 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential pose optimization in descriptor space -- Combining Geometric and Photometric Methods for Motion Estimation
Feb 15, 2026One of the fundamental problems in computer vision is the two-frame relative pose optimization problem. Primarily, two different kinds of error values are used: photometric error and re-projection error. The selection of error value is usually directly dependent on the selection of feature paradigm, photometric features, or geometric features. It is a trade-off between accuracy, robustness, and the possibility of loop closing. We investigate a third method that combines the strengths of both paradigms into a unified approach. Using densely sampled geometric feature descriptors, we replace the photometric error with a descriptor residual from a dense set of descriptors, thereby enabling the employment of sub-pixel accuracy in differential photometric methods, along with the expressiveness of the geometric feature descriptor. Experiments show that although the proposed strategy is an interesting approach that results in accurate tracking, it ultimately does not outperform pose optimization strategies based on re-projection error despite utilizing more information. We proceed to analyze the underlying reason for this discrepancy and present the hypothesis that the descriptor similarity metric is too slowly varying and does not necessarily correspond strictly to keypoint placement accuracy.
PyGemini: Unified Software Development towards Maritime Autonomy Systems
Jun 06, 2025Ensuring the safety and certifiability of autonomous surface vessels (ASVs) requires robust decision-making systems, supported by extensive simulation, testing, and validation across a broad range of scenarios. However, the current landscape of maritime autonomy development is fragmented -- relying on disparate tools for communication, simulation, monitoring, and system integration -- which hampers interdisciplinary collaboration and inhibits the creation of compelling assurance cases, demanded by insurers and regulatory bodies. Furthermore, these disjointed tools often suffer from performance bottlenecks, vendor lock-in, and limited support for continuous integration workflows. To address these challenges, we introduce PyGemini, a permissively licensed, Python-native framework that builds on the legacy of Autoferry Gemini to unify maritime autonomy development. PyGemini introduces a novel Configuration-Driven Development (CDD) process that fuses Behavior-Driven Development (BDD), data-oriented design, and containerization to support modular, maintainable, and scalable software architectures. The framework functions as a stand-alone application, cloud-based service, or embedded library -- ensuring flexibility across research and operational contexts. We demonstrate its versatility through a suite of maritime tools -- including 3D content generation for simulation and monitoring, scenario generation for autonomy validation and training, and generative artificial intelligence pipelines for augmenting imagery -- thereby offering a scalable, maintainable, and performance-oriented foundation for future maritime robotics and autonomy research.
Near-Shore Mapping for Detection and Tracking of Vessels
Feb 25, 2025For an autonomous surface vessel (ASV) to dock, it must track other vessels close to the docking area. Kayaks present a particular challenge due to their proximity to the dock and relatively small size. Maritime target tracking has typically employed land masking to filter out land and the dock. However, imprecise land masking makes it difficult to track close-to-dock objects. Our approach uses Light Detection And Ranging (LiDAR) data and maps the docking area offline. The precise 3D measurements allow for precise map creation. However, the mapping could result in static, yet potentially moving, objects being mapped. We detect and filter out potentially moving objects from the LiDAR data by utilizing image data. The visual vessel detection and segmentation method is a neural network that is trained on our labeled data. Close-to-shore tracking improves with an accurate map and is demonstrated on a recently gathered real-world dataset. The dataset contains multiple sequences of a kayak and a day cruiser moving close to the dock, in a collision path with an autonomous ferry prototype.
Robust Hole-Detection in Triangular Meshes Irrespective of the Presence of Singular Vertices
Nov 21, 2023In this work, we present a boundary and hole detection approach that traverses all the boundaries of an edge-manifold triangular mesh, irrespectively of the presence of singular vertices, and subsequently determines and labels all holes of the mesh. The proposed automated hole-detection method is valuable to the computer-aided design (CAD) community as all half-edges within the mesh are utilized and for each half-edge the algorithm guarantees both the existence and the uniqueness of the boundary associated to it. As existing hole-detection approaches assume that singular vertices are absent or may require mesh modification, these methods are ill-equipped to detect boundaries/holes in real-world meshes that contain singular vertices. We demonstrate the method in an underwater autonomous robotic application, exploiting surface reconstruction methods based on point cloud data. In such a scenario the determined holes can be interpreted as information gaps, enabling timely corrective action during the data acquisition. However, the scope of our method is not confined to these two sectors alone; it is versatile enough to be applied on any edge-manifold triangle mesh. An evaluation of the method is performed on both synthetic and real-world data (including a triangle mesh from a point cloud obtained by a multibeam sonar). The source code of our reference implementation is available: https://github.com/Mauhing/hole-detection-on-triangle-mesh.
Removing Adverse Volumetric Effects From Trained Neural Radiance Fields
Nov 17, 2023


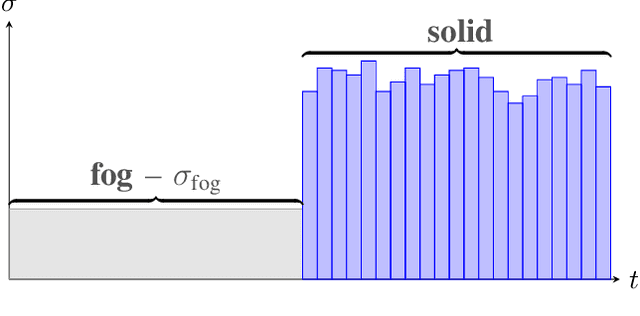
While the use of neural radiance fields (NeRFs) in different challenging settings has been explored, only very recently have there been any contributions that focus on the use of NeRF in foggy environments. We argue that the traditional NeRF models are able to replicate scenes filled with fog and propose a method to remove the fog when synthesizing novel views. By calculating the global contrast of a scene, we can estimate a density threshold that, when applied, removes all visible fog. This makes it possible to use NeRF as a way of rendering clear views of objects of interest located in fog-filled environments. Additionally, to benchmark performance on such scenes, we introduce a new dataset that expands some of the original synthetic NeRF scenes through the addition of fog and natural environments. The code, dataset, and video results can be found on our project page: https://vegardskui.com/fognerf/
RGB-D Mapping and Tracking in a Plenoxel Radiance Field
Jul 07, 2023Building on the success of Neural Radiance Fields (NeRFs), recent years have seen significant advances in the domain of novel view synthesis. These models capture the scene's volumetric radiance field, creating highly convincing dense photorealistic models through the use of simple, differentiable rendering equations. Despite their popularity, these algorithms suffer from severe ambiguities in visual data inherent to the RGB sensor, which means that although images generated with view synthesis can visually appear very believable, the underlying 3D model will often be wrong. This considerably limits the usefulness of these models in practical applications like Robotics and Extended Reality (XR), where an accurate dense 3D reconstruction otherwise would be of significant value. In this technical report, we present the vital differences between view synthesis models and 3D reconstruction models. We also comment on why a depth sensor is essential for modeling accurate geometry in general outward-facing scenes using the current paradigm of novel view synthesis methods. Focusing on the structure-from-motion task, we practically demonstrate this need by extending the Plenoxel radiance field model: Presenting an analytical differential approach for dense mapping and tracking with radiance fields based on RGB-D data without a neural network. Our method achieves state-of-the-art results in both the mapping and tracking tasks while also being faster than competing neural network-based approaches.