 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Global and Local Attentions for Heavy Rain Removal on Single Images
Apr 16, 2021
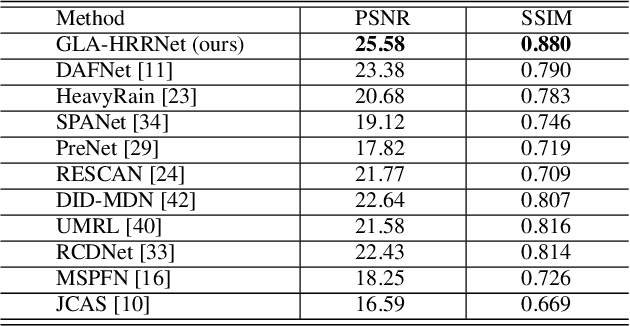
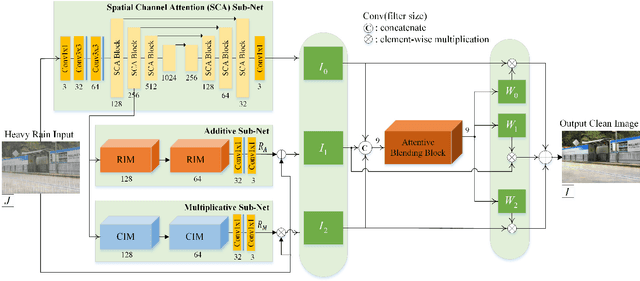

Heavy rain removal from a single image is the task of simultaneously eliminating rain streaks and fog, which can dramatically degrade the quality of captured images. Most existing rain removal methods do not generalize well for the heavy rain case. In this work, we propose a novel network architecture consisting of three sub-networks to remove heavy rain from a single image without estimating rain streaks and fog separately. The first sub-net, a U-net-based architecture that incorporates our Spatial Channel Attention (SCA) blocks, extracts global features that provide sufficient contextual information needed to remove atmospheric distortions caused by rain and fog. The second sub-net learns the additive residues information, which is useful in removing rain streak artifacts via our proposed Residual Inception Modules (RIM). The third sub-net, the multiplicative sub-net, adopts our Channel-attentive Inception Modules (CIM) and learns the essential brighter local features which are not effectively extracted in the SCA and additive sub-nets by modulating the local pixel intensities in the derained images. Our three clean image results are then combined via an attentive blending block to generate the final clean image. Our method with SCA, RIM, and CIM significantly outperforms the previous state-of-the-art single-image deraining methods on the synthetic datasets, shows considerably cleaner and sharper derained estimates on the real image datasets. We present extensive experiments and ablation studies supporting each of our method's contributions on both synthetic and real image datasets.
Forget About the LiDAR: Self-Supervised Depth Estimators with MED Probability Volumes
