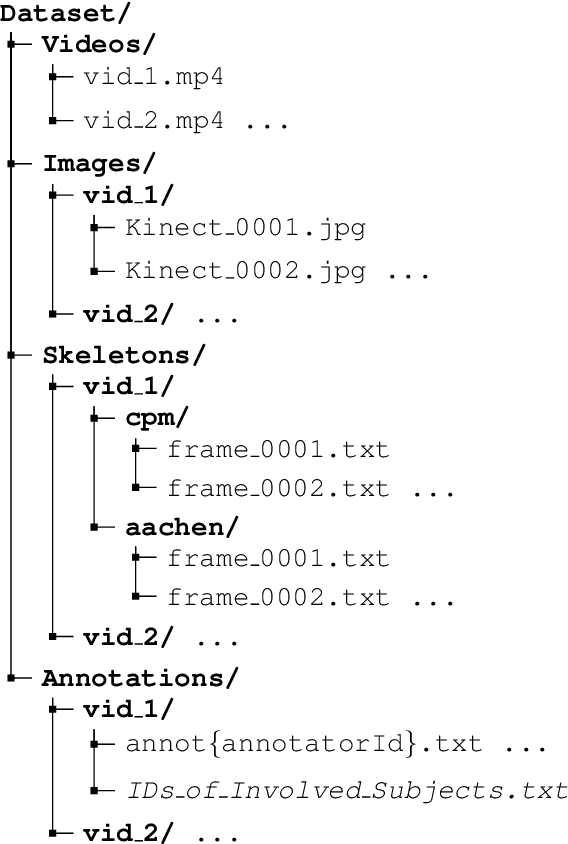
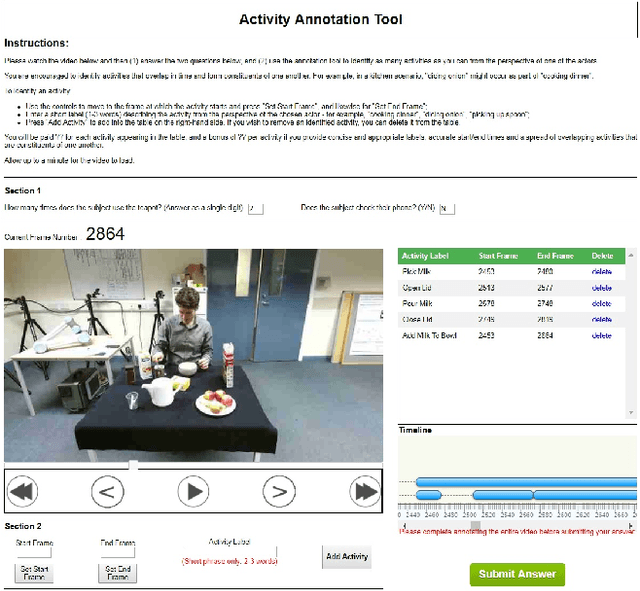
This paper introduces a novel activity dataset which exhibits real-life and diverse scenarios of complex, temporally-extended human activities and actions. The dataset presents a set of videos of actors performing everyday activities in a natural and unscripted manner. The dataset was recorded using a static Kinect 2 sensor which is commonly used on many robotic platforms. The dataset comprises of RGB-D images, point cloud data, automatically generated skeleton tracks in addition to crowdsourced annotations. Furthermore, we also describe the methodology used to acquire annotations through crowdsourcing. Finally some activity recognition benchmarks are presented using current state-of-the-art techniques. We believe that this dataset is particularly suitable as a testbed for activity recognition research but it can also be applicable for other common tasks in robotics/computer vision research such as object detection and human skeleton tracking.