 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential pose optimization in descriptor space -- Combining Geometric and Photometric Methods for Motion Estimation
Feb 15, 2026One of the fundamental problems in computer vision is the two-frame relative pose optimization problem. Primarily, two different kinds of error values are used: photometric error and re-projection error. The selection of error value is usually directly dependent on the selection of feature paradigm, photometric features, or geometric features. It is a trade-off between accuracy, robustness, and the possibility of loop closing. We investigate a third method that combines the strengths of both paradigms into a unified approach. Using densely sampled geometric feature descriptors, we replace the photometric error with a descriptor residual from a dense set of descriptors, thereby enabling the employment of sub-pixel accuracy in differential photometric methods, along with the expressiveness of the geometric feature descriptor. Experiments show that although the proposed strategy is an interesting approach that results in accurate tracking, it ultimately does not outperform pose optimization strategies based on re-projection error despite utilizing more information. We proceed to analyze the underlying reason for this discrepancy and present the hypothesis that the descriptor similarity metric is too slowly varying and does not necessarily correspond strictly to keypoint placement accuracy.
Near-Shore Mapping for Detection and Tracking of Vessels
Feb 25, 2025For an autonomous surface vessel (ASV) to dock, it must track other vessels close to the docking area. Kayaks present a particular challenge due to their proximity to the dock and relatively small size. Maritime target tracking has typically employed land masking to filter out land and the dock. However, imprecise land masking makes it difficult to track close-to-dock objects. Our approach uses Light Detection And Ranging (LiDAR) data and maps the docking area offline. The precise 3D measurements allow for precise map creation. However, the mapping could result in static, yet potentially moving, objects being mapped. We detect and filter out potentially moving objects from the LiDAR data by utilizing image data. The visual vessel detection and segmentation method is a neural network that is trained on our labeled data. Close-to-shore tracking improves with an accurate map and is demonstrated on a recently gathered real-world dataset. The dataset contains multiple sequences of a kayak and a day cruiser moving close to the dock, in a collision path with an autonomous ferry prototype.
Removing Adverse Volumetric Effects From Trained Neural Radiance Fields
Nov 17, 2023


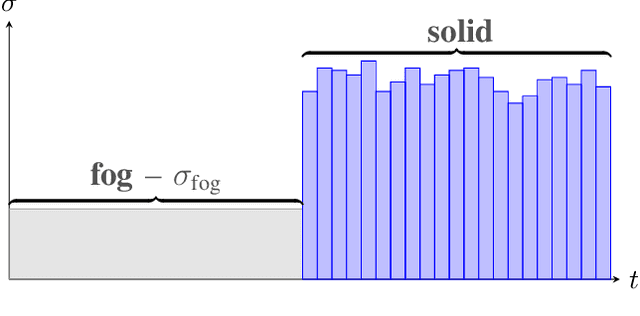
While the use of neural radiance fields (NeRFs) in different challenging settings has been explored, only very recently have there been any contributions that focus on the use of NeRF in foggy environments. We argue that the traditional NeRF models are able to replicate scenes filled with fog and propose a method to remove the fog when synthesizing novel views. By calculating the global contrast of a scene, we can estimate a density threshold that, when applied, removes all visible fog. This makes it possible to use NeRF as a way of rendering clear views of objects of interest located in fog-filled environments. Additionally, to benchmark performance on such scenes, we introduce a new dataset that expands some of the original synthetic NeRF scenes through the addition of fog and natural environments. The code, dataset, and video results can be found on our project page: https://vegardskui.com/fognerf/
RGB-D Mapping and Tracking in a Plenoxel Radiance Field
Jul 07, 2023Building on the success of Neural Radiance Fields (NeRFs), recent years have seen significant advances in the domain of novel view synthesis. These models capture the scene's volumetric radiance field, creating highly convincing dense photorealistic models through the use of simple, differentiable rendering equations. Despite their popularity, these algorithms suffer from severe ambiguities in visual data inherent to the RGB sensor, which means that although images generated with view synthesis can visually appear very believable, the underlying 3D model will often be wrong. This considerably limits the usefulness of these models in practical applications like Robotics and Extended Reality (XR), where an accurate dense 3D reconstruction otherwise would be of significant value. In this technical report, we present the vital differences between view synthesis models and 3D reconstruction models. We also comment on why a depth sensor is essential for modeling accurate geometry in general outward-facing scenes using the current paradigm of novel view synthesis methods. Focusing on the structure-from-motion task, we practically demonstrate this need by extending the Plenoxel radiance field model: Presenting an analytical differential approach for dense mapping and tracking with radiance fields based on RGB-D data without a neural network. Our method achieves state-of-the-art results in both the mapping and tracking tasks while also being faster than competing neural network-based approaches.