Aug 09, 2020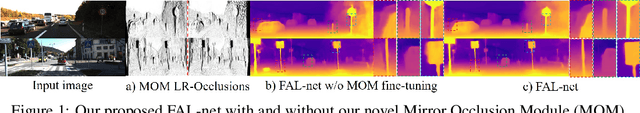
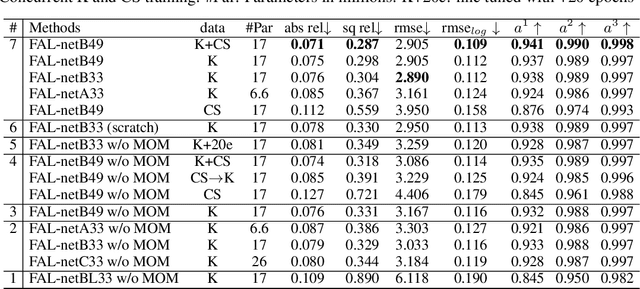
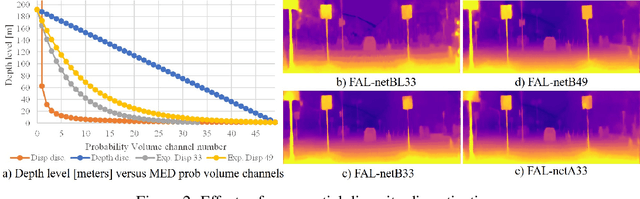
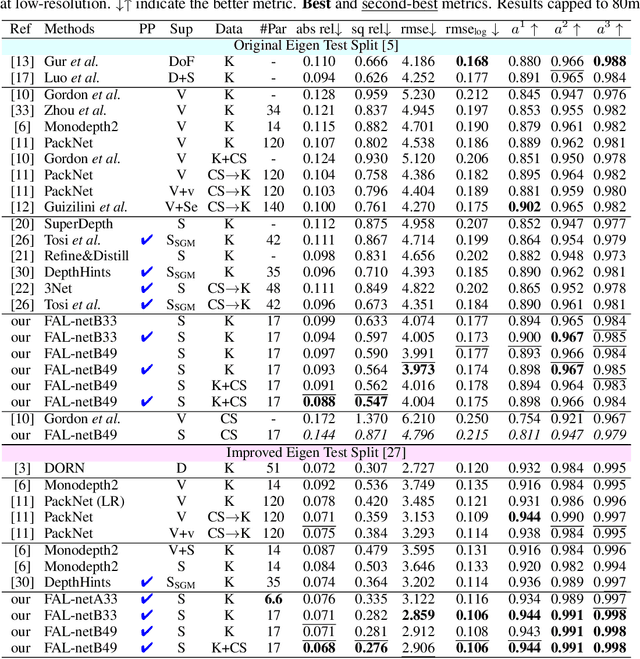
Self-supervised depth estimators have recently shown results comparable to the supervised methods on the challenging single image depth estimation (SIDE) task, by exploiting the geometrical relations between target and reference views in the training data. However, previous methods usually learn forward or backward image synthesis, but not depth estimation, as they cannot effectively neglect occlusions between the target and the reference images. Previous works rely on rigid photometric assumptions or the SIDE network to infer depth and occlusions, resulting in limited performance. On the other hand, we propose a method to "Forget About the LiDAR" (FAL), for the training of depth estimators, with Mirrored Exponential Disparity (MED) probability volumes, from which we obtain geometrically inspired occlusion maps with our novel Mirrored Occlusion Module (MOM). Our MOM does not impose a burden on our FAL-net. Contrary to the previous methods that learn SIDE from stereo pairs by regressing disparity in the linear space, our FAL-net regresses disparity by binning it into the exponential space, which allows for better detection of distant and nearby objects. We define a two-step training strategy for our FAL-net: It is first trained for view synthesis and then fine-tuned for depth estimation with our MOM. Our FAL-net is remarkably light-weight and outperforms the previous state-of-the-art methods with 8x fewer parameters and 3x faster inference speeds on the challenging KITTI dataset. We present extensive experimental results on the KITTI, CityScapes, and Make3D datasets to verify our method's effectiveness. To the authors' best knowledge, the presented method performs the best among all the previous self-supervised methods until now.
