 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect, Classify, Act: Categorizing Industrial Anomalies with Multi-Modal Large Language Models
May 05, 2025Recent advances in visual industrial anomaly detection have demonstrated exceptional performance in identifying and segmenting anomalous regions while maintaining fast inference speeds. However, anomaly classification-distinguishing different types of anomalies-remains largely unexplored despite its critical importance in real-world inspection tasks. To address this gap, we propose VELM, a novel LLM-based pipeline for anomaly classification. Given the critical importance of inference speed, we first apply an unsupervised anomaly detection method as a vision expert to assess the normality of an observation. If an anomaly is detected, the LLM then classifies its type. A key challenge in developing and evaluating anomaly classification models is the lack of precise annotations of anomaly classes in existing datasets. To address this limitation, we introduce MVTec-AC and VisA-AC, refined versions of the widely used MVTec-AD and VisA datasets, which include accurate anomaly class labels for rigorous evaluation. Our approach achieves a state-of-the-art anomaly classification accuracy of 80.4% on MVTec-AD, exceeding the prior baselines by 5%, and 84% on MVTec-AC, demonstrating the effectiveness of VELM in understanding and categorizing anomalies. We hope our methodology and benchmark inspire further research in anomaly classification, helping bridge the gap between detection and comprehensive anomaly characterization.
D3AD: Dynamic Denoising Diffusion Probabilistic Model for Anomaly Detection
Jan 09, 2024Diffusion models have found valuable applications in anomaly detection by capturing the nominal data distribution and identifying anomalies via reconstruction. Despite their merits, they struggle to localize anomalies of varying scales, especially larger anomalies like entire missing components. Addressing this, we present a novel framework that enhances the capability of diffusion models, by extending the previous introduced implicit conditioning approach Meng et al. (2022) in three significant ways. First, we incorporate a dynamic step size computation that allows for variable noising steps in the forward process guided by an initial anomaly prediction. Second, we demonstrate that denoising an only scaled input, without any added noise, outperforms conventional denoising process. Third, we project images in a latent space to abstract away from fine details that interfere with reconstruction of large missing components. Additionally, we propose a fine-tuning mechanism that facilitates the model to effectively grasp the nuances of the target domain. Our method undergoes rigorous evaluation on two prominent anomaly detection datasets VISA and BTAD, yielding state-of-the-art performance. Importantly, our framework effectively localizes anomalies regardless of their scale, marking a pivotal advancement in diffusion-based anomaly detection.
Anomaly Detection with Conditioned Denoising Diffusion Models
May 25, 2023Reconstruction-based methods have struggled to achieve competitive performance on anomaly detection. In this paper, we introduce Denoising Diffusion Anomaly Detection (DDAD). We propose a novel denoising process for image reconstruction conditioned on a target image. This results in a coherent restoration that closely resembles the target image. Subsequently, our anomaly detection framework leverages this conditioning where the target image is set as the input image to guide the denoising process, leading to defectless reconstruction while maintaining nominal patterns. We localise anomalies via a pixel-wise and feature-wise comparison of the input and reconstructed image. Finally, to enhance the effectiveness of feature comparison, we introduce a domain adaptation method that utilises generated examples from our conditioned denoising process to fine-tune the feature extractor. The veracity of the approach is demonstrated on various datasets including MVTec and VisA benchmarks, achieving state-of-the-art results of 99.5% and 99.3% image-level AUROC respectively.
FullFormer: Generating Shapes Inside Shapes
Mar 20, 2023Implicit generative models have been widely employed to model 3D data and have recently proven to be successful in encoding and generating high-quality 3D shapes. This work builds upon these models and alleviates current limitations by presenting the first implicit generative model that facilitates the generation of complex 3D shapes with rich internal geometric details. To achieve this, our model uses unsigned distance fields to represent nested 3D surfaces allowing learning from non-watertight mesh data. We propose a transformer-based autoregressive model for 3D shape generation that leverages context-rich tokens from vector quantized shape embeddings. The generated tokens are decoded into an unsigned distance field which is rendered into a novel 3D shape exhibiting a rich internal structure. We demonstrate that our model achieves state-of-the-art point cloud generation results on popular classes of 'Cars', 'Planes', and 'Chairs' of the ShapeNet dataset. Additionally, we curate a dataset that exclusively comprises shapes with realistic internal details from the `Cars' class of ShapeNet and demonstrate our method's efficacy in generating these shapes with internal geometry.