Geolocation estimation of target vehicles using image processing and geometric computation
Mar 08, 2022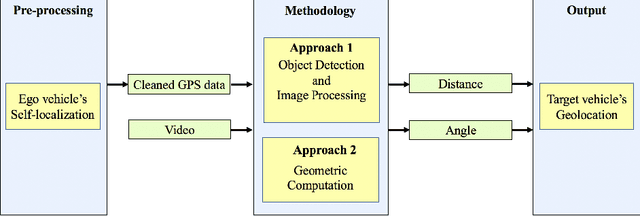
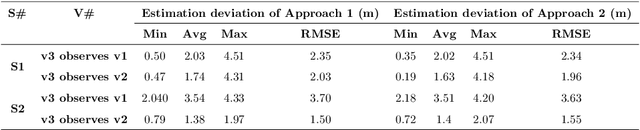
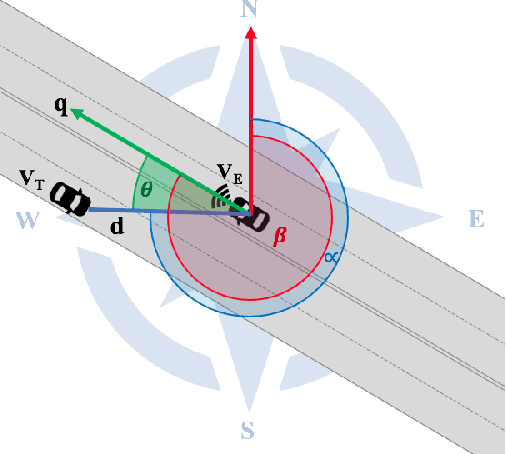
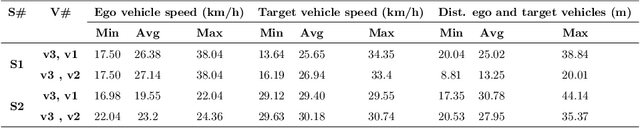
Estimating vehicles' locations is one of the key components in intelligent traffic management systems (ITMSs) for increasing traffic scene awareness. Traditionally, stationary sensors have been employed in this regard. The development of advanced sensing and communication technologies on modern vehicles (MVs) makes it feasible to use such vehicles as mobile sensors to estimate the traffic data of observed vehicles. This study aims to explore the capabilities of a monocular camera mounted on an MV in order to estimate the geolocation of the observed vehicle in a global positioning system (GPS) coordinate system. We proposed a new methodology by integrating deep learning, image processing, and geometric computation to address the observed-vehicle localization problem. To evaluate our proposed methodology, we developed new algorithms and tested them using real-world traffic data. The results indicated that our proposed methodology and algorithms could effectively estimate the observed vehicle's latitude and longitude dynamically.
