 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Avoidance of Vulnerabilities in Auto-completed Smart Contract Code Using Vulnerability-constrained Decoding
Paper and Code
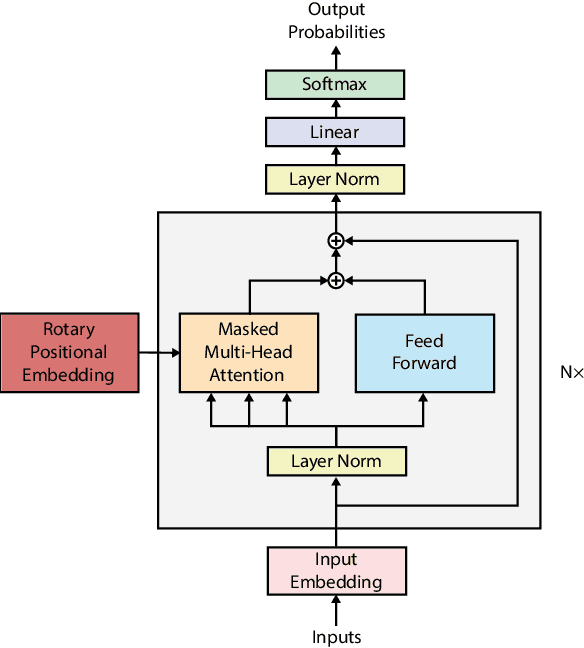
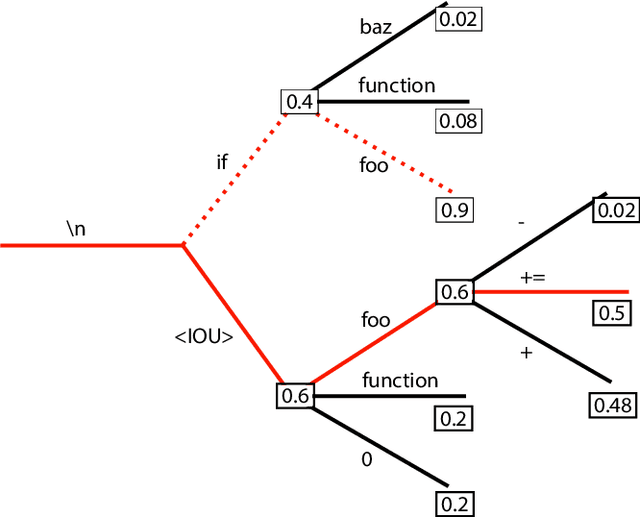
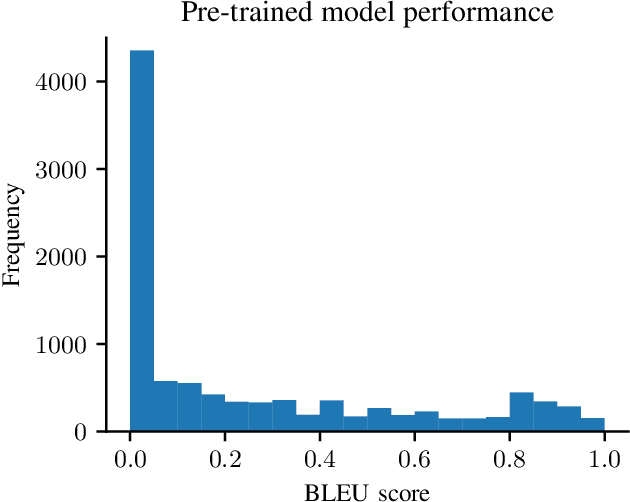
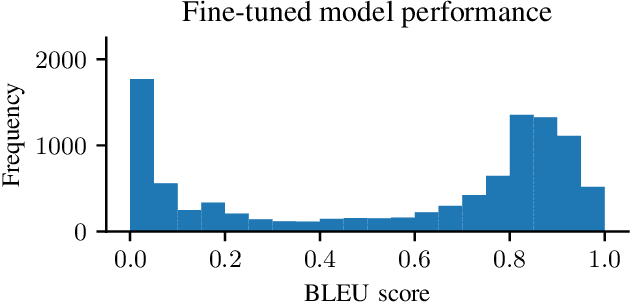
Auto-completing code enables developers to speed up coding significantly. Recent advances in transformer-based large language model (LLM) technologies have been applied to code synthesis. However, studies show that many of such synthesized codes contain vulnerabilities. We propose a novel vulnerability-constrained decoding approach to reduce the amount of vulnerable code generated by such models. Using a small dataset of labeled vulnerable lines of code, we fine-tune an LLM to include vulnerability labels when generating code, acting as an embedded classifier. Then, during decoding, we deny the model to generate these labels to avoid generating vulnerable code. To evaluate the method, we chose to automatically complete Ethereum Blockchain smart contracts (SCs) as the case study due to the strict requirements of SC security. We first fine-tuned the 6-billion-parameter GPT-J model using 186,397 Ethereum SCs after removing the duplication from 2,217,692 SCs. The fine-tuning took more than one week using ten GPUs. The results showed that our fine-tuned model could synthesize SCs with an average BLEU (BiLingual Evaluation Understudy) score of 0.557. However, many codes in the auto-completed SCs were vulnerable. Using the code before the vulnerable line of 176 SCs containing different types of vulnerabilities to auto-complete the code, we found that more than 70% of the auto-completed codes were insecure. Thus, we further fine-tuned the model on other 941 vulnerable SCs containing the same types of vulnerabilities and applied vulnerability-constrained decoding. The fine-tuning took only one hour with four GPUs. We then auto-completed the 176 SCs again and found that our approach could identify 62% of the code to be generated as vulnerable and avoid generating 67% of them, indicating the approach could efficiently and effectively avoid vulnerabilities in the auto-completed code.