 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegDesicNet: Lightweight Semantic Segmentation in Remote Sensing with Geo-Coordinate Embeddings for Domain Adaptation
Mar 11, 2025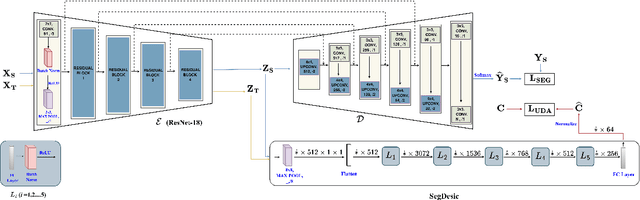

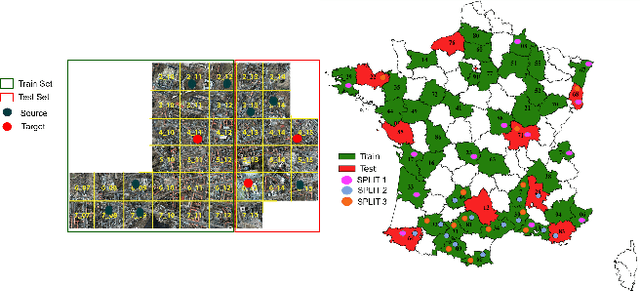
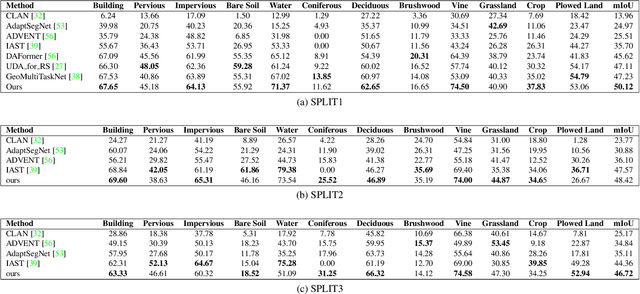
Semantic segmentation is essential for analyzing highdefinition remote sensing images (HRSIs) because it allows the precise classification of objects and regions at the pixel level. However, remote sensing data present challenges owing to geographical location, weather, and environmental variations, making it difficult for semantic segmentation models to generalize across diverse scenarios. Existing methods are often limited to specific data domains and require expert annotators and specialized equipment for semantic labeling. In this study, we propose a novel unsupervised domain adaptation technique for remote sensing semantic segmentation by utilizing geographical coordinates that are readily accessible in remote sensing setups as metadata in a dataset. To bridge the domain gap, we propose a novel approach that considers the combination of an image\'s location encoding trait and the spherical nature of Earth\'s surface. Our proposed SegDesicNet module regresses the GRID positional encoding of the geo coordinates projected over the unit sphere to obtain the domain loss. Our experimental results demonstrate that the proposed SegDesicNet outperforms state of the art domain adaptation methods in remote sensing image segmentation, achieving an improvement of approximately ~6% in the mean intersection over union (MIoU) with a ~ 27\% drop in parameter count on benchmarked subsets of the publicly available FLAIR #1 dataset. We also benchmarked our method performance on the custom split of the ISPRS Potsdam dataset. Our algorithm seeks to reduce the modeling disparity between artificial neural networks and human comprehension of the physical world, making the technology more human centric and scalable.