Realistic Full-Body Anonymization with Surface-Guided GANs
Jan 06, 2022

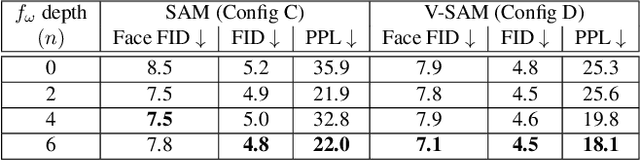
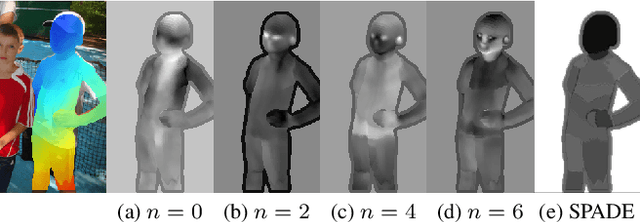
Recent work on image anonymization has shown that generative adversarial networks (GANs) can generate near-photorealistic faces to anonymize individuals. However, scaling these networks to the entire human body has remained a challenging and yet unsolved task. We propose a new anonymization method that generates close-to-photorealistic humans for in-the-wild images.A key part of our design is to guide adversarial nets by dense pixel-to-surface correspondences between an image and a canonical 3D surface.We introduce Variational Surface-Adaptive Modulation (V-SAM) that embeds surface information throughout the generator.Combining this with our novel discriminator surface supervision loss, the generator can synthesize high quality humans with diverse appearance in complex and varying scenes.We show that surface guidance significantly improves image quality and diversity of samples, yielding a highly practical generator.Finally, we demonstrate that surface-guided anonymization preserves the usability of data for future computer vision development
Model-Based Parameter Optimization for Ground Texture Based Localization Methods
Sep 03, 2021

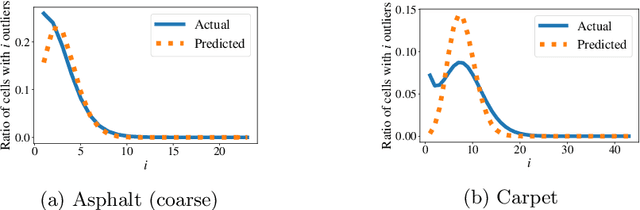
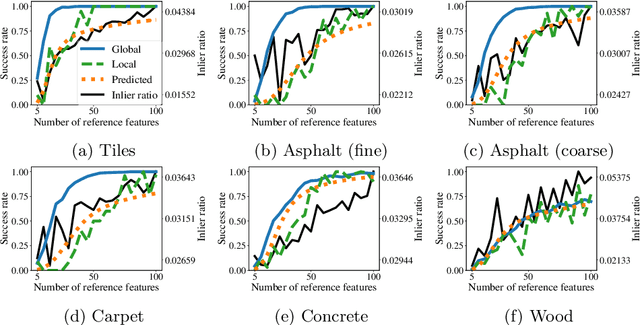
A promising approach to accurate positioning of robots is ground texture based localization. It is based on the observation that visual features of ground images enable fingerprint-like place recognition. We tackle the issue of efficient parametrization of such methods, deriving a prediction model for localization performance, which requires only a small collection of sample images of an application area. In a first step, we examine whether the model can predict the effects of changing one of the most important parameters of feature-based localization methods: the number of extracted features. We examine two localization methods, and in both cases our evaluation shows that the predictions are sufficiently accurate. Since this model can be used to find suitable values for any parameter, we then present a holistic parameter optimization framework, which finds suitable texture-specific parameter configurations, using only the model to evaluate the considered parameter configurations.
Urban Traffic Surveillance (UTS): A fully probabilistic 3D tracking approach based on 2D detections
Jun 01, 2021
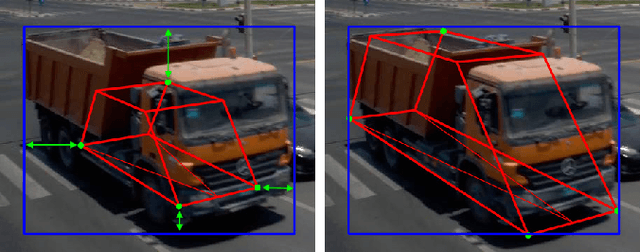


Urban Traffic Surveillance (UTS) is a surveillance system based on a monocular and calibrated video camera that detects vehicles in an urban traffic scenario with dense traffic on multiple lanes and vehicles performing sharp turning maneuvers. UTS then tracks the vehicles using a 3D bounding box representation and a physically reasonable 3D motion model relying on an unscented Kalman filter based approach. Since UTS recovers positions, shape and motion information in a three-dimensional world coordinate system, it can be employed to recognize diverse traffic violations or to supply intelligent vehicles with valuable traffic information. We build on YOLOv3 as a detector yielding 2D bounding boxes and class labels for each vehicle. A 2D detector renders our system much more independent to different camera perspectives as a variety of labeled training data is available. This allows for a good generalization while also being more hardware efficient. The task of 3D tracking based on 2D detections is supported by integrating class specific prior knowledge about the vehicle shape. We quantitatively evaluate UTS using self generated synthetic data and ground truth from the CARLA simulator, due to the non-existence of datasets with an urban vehicle surveillance setting and labeled 3D bounding boxes. Additionally, we give a qualitative impression of how UTS performs on real-world data. Our implementation is capable of operating in real time on a reasonably modern workstation. To the best of our knowledge, UTS is to date the only 3D vehicle tracking system in a surveillance scenario (static camera observing moving targets).
