 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Sequencing of Object-Centric Manipulation Skills for Industrial Tasks
Aug 24, 2020
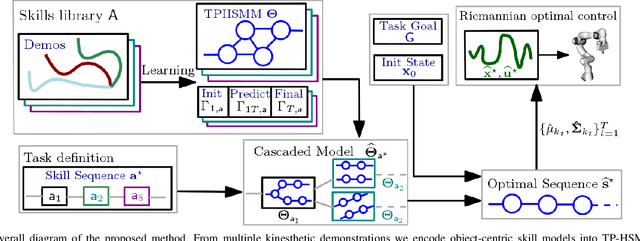
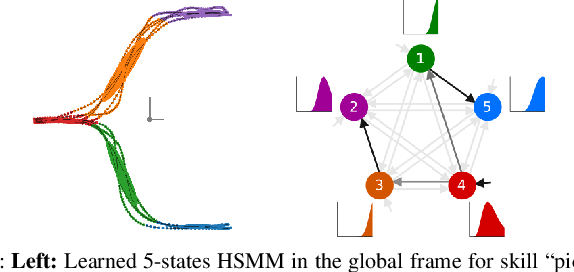

Enabling robots to quickly learn manipulation skills is an important, yet challenging problem. Such manipulation skills should be flexible, e.g., be able adapt to the current workspace configuration. Furthermore, to accomplish complex manipulation tasks, robots should be able to sequence several skills and adapt them to changing situations. In this work, we propose a rapid robot skill-sequencing algorithm, where the skills are encoded by object-centric hidden semi-Markov models. The learned skill models can encode multimodal (temporal and spatial) trajectory distributions. This approach significantly reduces manual modeling efforts, while ensuring a high degree of flexibility and re-usability of learned skills. Given a task goal and a set of generic skills, our framework computes smooth transitions between skill instances. To compute the corresponding optimal end-effector trajectory in task space we rely on Riemannian optimal controller. We demonstrate this approach on a 7 DoF robot arm for industrial assembly tasks.
SDNet: Semantically Guided Depth Estimation Network
Jul 24, 2019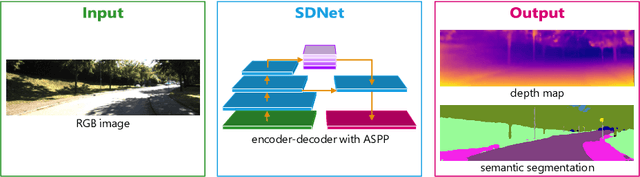
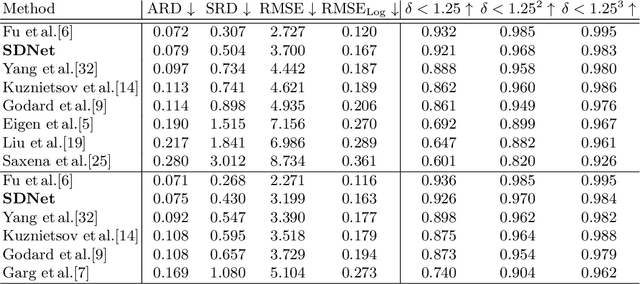
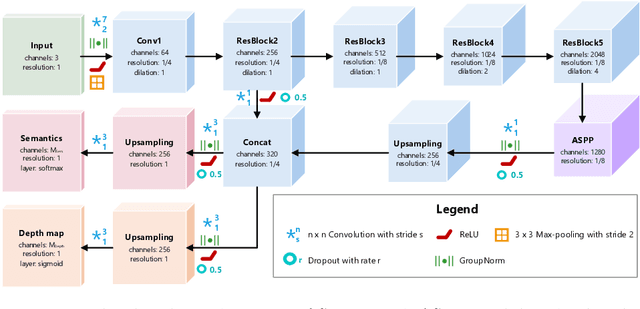
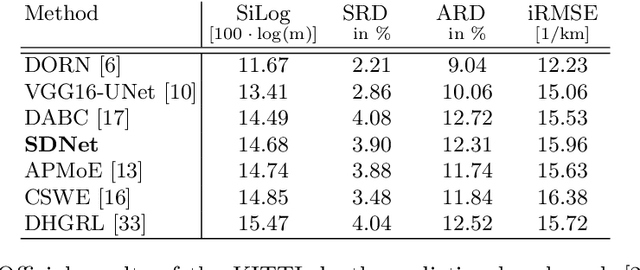
Autonomous vehicles and robots require a full scene understanding of the environment to interact with it. Such a perception typically incorporates pixel-wise knowledge of the depths and semantic labels for each image from a video sensor. Recent learning-based methods estimate both types of information independently using two separate CNNs. In this paper, we propose a model that is able to predict both outputs simultaneously, which leads to improved results and even reduced computational costs compared to independent estimation of depth and semantics. We also empirically prove that the CNN is capable of learning more meaningful and semantically richer features. Furthermore, our SDNet estimates the depth based on ordinal classification. On the basis of these two enhancements, our proposed method achieves state-of-the-art results in semantic segmentation and depth estimation from single monocular input images on two challenging datasets.
