 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrban Traffic Surveillance (UTS): A fully probabilistic 3D tracking approach based on 2D detections
Jun 01, 2021
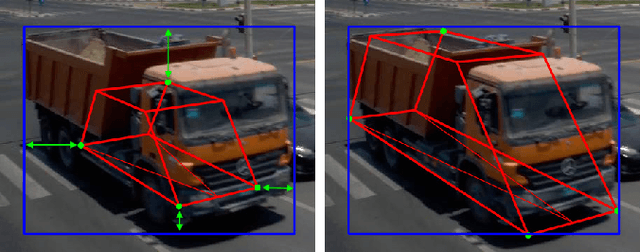


Urban Traffic Surveillance (UTS) is a surveillance system based on a monocular and calibrated video camera that detects vehicles in an urban traffic scenario with dense traffic on multiple lanes and vehicles performing sharp turning maneuvers. UTS then tracks the vehicles using a 3D bounding box representation and a physically reasonable 3D motion model relying on an unscented Kalman filter based approach. Since UTS recovers positions, shape and motion information in a three-dimensional world coordinate system, it can be employed to recognize diverse traffic violations or to supply intelligent vehicles with valuable traffic information. We build on YOLOv3 as a detector yielding 2D bounding boxes and class labels for each vehicle. A 2D detector renders our system much more independent to different camera perspectives as a variety of labeled training data is available. This allows for a good generalization while also being more hardware efficient. The task of 3D tracking based on 2D detections is supported by integrating class specific prior knowledge about the vehicle shape. We quantitatively evaluate UTS using self generated synthetic data and ground truth from the CARLA simulator, due to the non-existence of datasets with an urban vehicle surveillance setting and labeled 3D bounding boxes. Additionally, we give a qualitative impression of how UTS performs on real-world data. Our implementation is capable of operating in real time on a reasonably modern workstation. To the best of our knowledge, UTS is to date the only 3D vehicle tracking system in a surveillance scenario (static camera observing moving targets).
Joint Epipolar Tracking (JET): Simultaneous optimization of epipolar geometry and feature correspondences
Mar 15, 2017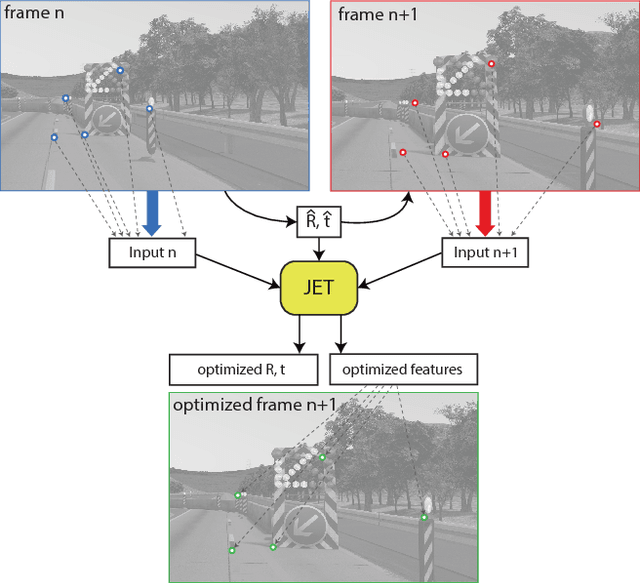
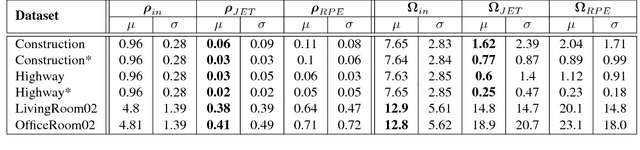
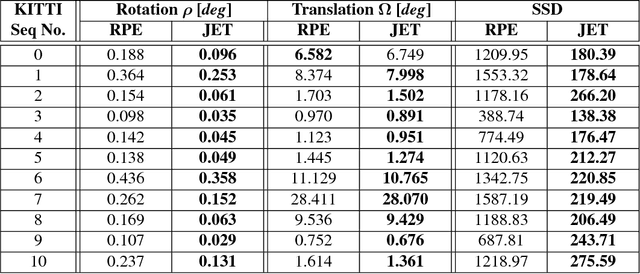
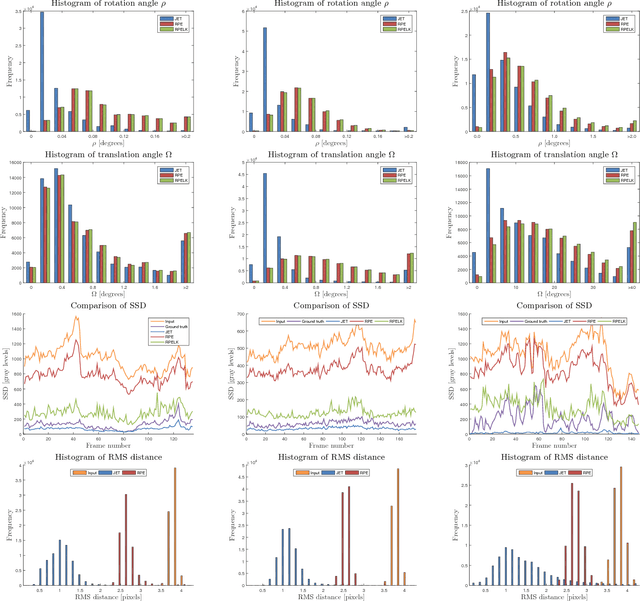
Traditionally, pose estimation is considered as a two step problem. First, feature correspondences are determined by direct comparison of image patches, or by associating feature descriptors. In a second step, the relative pose and the coordinates of corresponding points are estimated, most often by minimizing the reprojection error (RPE). RPE optimization is based on a loss function that is merely aware of the feature pixel positions but not of the underlying image intensities. In this paper, we propose a sparse direct method which introduces a loss function that allows to simultaneously optimize the unscaled relative pose, as well as the set of feature correspondences directly considering the image intensity values. Furthermore, we show how to integrate statistical prior information on the motion into the optimization process. This constructive inclusion of a Bayesian bias term is particularly efficient in application cases with a strongly predictable (short term) dynamic, e.g. in a driving scenario. In our experiments, we demonstrate that the JET algorithm we propose outperforms the classical reprojection error optimization on two synthetic datasets and on the KITTI dataset. The JET algorithm runs in real-time on a single CPU thread.
Learning Rank Reduced Interpolation with Principal Component Analysis
Mar 15, 2017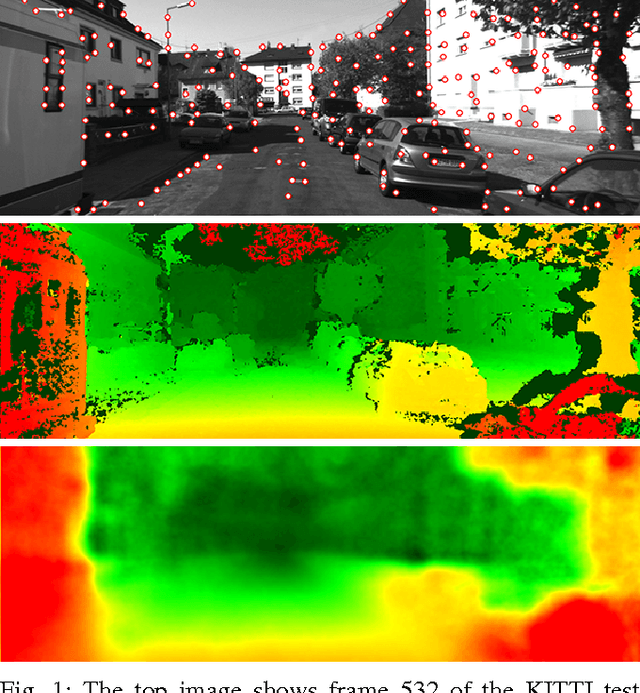

