 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffFuSR: Super-Resolution of all Sentinel-2 Multispectral Bands using Diffusion Models
Jun 13, 2025This paper presents DiffFuSR, a modular pipeline for super-resolving all 12 spectral bands of Sentinel-2 Level-2A imagery to a unified ground sampling distance (GSD) of 2.5 meters. The pipeline comprises two stages: (i) a diffusion-based super-resolution (SR) model trained on high-resolution RGB imagery from the NAIP and WorldStrat datasets, harmonized to simulate Sentinel-2 characteristics; and (ii) a learned fusion network that upscales the remaining multispectral bands using the super-resolved RGB image as a spatial prior. We introduce a robust degradation model and contrastive degradation encoder to support blind SR. Extensive evaluations of the proposed SR pipeline on the OpenSR benchmark demonstrate that the proposed method outperforms current SOTA baselines in terms of reflectance fidelity, spectral consistency, spatial alignment, and hallucination suppression. Furthermore, the fusion network significantly outperforms classical pansharpening approaches, enabling accurate enhancement of Sentinel-2's 20 m and 60 m bands. This study underscores the power of harmonized learning with generative priors and fusion strategies to create a modular framework for Sentinel-2 SR. Our code and models can be found at https://github.com/NorskRegnesentral/DiffFuSR.
FullFormer: Generating Shapes Inside Shapes
Mar 20, 2023Implicit generative models have been widely employed to model 3D data and have recently proven to be successful in encoding and generating high-quality 3D shapes. This work builds upon these models and alleviates current limitations by presenting the first implicit generative model that facilitates the generation of complex 3D shapes with rich internal geometric details. To achieve this, our model uses unsigned distance fields to represent nested 3D surfaces allowing learning from non-watertight mesh data. We propose a transformer-based autoregressive model for 3D shape generation that leverages context-rich tokens from vector quantized shape embeddings. The generated tokens are decoded into an unsigned distance field which is rendered into a novel 3D shape exhibiting a rich internal structure. We demonstrate that our model achieves state-of-the-art point cloud generation results on popular classes of 'Cars', 'Planes', and 'Chairs' of the ShapeNet dataset. Additionally, we curate a dataset that exclusively comprises shapes with realistic internal details from the `Cars' class of ShapeNet and demonstrate our method's efficacy in generating these shapes with internal geometry.
Explaining Deep Neural Networks for Point Clouds using Gradient-based Visualisations
Jul 26, 2022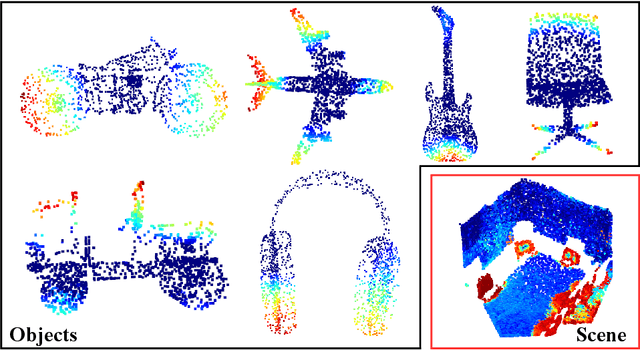
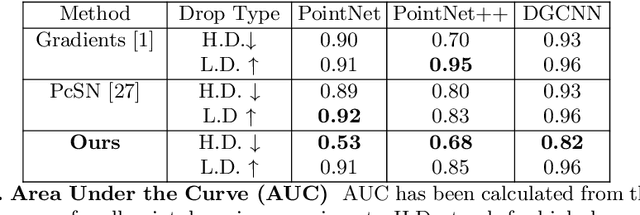


Explaining decisions made by deep neural networks is a rapidly advancing research topic. In recent years, several approaches have attempted to provide visual explanations of decisions made by neural networks designed for structured 2D image input data. In this paper, we propose a novel approach to generate coarse visual explanations of networks designed to classify unstructured 3D data, namely point clouds. Our method uses gradients flowing back to the final feature map layers and maps these values as contributions of the corresponding points in the input point cloud. Due to dimensionality disagreement and lack of spatial consistency between input points and final feature maps, our approach combines gradients with points dropping to compute explanations of different parts of the point cloud iteratively. The generality of our approach is tested on various point cloud classification networks, including 'single object' networks PointNet, PointNet++, DGCNN, and a 'scene' network VoteNet. Our method generates symmetric explanation maps that highlight important regions and provide insight into the decision-making process of network architectures. We perform an exhaustive evaluation of trust and interpretability of our explanation method against comparative approaches using quantitative, quantitative and human studies. All our code is implemented in PyTorch and will be made publicly available.