DistanceNet: Estimating Traveled Distance from Monocular Images using a Recurrent Convolutional Neural Network
Apr 17, 2019



Classical monocular vSLAM/VO methods suffer from the scale ambiguity problem. Hybrid approaches solve this problem by adding deep learning methods, for example by using depth maps which are predicted by a CNN. We suggest that it is better to base scale estimation on estimating the traveled distance for a set of subsequent images. In this paper, we propose a novel end-to-end many-to-one traveled distance estimator. By using a deep recurrent convolutional neural network (RCNN), the traveled distance between the first and last image of a set of consecutive frames is estimated by our DistanceNet. Geometric features are learned in the CNN part of our model, which are subsequently used by the RNN to learn dynamics and temporal information. Moreover, we exploit the natural order of distances by using ordinal regression to predict the distance. The evaluation on the KITTI dataset shows that our approach outperforms current state-of-the-art deep learning pose estimators and classical mono vSLAM/VO methods in terms of distance prediction. Thus, our DistanceNet can be used as a component to solve the scale problem and help improve current and future classical mono vSLAM/VO methods.
Joint Epipolar Tracking (JET): Simultaneous optimization of epipolar geometry and feature correspondences
Mar 15, 2017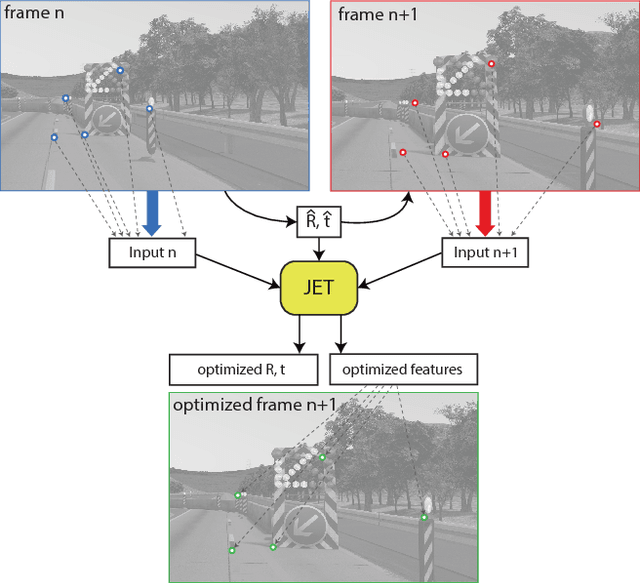
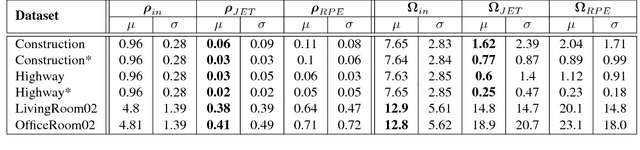
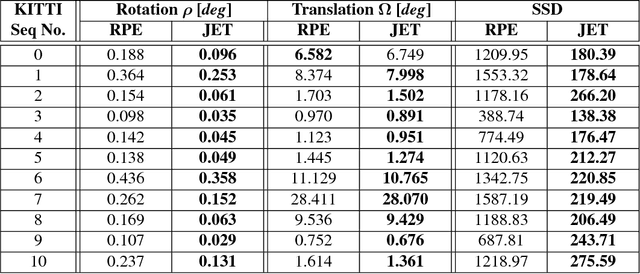
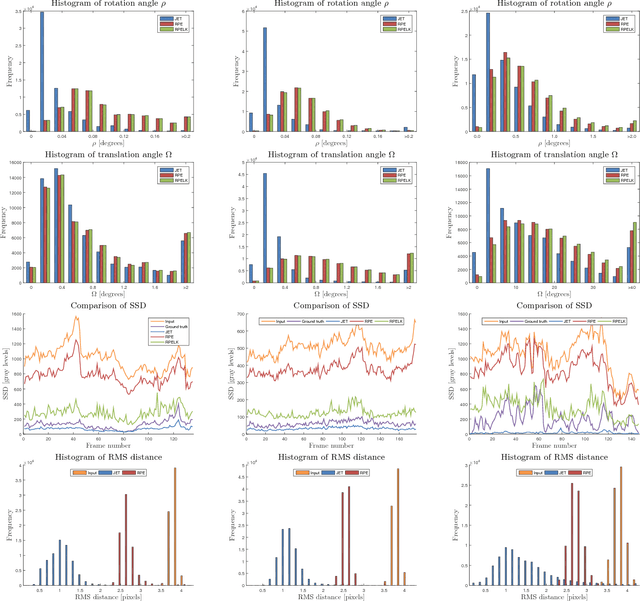
Traditionally, pose estimation is considered as a two step problem. First, feature correspondences are determined by direct comparison of image patches, or by associating feature descriptors. In a second step, the relative pose and the coordinates of corresponding points are estimated, most often by minimizing the reprojection error (RPE). RPE optimization is based on a loss function that is merely aware of the feature pixel positions but not of the underlying image intensities. In this paper, we propose a sparse direct method which introduces a loss function that allows to simultaneously optimize the unscaled relative pose, as well as the set of feature correspondences directly considering the image intensity values. Furthermore, we show how to integrate statistical prior information on the motion into the optimization process. This constructive inclusion of a Bayesian bias term is particularly efficient in application cases with a strongly predictable (short term) dynamic, e.g. in a driving scenario. In our experiments, we demonstrate that the JET algorithm we propose outperforms the classical reprojection error optimization on two synthetic datasets and on the KITTI dataset. The JET algorithm runs in real-time on a single CPU thread.