* https://openaccess.thecvf.com/content/WACV2025/papers/Verma_SegDesicNet_Lightweight_Semantic_Segmentation_in_Remote_Sensing_with_Geo-Coordinate_Embeddings_WACV_2025_paper.pdf
Deep HM-SORT: Enhancing Multi-Object Tracking in Sports with Deep Features, Harmonic Mean, and Expansion IOU
Jun 17, 2024
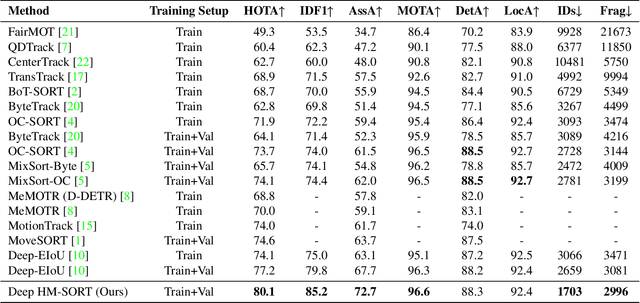


This paper introduces Deep HM-SORT, a novel online multi-object tracking algorithm specifically designed to enhance the tracking of athletes in sports scenarios. Traditional multi-object tracking methods often struggle with sports environments due to the similar appearances of players, irregular and unpredictable movements, and significant camera motion. Deep HM-SORT addresses these challenges by integrating deep features, harmonic mean, and Expansion IOU. By leveraging the harmonic mean, our method effectively balances appearance and motion cues, significantly reducing ID-swaps. Additionally, our approach retains all tracklets indefinitely, improving the re-identification of players who leave and re-enter the frame. Experimental results demonstrate that Deep HM-SORT achieves state-of-the-art performance on two large-scale public benchmarks, SportsMOT and SoccerNet Tracking Challenge 2023. Specifically, our method achieves 80.1 HOTA on the SportsMOT dataset and 85.4 HOTA on the SoccerNet-Tracking dataset, outperforming existing trackers in key metrics such as HOTA, IDF1, AssA, and MOTA. This robust solution provides enhanced accuracy and reliability for automated sports analytics, offering significant improvements over previous methods without introducing additional computational cost.
Geo-locating Road Objects using Inverse Haversine Formula with NVIDIA Driveworks
Jan 15, 2024Geolocation is integral to the seamless functioning of autonomous vehicles and advanced traffic monitoring infrastructures. This paper introduces a methodology to geolocate road objects using a monocular camera, leveraging the NVIDIA DriveWorks platform. We use the Centimeter Positioning Service (CPOS) and the inverse Haversine formula to geo-locate road objects accurately. The real-time algorithm processing capability of the NVIDIA DriveWorks platform enables instantaneous object recognition and spatial localization for Advanced Driver Assistance Systems (ADAS) and autonomous driving platforms. We present a measurement pipeline suitable for autonomous driving (AD) platforms and provide detailed guidelines for calibrating cameras using NVIDIA DriveWorks. Experiments were carried out to validate the accuracy of the proposed method for geolocating targets in both controlled and dynamic settings. We show that our approach can locate targets with less than 1m error when the AD platform is stationary and less than 4m error at higher speeds (i.e. up to 60km/h) within a 15m radius.
Does Image Anonymization Impact Computer Vision Training?
Jun 08, 2023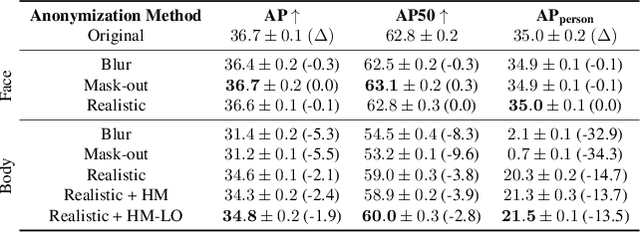

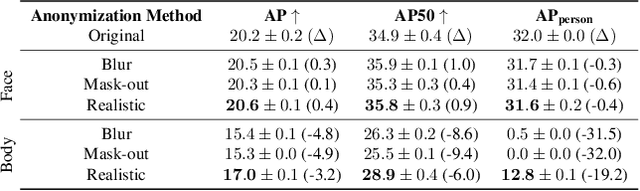

Image anonymization is widely adapted in practice to comply with privacy regulations in many regions. However, anonymization often degrades the quality of the data, reducing its utility for computer vision development. In this paper, we investigate the impact of image anonymization for training computer vision models on key computer vision tasks (detection, instance segmentation, and pose estimation). Specifically, we benchmark the recognition drop on common detection datasets, where we evaluate both traditional and realistic anonymization for faces and full bodies. Our comprehensive experiments reflect that traditional image anonymization substantially impacts final model performance, particularly when anonymizing the full body. Furthermore, we find that realistic anonymization can mitigate this decrease in performance, where our experiments reflect a minimal performance drop for face anonymization. Our study demonstrates that realistic anonymization can enable privacy-preserving computer vision development with minimal performance degradation across a range of important computer vision benchmarks.
