 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducible, Explainable, and Effective Evaluations of Agentic AI for Software Engineering
Apr 01, 2026With the advancement of Agentic AI, researchers are increasingly leveraging autonomous agents to address challenges in software engineering (SE). However, the large language models (LLMs) that underpin these agents often function as black boxes, making it difficult to justify the superiority of Agentic AI approaches over baselines. Furthermore, missing information in the evaluation design description frequently renders the reproduction of results infeasible. To synthesize current evaluation practices for Agentic AI in SE, this study analyzes 18 papers on the topic, published or accepted by ICSE 2026, ICSE 2025, FSE 2025, ASE 2025, and ISSTA 2025. The analysis identifies prevailing approaches and their limitations in evaluating Agentic AI for SE, both in current research and potential future studies. To address these shortcomings, this position paper proposes a set of guidelines and recommendations designed to empower reproducible, explainable, and effective evaluations of Agentic AI in software engineering. In particular, we recommend that Agentic AI researchers make their Thought-Action-Result (TAR) trajectories and LLM interaction data, or summarized versions of these artifacts, publicly accessible. Doing so will enable subsequent studies to more effectively analyze the strengths and weaknesses of different Agentic AI approaches. To demonstrate the feasibility of such comparisons, we present a proof-of-concept case study that illustrates how TAR trajectories can support systematic analysis across approaches.
Favia: Forensic Agent for Vulnerability-fix Identification and Analysis
Feb 13, 2026Identifying vulnerability-fixing commits corresponding to disclosed CVEs is essential for secure software maintenance but remains challenging at scale, as large repositories contain millions of commits of which only a small fraction address security issues. Existing automated approaches, including traditional machine learning techniques and recent large language model (LLM)-based methods, often suffer from poor precision-recall trade-offs. Frequently evaluated on randomly sampled commits, we uncover that they are substantially underestimating real-world difficulty, where candidate commits are already security-relevant and highly similar. We propose Favia, a forensic, agent-based framework for vulnerability-fix identification that combines scalable candidate ranking with deep and iterative semantic reasoning. Favia first employs an efficient ranking stage to narrow the search space of commits. Each commit is then rigorously evaluated using a ReAct-based LLM agent. By providing the agent with a pre-commit repository as environment, along with specialized tools, the agent tries to localize vulnerable components, navigates the codebase, and establishes causal alignment between code changes and vulnerability root causes. This evidence-driven process enables robust identification of indirect, multi-file, and non-trivial fixes that elude single-pass or similarity-based methods. We evaluate Favia on CVEVC, a large-scale dataset we made that comprises over 8 million commits from 3,708 real-world repositories, and show that it consistently outperforms state-of-the-art traditional and LLM-based baselines under realistic candidate selection, achieving the strongest precision-recall trade-offs and highest F1-scores.
Associative Poisoning to Generative Machine Learning
Nov 07, 2025



The widespread adoption of generative models such as Stable Diffusion and ChatGPT has made them increasingly attractive targets for malicious exploitation, particularly through data poisoning. Existing poisoning attacks compromising synthesised data typically either cause broad degradation of generated data or require control over the training process, limiting their applicability in real-world scenarios. In this paper, we introduce a novel data poisoning technique called associative poisoning, which compromises fine-grained features of the generated data without requiring control of the training process. This attack perturbs only the training data to manipulate statistical associations between specific feature pairs in the generated outputs. We provide a formal mathematical formulation of the attack and prove its theoretical feasibility and stealthiness. Empirical evaluations using two state-of-the-art generative models demonstrate that associative poisoning effectively induces or suppresses feature associations while preserving the marginal distributions of the targeted features and maintaining high-quality outputs, thereby evading visual detection. These results suggest that generative systems used in image synthesis, synthetic dataset generation, and natural language processing are susceptible to subtle, stealthy manipulations that compromise their statistical integrity. To address this risk, we examine the limitations of existing defensive strategies and propose a novel countermeasure strategy.