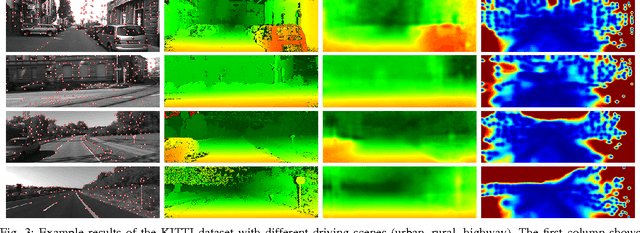

In computer vision most iterative optimization algorithms, both sparse and dense, rely on a coarse and reliable dense initialization to bootstrap their optimization procedure. For example, dense optical flow algorithms profit massively in speed and robustness if they are initialized well in the basin of convergence of the used loss function. The same holds true for methods as sparse feature tracking when initial flow or depth information for new features at arbitrary positions is needed. This makes it extremely important to have techniques at hand that allow to obtain from only very few available measurements a dense but still approximative sketch of a desired 2D structure (e.g. depth maps, optical flow, disparity maps, etc.). The 2D map is regarded as sample from a 2D random process. The method presented here exploits the complete information given by the principal component analysis (PCA) of that process, the principal basis and its prior distribution. The method is able to determine a dense reconstruction from sparse measurement. When facing situations with only very sparse measurements, typically the number of principal components is further reduced which results in a loss of expressiveness of the basis. We overcome this problem and inject prior knowledge in a maximum a posterior (MAP) approach. We test our approach on the KITTI and the virtual KITTI datasets and focus on the interpolation of depth maps for driving scenes. The evaluation of the results show good agreement to the ground truth and are clearly better than results of interpolation by the nearest neighbor method which disregards statistical information.