LightSAL: Lightweight Sign Agnostic Learning for Implicit Surface Representation
Mar 26, 2021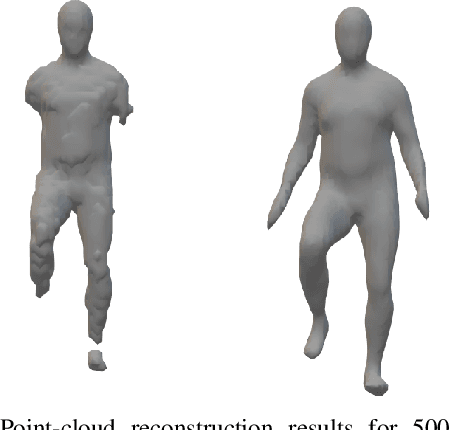

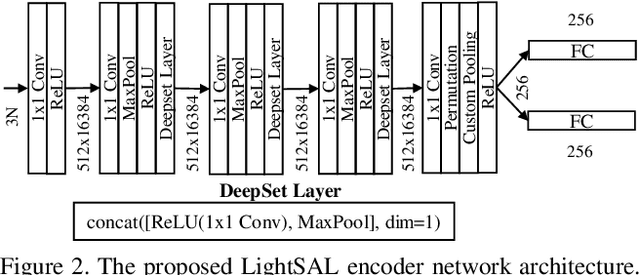

Recently, several works have addressed modeling of 3D shapes using deep neural networks to learn implicit surface representations. Up to now, the majority of works have concentrated on reconstruction quality, paying little or no attention to model size or training time. This work proposes LightSAL, a novel deep convolutional architecture for learning 3D shapes; the proposed work concentrates on efficiency both in network training time and resulting model size. We build on the recent concept of Sign Agnostic Learning for training the proposed network, relying on signed distance fields, with unsigned distance as ground truth. In the experimental section of the paper, we demonstrate that the proposed architecture outperforms previous work in model size and number of required training iterations, while achieving equivalent accuracy. Experiments are based on the D-Faust dataset that contains 41k 3D scans of human shapes. The proposed model has been implemented in PyTorch.
RL-GAN-Net: A Reinforcement Learning Agent Controlled GAN Network for Real-Time Point Cloud Shape Completion
Apr 28, 2019


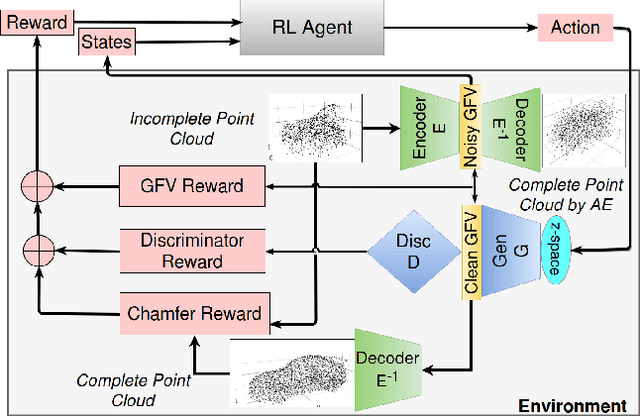
We present RL-GAN-Net, where a reinforcement learning (RL) agent provides fast and robust control of a generative adversarial network (GAN). Our framework is applied to point cloud shape completion that converts noisy, partial point cloud data into a high-fidelity completed shape by controlling the GAN. While a GAN is unstable and hard to train, we circumvent the problem by (1) training the GAN on the latent space representation whose dimension is reduced compared to the raw point cloud input and (2) using an RL agent to find the correct input to the GAN to generate the latent space representation of the shape that best fits the current input of incomplete point cloud. The suggested pipeline robustly completes point cloud with large missing regions. To the best of our knowledge, this is the first attempt to train an RL agent to control the GAN, which effectively learns the highly nonlinear mapping from the input noise of the GAN to the latent space of point cloud. The RL agent replaces the need for complex optimization and consequently makes our technique real time. Additionally, we demonstrate that our pipelines can be used to enhance the classification accuracy of point cloud with missing data.