Efficient Avoidance of Vulnerabilities in Auto-completed Smart Contract Code Using Vulnerability-constrained Decoding
Sep 18, 2023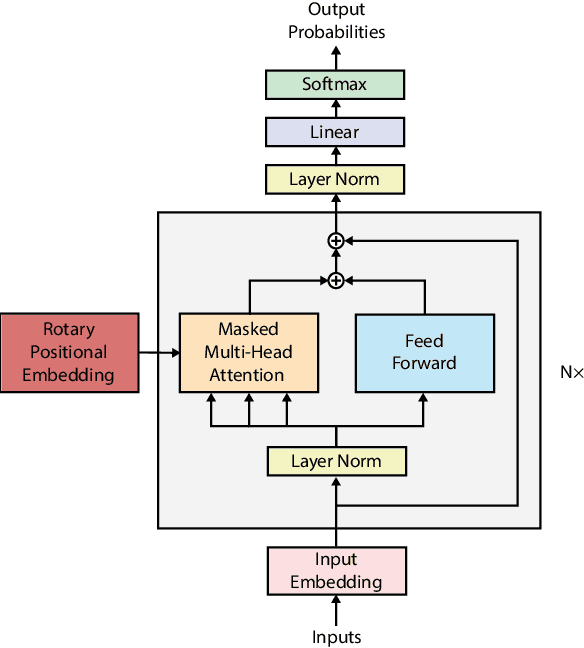
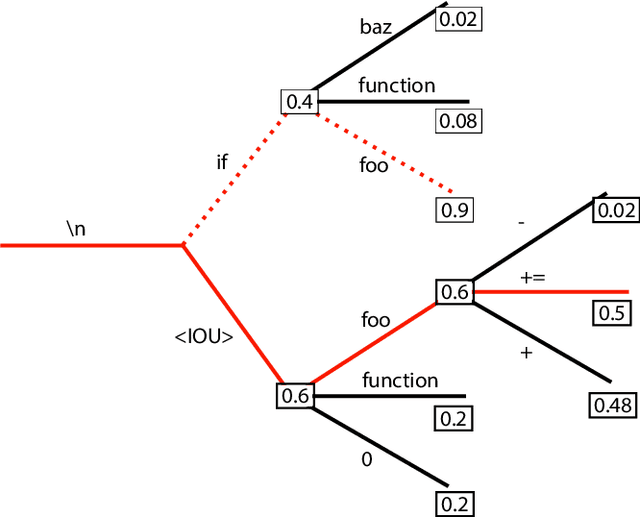
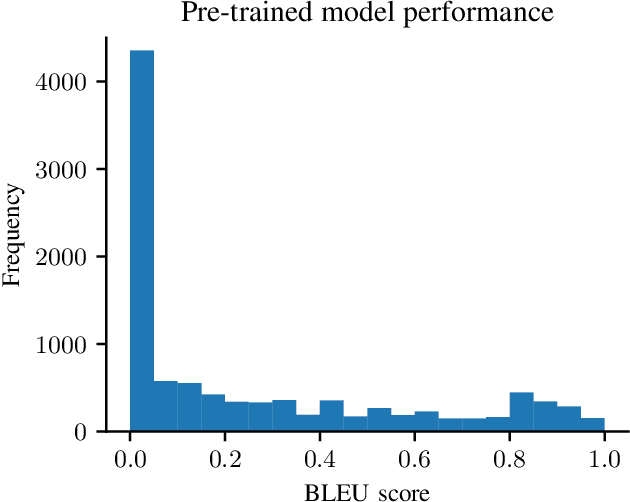
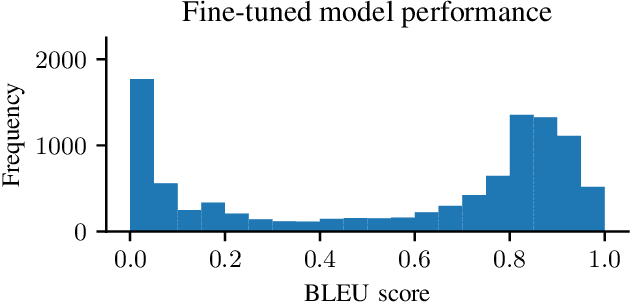
Auto-completing code enables developers to speed up coding significantly. Recent advances in transformer-based large language model (LLM) technologies have been applied to code synthesis. However, studies show that many of such synthesized codes contain vulnerabilities. We propose a novel vulnerability-constrained decoding approach to reduce the amount of vulnerable code generated by such models. Using a small dataset of labeled vulnerable lines of code, we fine-tune an LLM to include vulnerability labels when generating code, acting as an embedded classifier. Then, during decoding, we deny the model to generate these labels to avoid generating vulnerable code. To evaluate the method, we chose to automatically complete Ethereum Blockchain smart contracts (SCs) as the case study due to the strict requirements of SC security. We first fine-tuned the 6-billion-parameter GPT-J model using 186,397 Ethereum SCs after removing the duplication from 2,217,692 SCs. The fine-tuning took more than one week using ten GPUs. The results showed that our fine-tuned model could synthesize SCs with an average BLEU (BiLingual Evaluation Understudy) score of 0.557. However, many codes in the auto-completed SCs were vulnerable. Using the code before the vulnerable line of 176 SCs containing different types of vulnerabilities to auto-complete the code, we found that more than 70% of the auto-completed codes were insecure. Thus, we further fine-tuned the model on other 941 vulnerable SCs containing the same types of vulnerabilities and applied vulnerability-constrained decoding. The fine-tuning took only one hour with four GPUs. We then auto-completed the 176 SCs again and found that our approach could identify 62% of the code to be generated as vulnerable and avoid generating 67% of them, indicating the approach could efficiently and effectively avoid vulnerabilities in the auto-completed code.