Synthesizing Anyone, Anywhere, in Any Pose
Apr 06, 2023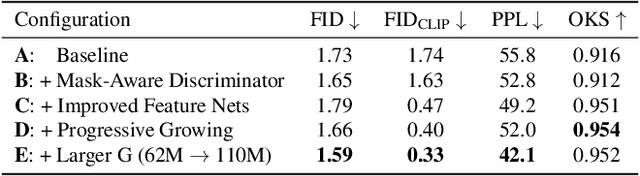
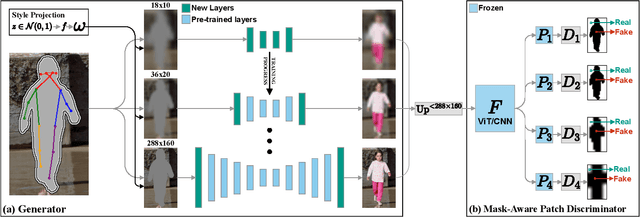

We address the task of in-the-wild human figure synthesis, where the primary goal is to synthesize a full body given any region in any image. In-the-wild human figure synthesis has long been a challenging and under-explored task, where current methods struggle to handle extreme poses, occluding objects, and complex backgrounds. Our main contribution is TriA-GAN, a keypoint-guided GAN that can synthesize Anyone, Anywhere, in Any given pose. Key to our method is projected GANs combined with a well-crafted training strategy, where our simple generator architecture can successfully handle the challenges of in-the-wild full-body synthesis. We show that TriA-GAN significantly improves over previous in-the-wild full-body synthesis methods, all while requiring less conditional information for synthesis (keypoints vs. DensePose). Finally, we show that the latent space of \methodName is compatible with standard unconditional editing techniques, enabling text-guided editing of generated human figures.
FullFormer: Generating Shapes Inside Shapes
Mar 20, 2023Implicit generative models have been widely employed to model 3D data and have recently proven to be successful in encoding and generating high-quality 3D shapes. This work builds upon these models and alleviates current limitations by presenting the first implicit generative model that facilitates the generation of complex 3D shapes with rich internal geometric details. To achieve this, our model uses unsigned distance fields to represent nested 3D surfaces allowing learning from non-watertight mesh data. We propose a transformer-based autoregressive model for 3D shape generation that leverages context-rich tokens from vector quantized shape embeddings. The generated tokens are decoded into an unsigned distance field which is rendered into a novel 3D shape exhibiting a rich internal structure. We demonstrate that our model achieves state-of-the-art point cloud generation results on popular classes of 'Cars', 'Planes', and 'Chairs' of the ShapeNet dataset. Additionally, we curate a dataset that exclusively comprises shapes with realistic internal details from the `Cars' class of ShapeNet and demonstrate our method's efficacy in generating these shapes with internal geometry.
Train smarter, not harder: learning deep abdominal CT registration on scarce data
Nov 30, 2022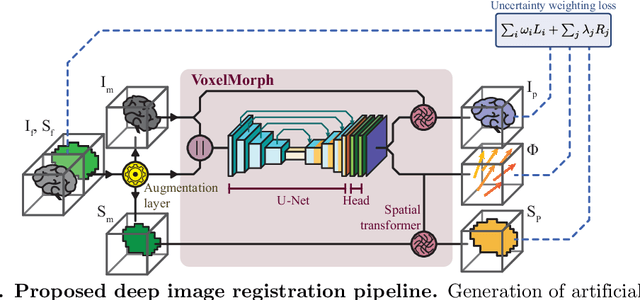
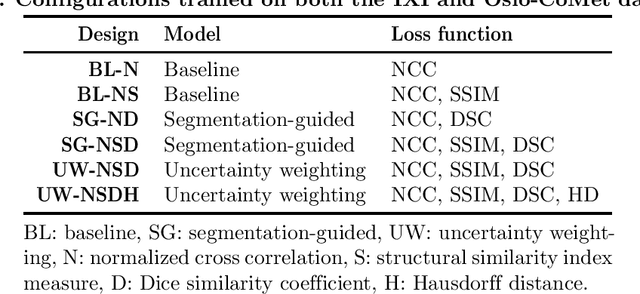
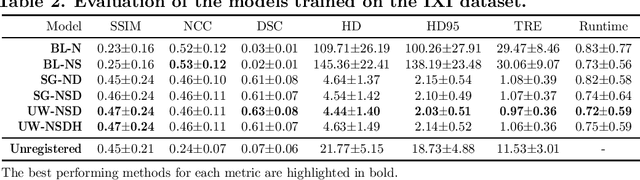
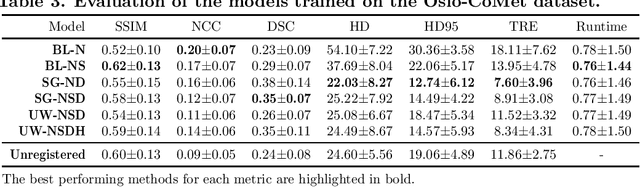
Purpose: This study aims to explore training strategies to improve convolutional neural network-based image-to-image registration for abdominal imaging. Methods: Different training strategies, loss functions, and transfer learning schemes were considered. Furthermore, an augmentation layer which generates artificial training image pairs on-the-fly was proposed, in addition to a loss layer that enables dynamic loss weighting. Results: Guiding registration using segmentations in the training step proved beneficial for deep-learning-based image registration. Finetuning the pretrained model from the brain MRI dataset to the abdominal CT dataset further improved performance on the latter application, removing the need for a large dataset to yield satisfactory performance. Dynamic loss weighting also marginally improved performance, all without impacting inference runtime. Conclusion: Using simple concepts, we improved the performance of a commonly used deep image registration architecture, VoxelMorph. In future work, our framework, DDMR, should be validated on different datasets to further assess its value.