Image Inpainting with Learnable Feature Imputation
Nov 02, 2020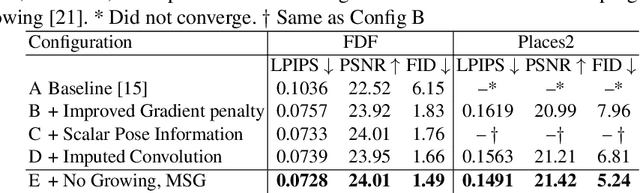
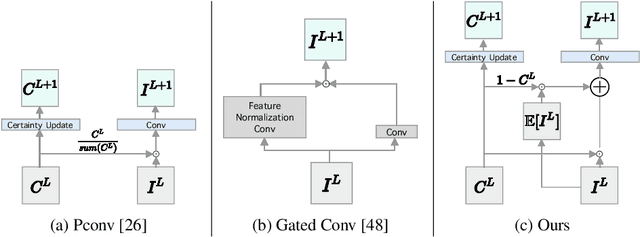

A regular convolution layer applying a filter in the same way over known and unknown areas causes visual artifacts in the inpainted image. Several studies address this issue with feature re-normalization on the output of the convolution. However, these models use a significant amount of learnable parameters for feature re-normalization, or assume a binary representation of the certainty of an output. We propose (layer-wise) feature imputation of the missing input values to a convolution. In contrast to learned feature re-normalization, our method is efficient and introduces a minimal number of parameters. Furthermore, we propose a revised gradient penalty for image inpainting, and a novel GAN architecture trained exclusively on adversarial loss. Our quantitative evaluation on the FDF dataset reflects that our revised gradient penalty and alternative convolution improves generated image quality significantly. We present comparisons on CelebA-HQ and Places2 to current state-of-the-art to validate our model.
Features for Ground Texture Based Localization -- A Survey
Mar 03, 2020

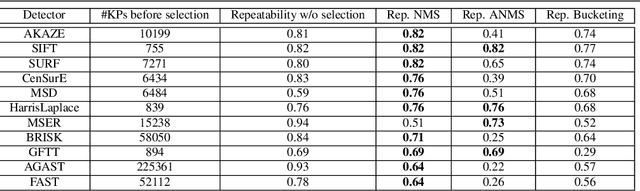
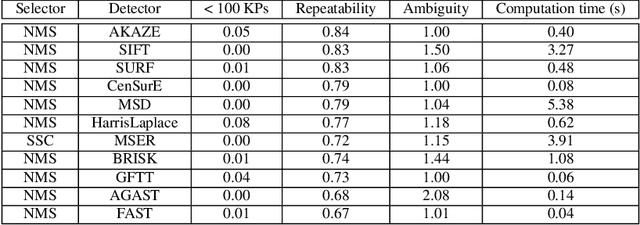
Ground texture based vehicle localization using feature-based methods is a promising approach to achieve infrastructure-free high-accuracy localization. In this paper, we provide the first extensive evaluation of available feature extraction methods for this task, using separately taken image pairs as well as synthetic transformations. We identify AKAZE, SURF and CenSurE as best performing keypoint detectors, and find pairings of CenSurE with the ORB, BRIEF and LATCH feature descriptors to achieve greatest success rates for incremental localization, while SIFT stands out when considering severe synthetic transformations as they might occur during absolute localization.