A Systematic Literature Review on Client Selection in Federated Learning
Jun 08, 2023With the arising concerns of privacy within machine learning, federated learning (FL) was invented in 2017, in which the clients, such as mobile devices, train a model and send the update to the centralized server. Choosing clients randomly for FL can harm learning performance due to different reasons. Many studies have proposed approaches to address the challenges of client selection of FL. However, no systematic literature review (SLR) on this topic existed. This SLR investigates the state of the art of client selection in FL and answers the challenges, solutions, and metrics to evaluate the solutions. We systematically reviewed 47 primary studies. The main challenges found in client selection are heterogeneity, resource allocation, communication costs, and fairness. The client selection schemes aim to improve the original random selection algorithm by focusing on one or several of the aforementioned challenges. The most common metric used is testing accuracy versus communication rounds, as testing accuracy measures the successfulness of the learning and preferably in as few communication rounds as possible, as they are very expensive. Although several possible improvements can be made with the current state of client selection, the most beneficial ones are evaluating the impact of unsuccessful clients and gaining a more theoretical understanding of the impact of fairness in FL.
Geolocation estimation of target vehicles using image processing and geometric computation
Mar 08, 2022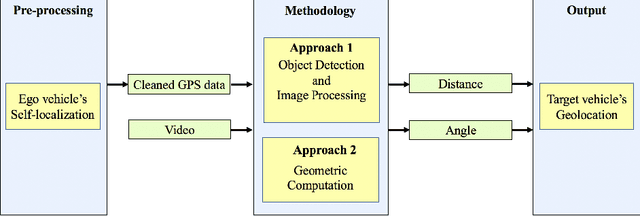
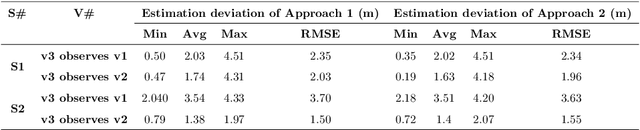
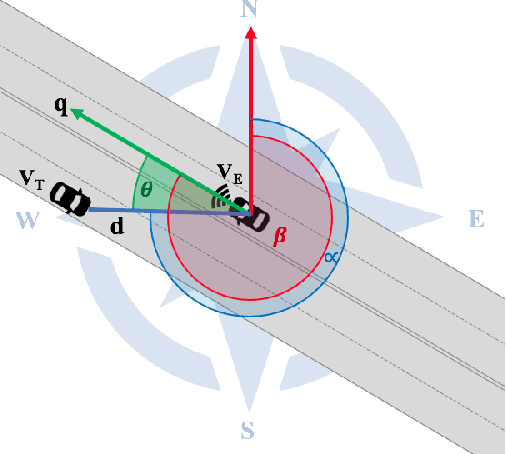
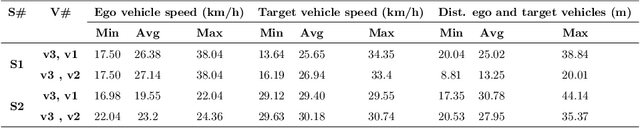
Estimating vehicles' locations is one of the key components in intelligent traffic management systems (ITMSs) for increasing traffic scene awareness. Traditionally, stationary sensors have been employed in this regard. The development of advanced sensing and communication technologies on modern vehicles (MVs) makes it feasible to use such vehicles as mobile sensors to estimate the traffic data of observed vehicles. This study aims to explore the capabilities of a monocular camera mounted on an MV in order to estimate the geolocation of the observed vehicle in a global positioning system (GPS) coordinate system. We proposed a new methodology by integrating deep learning, image processing, and geometric computation to address the observed-vehicle localization problem. To evaluate our proposed methodology, we developed new algorithms and tested them using real-world traffic data. The results indicated that our proposed methodology and algorithms could effectively estimate the observed vehicle's latitude and longitude dynamically.
