 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrban Traffic Surveillance (UTS): A fully probabilistic 3D tracking approach based on 2D detections
Jun 01, 2021
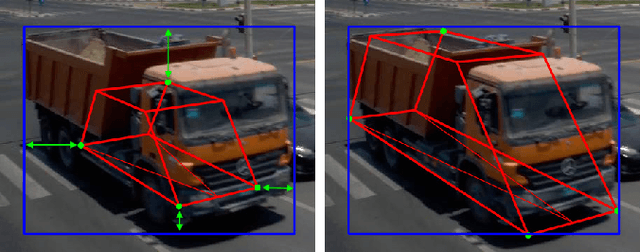


Urban Traffic Surveillance (UTS) is a surveillance system based on a monocular and calibrated video camera that detects vehicles in an urban traffic scenario with dense traffic on multiple lanes and vehicles performing sharp turning maneuvers. UTS then tracks the vehicles using a 3D bounding box representation and a physically reasonable 3D motion model relying on an unscented Kalman filter based approach. Since UTS recovers positions, shape and motion information in a three-dimensional world coordinate system, it can be employed to recognize diverse traffic violations or to supply intelligent vehicles with valuable traffic information. We build on YOLOv3 as a detector yielding 2D bounding boxes and class labels for each vehicle. A 2D detector renders our system much more independent to different camera perspectives as a variety of labeled training data is available. This allows for a good generalization while also being more hardware efficient. The task of 3D tracking based on 2D detections is supported by integrating class specific prior knowledge about the vehicle shape. We quantitatively evaluate UTS using self generated synthetic data and ground truth from the CARLA simulator, due to the non-existence of datasets with an urban vehicle surveillance setting and labeled 3D bounding boxes. Additionally, we give a qualitative impression of how UTS performs on real-world data. Our implementation is capable of operating in real time on a reasonably modern workstation. To the best of our knowledge, UTS is to date the only 3D vehicle tracking system in a surveillance scenario (static camera observing moving targets).
SDNet: Semantically Guided Depth Estimation Network
Jul 24, 2019
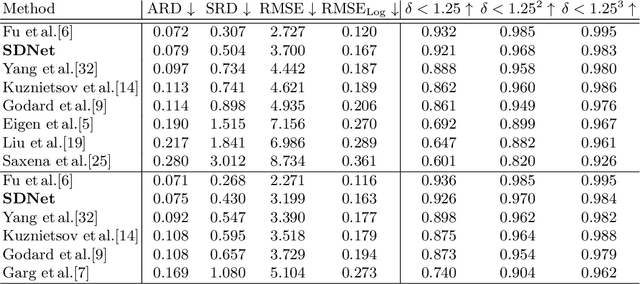
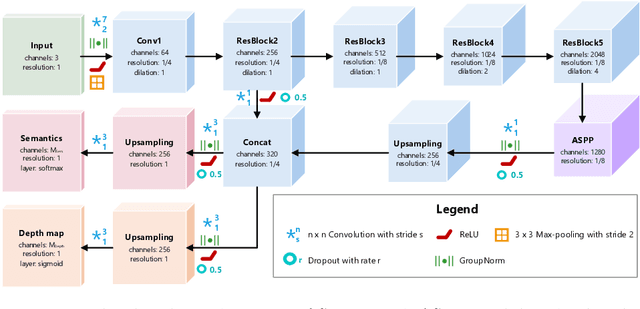
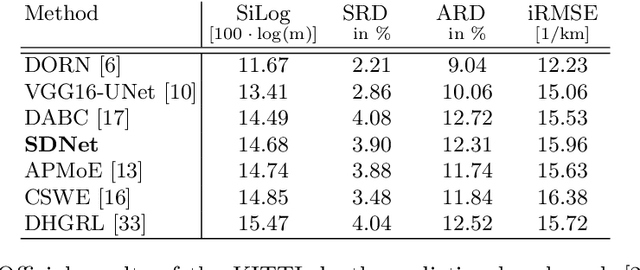
Autonomous vehicles and robots require a full scene understanding of the environment to interact with it. Such a perception typically incorporates pixel-wise knowledge of the depths and semantic labels for each image from a video sensor. Recent learning-based methods estimate both types of information independently using two separate CNNs. In this paper, we propose a model that is able to predict both outputs simultaneously, which leads to improved results and even reduced computational costs compared to independent estimation of depth and semantics. We also empirically prove that the CNN is capable of learning more meaningful and semantically richer features. Furthermore, our SDNet estimates the depth based on ordinal classification. On the basis of these two enhancements, our proposed method achieves state-of-the-art results in semantic segmentation and depth estimation from single monocular input images on two challenging datasets.