Explaining Deep Neural Networks for Point Clouds using Gradient-based Visualisations
Jul 26, 2022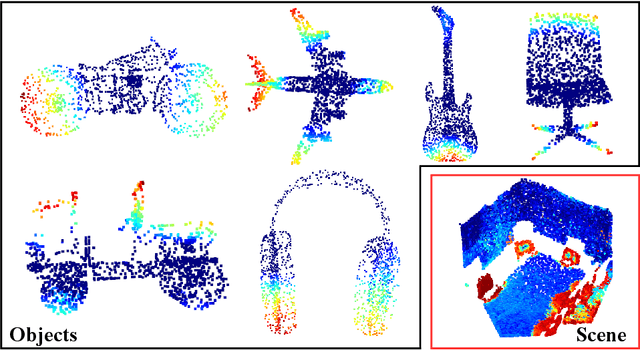
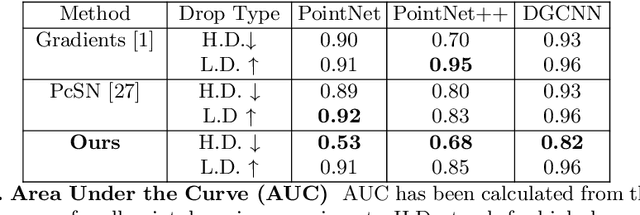


Explaining decisions made by deep neural networks is a rapidly advancing research topic. In recent years, several approaches have attempted to provide visual explanations of decisions made by neural networks designed for structured 2D image input data. In this paper, we propose a novel approach to generate coarse visual explanations of networks designed to classify unstructured 3D data, namely point clouds. Our method uses gradients flowing back to the final feature map layers and maps these values as contributions of the corresponding points in the input point cloud. Due to dimensionality disagreement and lack of spatial consistency between input points and final feature maps, our approach combines gradients with points dropping to compute explanations of different parts of the point cloud iteratively. The generality of our approach is tested on various point cloud classification networks, including 'single object' networks PointNet, PointNet++, DGCNN, and a 'scene' network VoteNet. Our method generates symmetric explanation maps that highlight important regions and provide insight into the decision-making process of network architectures. We perform an exhaustive evaluation of trust and interpretability of our explanation method against comparative approaches using quantitative, quantitative and human studies. All our code is implemented in PyTorch and will be made publicly available.
CLAD: A Complex and Long Activities Dataset with Rich Crowdsourced Annotations
Sep 21, 2017
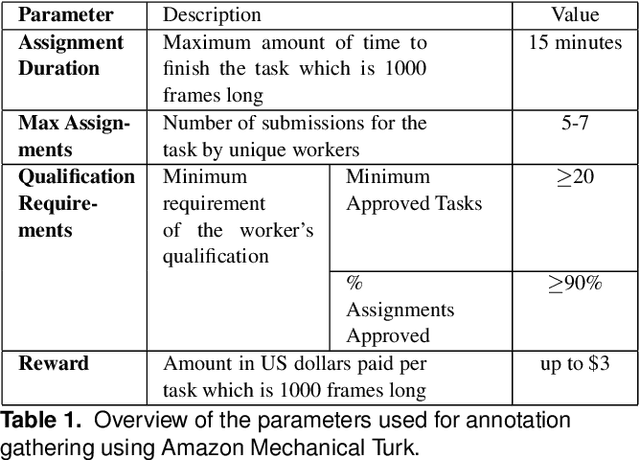
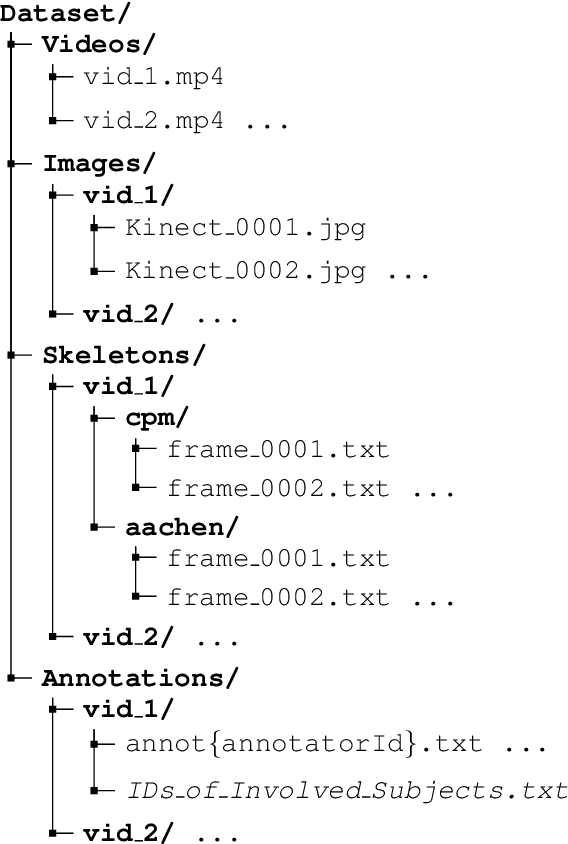
This paper introduces a novel activity dataset which exhibits real-life and diverse scenarios of complex, temporally-extended human activities and actions. The dataset presents a set of videos of actors performing everyday activities in a natural and unscripted manner. The dataset was recorded using a static Kinect 2 sensor which is commonly used on many robotic platforms. The dataset comprises of RGB-D images, point cloud data, automatically generated skeleton tracks in addition to crowdsourced annotations. Furthermore, we also describe the methodology used to acquire annotations through crowdsourcing. Finally some activity recognition benchmarks are presented using current state-of-the-art techniques. We believe that this dataset is particularly suitable as a testbed for activity recognition research but it can also be applicable for other common tasks in robotics/computer vision research such as object detection and human skeleton tracking.