Finding Correspondences for Optical Flow and Disparity Estimations using a Sub-pixel Convolution-based Encoder-Decoder Network
Oct 07, 2018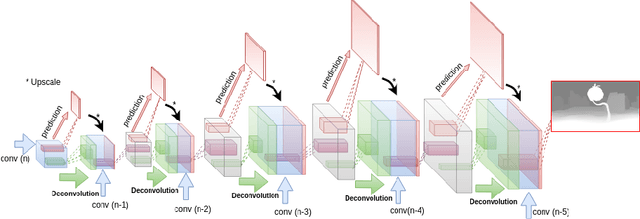
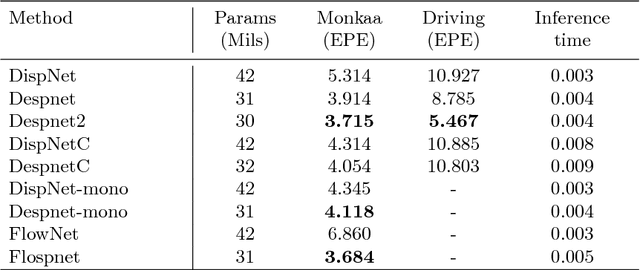
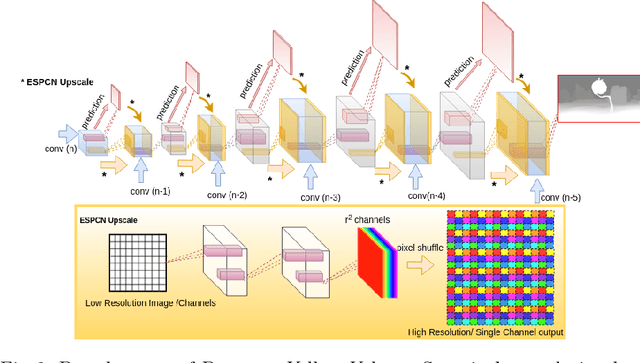
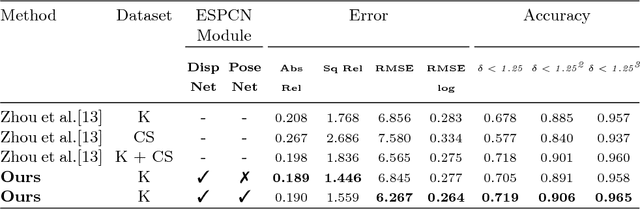
Deep convolutional neural networks (DCNN) have recently shown promising results in low-level computer vision problems such as optical flow and disparity estimation, but still, have much room to further improve their performance. In this paper, we propose a novel sub-pixel convolution-based encoder-decoder network for optical flow and disparity estimations, which can extend FlowNetS and DispNet by replacing the deconvolution layers with sup-pixel convolution blocks. By using sub-pixel refinement and estimation on the decoder stages instead of deconvolution, we can significantly improve the estimation accuracy for optical flow and disparity, even with reduced numbers of parameters. We show a supervised end-to-end training of our proposed networks for optical flow and disparity estimations, and an unsupervised end-to-end training for monocular depth and pose estimations. In order to verify the effectiveness of our proposed networks, we perform intensive experiments for (i) optical flow and disparity estimations, and (ii) monocular depth and pose estimations. Throughout the extensive experiments, our proposed networks outperform the baselines such as FlowNetS and DispNet in terms of estimation accuracy and training times.