DeepPrivacy2: Towards Realistic Full-Body Anonymization
Nov 17, 2022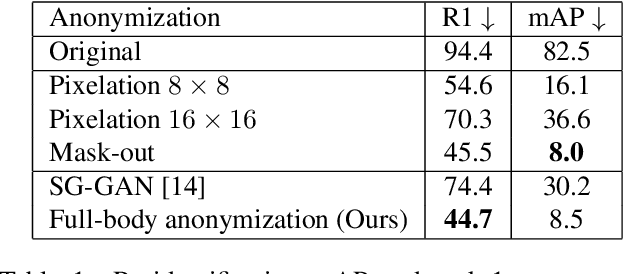

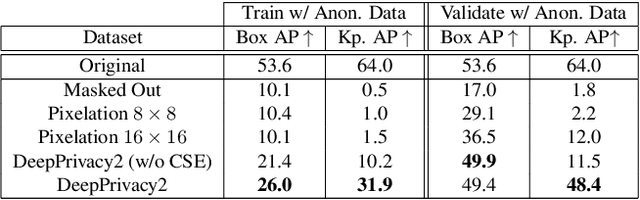

Generative Adversarial Networks (GANs) are widely adapted for anonymization of human figures. However, current state-of-the-art limit anonymization to the task of face anonymization. In this paper, we propose a novel anonymization framework (DeepPrivacy2) for realistic anonymization of human figures and faces. We introduce a new large and diverse dataset for human figure synthesis, which significantly improves image quality and diversity of generated images. Furthermore, we propose a style-based GAN that produces high quality, diverse and editable anonymizations. We demonstrate that our full-body anonymization framework provides stronger privacy guarantees than previously proposed methods.
Realistic Full-Body Anonymization with Surface-Guided GANs
Jan 06, 2022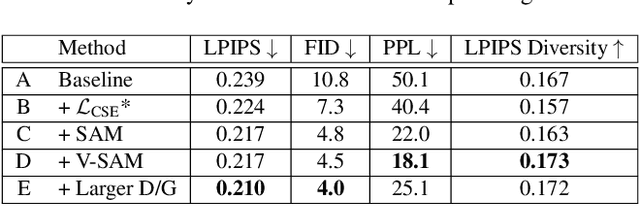

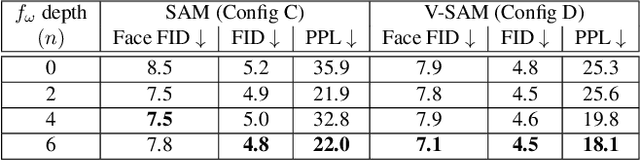
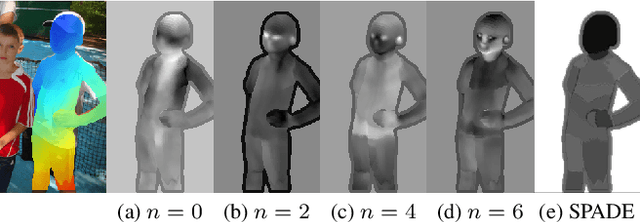
Recent work on image anonymization has shown that generative adversarial networks (GANs) can generate near-photorealistic faces to anonymize individuals. However, scaling these networks to the entire human body has remained a challenging and yet unsolved task. We propose a new anonymization method that generates close-to-photorealistic humans for in-the-wild images.A key part of our design is to guide adversarial nets by dense pixel-to-surface correspondences between an image and a canonical 3D surface.We introduce Variational Surface-Adaptive Modulation (V-SAM) that embeds surface information throughout the generator.Combining this with our novel discriminator surface supervision loss, the generator can synthesize high quality humans with diverse appearance in complex and varying scenes.We show that surface guidance significantly improves image quality and diversity of samples, yielding a highly practical generator.Finally, we demonstrate that surface-guided anonymization preserves the usability of data for future computer vision development