Learning Rank Reduced Interpolation with Principal Component Analysis
Mar 15, 2017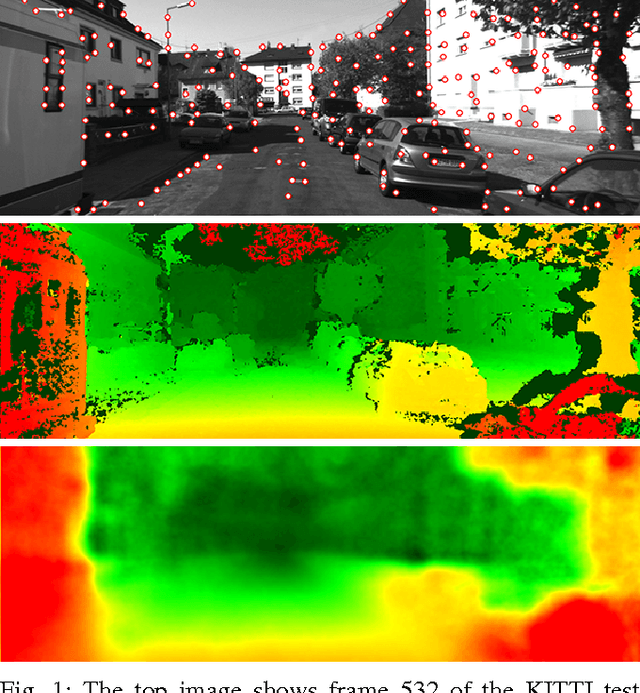

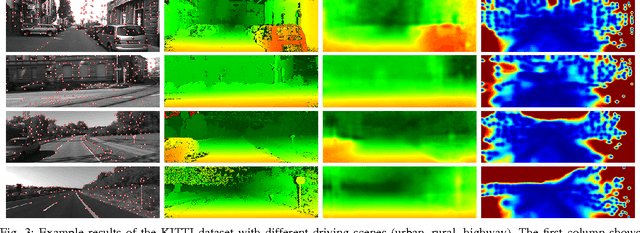

In computer vision most iterative optimization algorithms, both sparse and dense, rely on a coarse and reliable dense initialization to bootstrap their optimization procedure. For example, dense optical flow algorithms profit massively in speed and robustness if they are initialized well in the basin of convergence of the used loss function. The same holds true for methods as sparse feature tracking when initial flow or depth information for new features at arbitrary positions is needed. This makes it extremely important to have techniques at hand that allow to obtain from only very few available measurements a dense but still approximative sketch of a desired 2D structure (e.g. depth maps, optical flow, disparity maps, etc.). The 2D map is regarded as sample from a 2D random process. The method presented here exploits the complete information given by the principal component analysis (PCA) of that process, the principal basis and its prior distribution. The method is able to determine a dense reconstruction from sparse measurement. When facing situations with only very sparse measurements, typically the number of principal components is further reduced which results in a loss of expressiveness of the basis. We overcome this problem and inject prior knowledge in a maximum a posterior (MAP) approach. We test our approach on the KITTI and the virtual KITTI datasets and focus on the interpolation of depth maps for driving scenes. The evaluation of the results show good agreement to the ground truth and are clearly better than results of interpolation by the nearest neighbor method which disregards statistical information.