A HVS-inspired Attention Map to Improve CNN-based Perceptual Losses for Image Restoration
Mar 30, 2019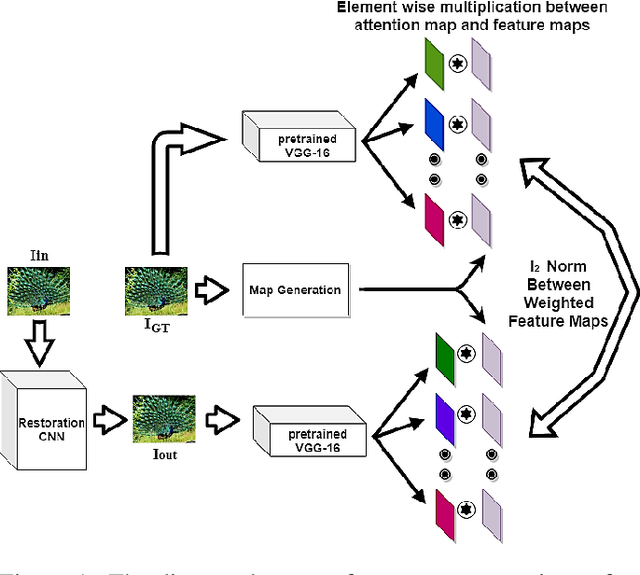
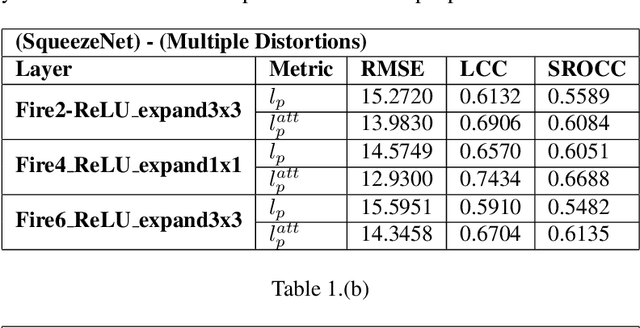
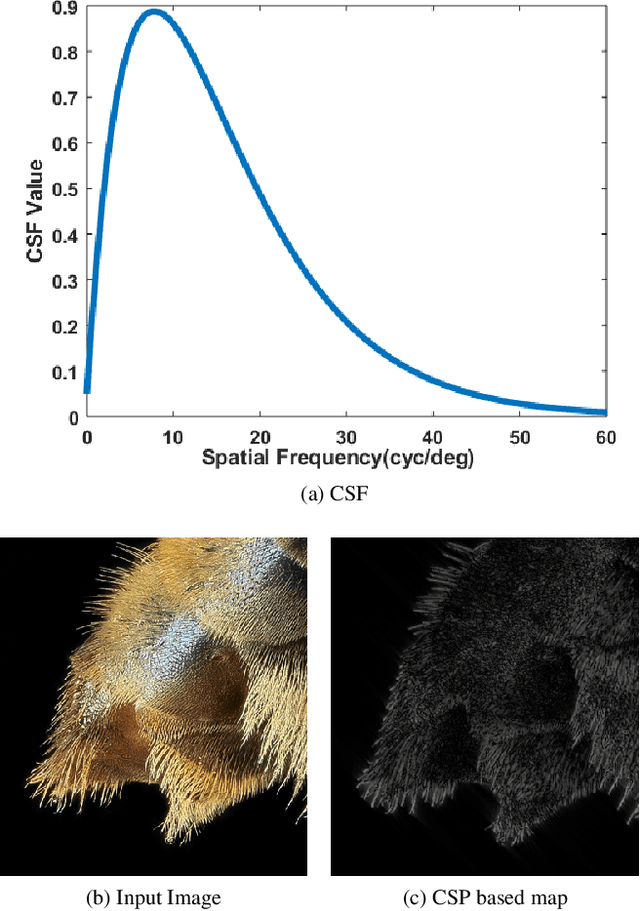
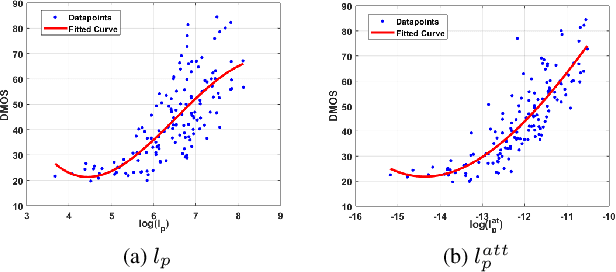
Deep Convolutional Neural Network (CNN) features have been demonstrated to be effective perceptual quality features. The perceptual loss, based on feature maps of pre-trained CNN's has proven to be remarkably effective for CNN based perceptual image restoration problems. In this work, taking inspiration from the the Human Visual System (HVS) and our visual perception, we propose a spatial attention mechanism based on the dependency human contrast sensitivity on spatial frequency. We identify regions in input images, based on underlying spatial frequency where the visual system might be most sensitive to distortions. Based on this prior, we design an attention map that is applied to feature maps in the perceptual loss, helping it to identify regions that are of more perceptual importance. The results will demonstrate that the proposed technique helps improving the correlation of the perceptual loss with human subjective assessment of perceptual quality and also results in a loss which delivers a better perception-distortion trade-off compared to the widely used perceptual loss in CNN based image restoration problems.