Teacher-Student Architecture for Mixed Supervised Lung Tumor Segmentation
Dec 21, 2021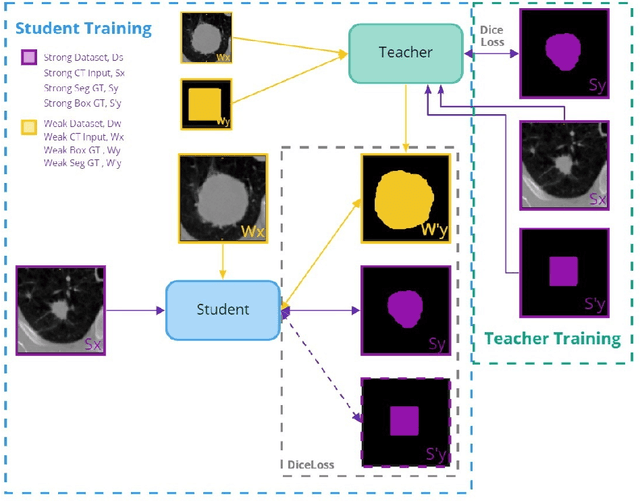
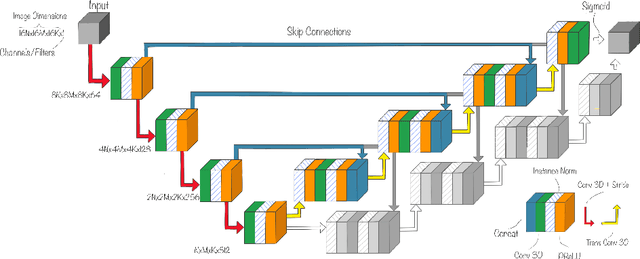
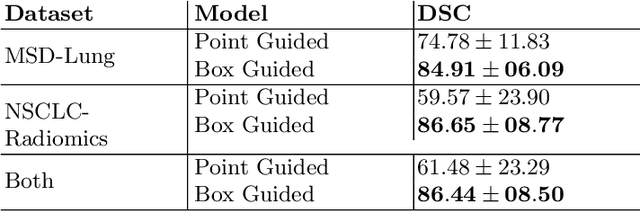
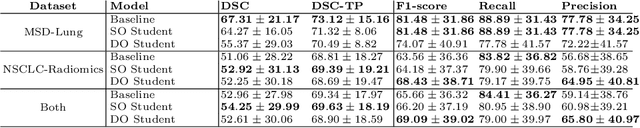
Purpose: Automating tasks such as lung tumor localization and segmentation in radiological images can free valuable time for radiologists and other clinical personnel. Convolutional neural networks may be suited for such tasks, but require substantial amounts of labeled data to train. Obtaining labeled data is a challenge, especially in the medical domain. Methods: This paper investigates the use of a teacher-student design to utilize datasets with different types of supervision to train an automatic model performing pulmonary tumor segmentation on computed tomography images. The framework consists of two models: the student that performs end-to-end automatic tumor segmentation and the teacher that supplies the student additional pseudo-annotated data during training. Results: Using only a small proportion of semantically labeled data and a large number of bounding box annotated data, we achieved competitive performance using a teacher-student design. Models trained on larger amounts of semantic annotations did not perform better than those trained on teacher-annotated data. Conclusions: Our results demonstrate the potential of utilizing teacher-student designs to reduce the annotation load, as less supervised annotation schemes may be performed, without any real degradation in segmentation accuracy.