Testing and verification of neural-network-based safety-critical control software: A systematic literature review
Oct 05, 2019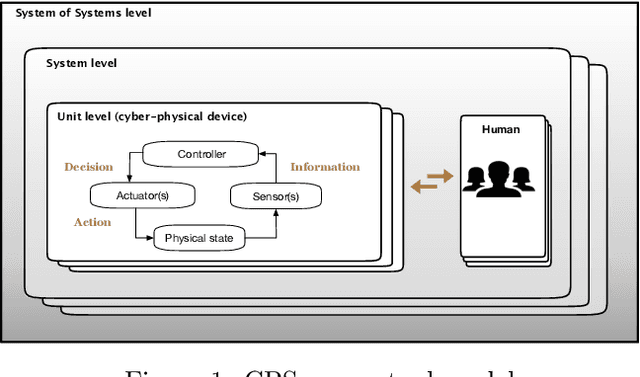

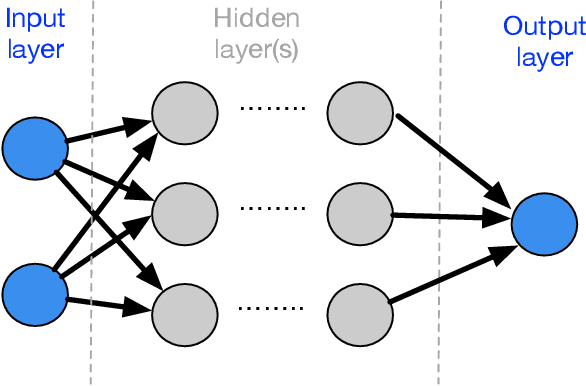
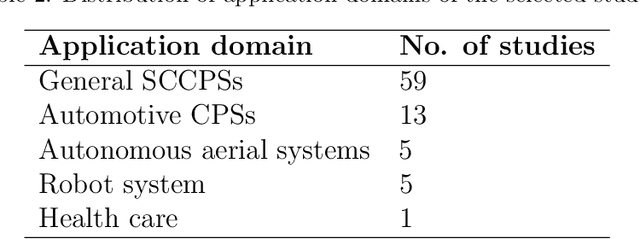
Context: Neural Network (NN) algorithms have been successfully adopted in a number of Safety-Critical Cyber-Physical Systems (SCCPSs). Testing and Verification (T&V) of NN-based control software in safety-critical domains are gaining interest and attention from both software engineering and safety engineering researchers and practitioners. Objective: With the increase in studies on the T&V of NN-based control software in safety-critical domains, it is important to systematically review the state-of-the-art T&V methodologies, to classify approaches and tools that are invented, and to identify challenges and gaps for future studies. Method: We retrieved 950 papers on the T&V of NN-based Safety-Critical Control Software (SCCS). To reach our result, we filtered 83 primary papers published between 2001 and 2018, applied the thematic analysis approach for analyzing the data extracted from the selected papers, presented the classification of approaches, and identified challenges. Conclusion: The approaches were categorized into five high-order themes: assuring robustness of NNs, assuring safety properties of NN-based control software, improving the failure resilience of NNs, measuring and ensuring test completeness, and improving the interpretability of NNs. From the industry perspective, improving the interpretability of NNs is a crucial need in safety-critical applications. We also investigated nine safety integrity properties within four major safety lifecycle phases to investigate the achievement level of T&V goals in IEC 61508-3. Results show that correctness, completeness, freedom from intrinsic faults, and fault tolerance have drawn most attention from the research community. However, little effort has been invested in achieving repeatability; no reviewed study focused on precisely defined testing configuration or on defense against common cause failure.