Finding Correspondences for Optical Flow and Disparity Estimations using a Sub-pixel Convolution-based Encoder-Decoder Network
Oct 07, 2018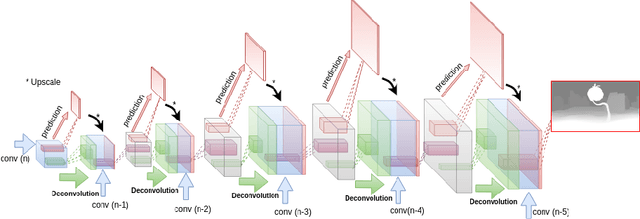
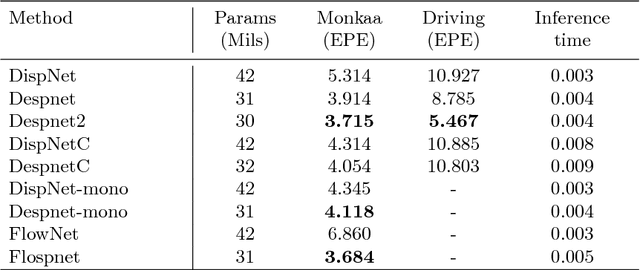
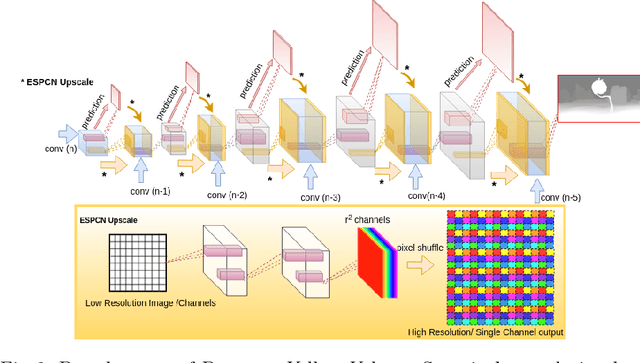
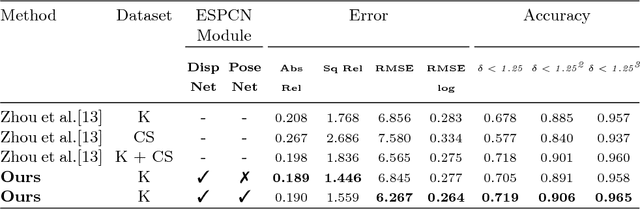
Deep convolutional neural networks (DCNN) have recently shown promising results in low-level computer vision problems such as optical flow and disparity estimation, but still, have much room to further improve their performance. In this paper, we propose a novel sub-pixel convolution-based encoder-decoder network for optical flow and disparity estimations, which can extend FlowNetS and DispNet by replacing the deconvolution layers with sup-pixel convolution blocks. By using sub-pixel refinement and estimation on the decoder stages instead of deconvolution, we can significantly improve the estimation accuracy for optical flow and disparity, even with reduced numbers of parameters. We show a supervised end-to-end training of our proposed networks for optical flow and disparity estimations, and an unsupervised end-to-end training for monocular depth and pose estimations. In order to verify the effectiveness of our proposed networks, we perform intensive experiments for (i) optical flow and disparity estimations, and (ii) monocular depth and pose estimations. Throughout the extensive experiments, our proposed networks outperform the baselines such as FlowNetS and DispNet in terms of estimation accuracy and training times.