 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Depth Perception in Foveated Rendering
Jan 28, 2025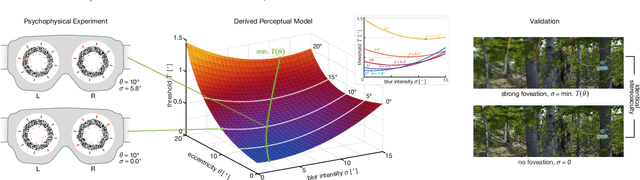
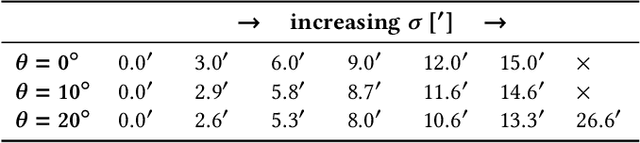
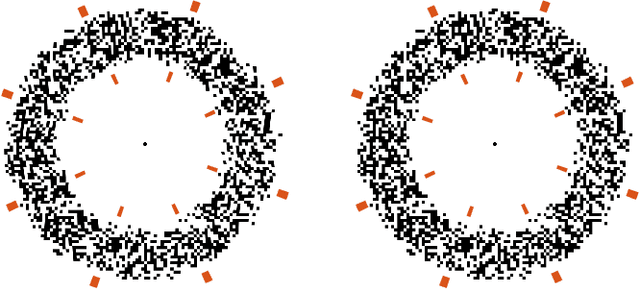
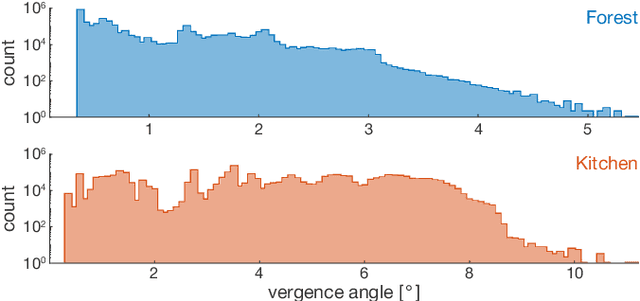
The true vision for real-time virtual and augmented reality is reproducing our visual reality in its entirety on immersive displays. To this end, foveated rendering leverages the limitations of spatial acuity in human peripheral vision to allocate computational resources to the fovea while reducing quality in the periphery. Such methods are often derived from studies on the spatial resolution of the human visual system and its ability to perceive blur in the periphery, enabling the potential for high spatial quality in real-time. However, the effects of blur on other visual cues that depend on luminance contrast, such as depth, remain largely unexplored. It is critical to understand this interplay, as accurate depth representation is a fundamental aspect of visual realism. In this paper, we present the first evaluation exploring the effects of foveated rendering on stereoscopic depth perception. We design a psychovisual experiment to quantitatively study the effects of peripheral blur on depth perception. Our analysis demonstrates that stereoscopic acuity remains unaffected (or even improves) by high levels of peripheral blur. Based on our studies, we derive a simple perceptual model that determines the amount of foveation that does not affect stereoacuity. Furthermore, we analyze the model in the context of common foveation practices reported in literature. The findings indicate that foveated rendering does not impact stereoscopic depth perception, and stereoacuity remains unaffected up to 2x stronger foveation than commonly used. Finally, we conduct a validation experiment and show that our findings hold for complex natural stimuli.
Perceptually Optimized Super Resolution
Nov 26, 2024



Modern deep-learning based super-resolution techniques process images and videos independently of the underlying content and viewing conditions. However, the sensitivity of the human visual system to image details changes depending on the underlying content characteristics, such as spatial frequency, luminance, color, contrast, or motion. This observation hints that computational resources spent on up-sampling visual content may be wasted whenever a viewer cannot resolve the results. Motivated by this observation, we propose a perceptually inspired and architecture-agnostic approach for controlling the visual quality and efficiency of super-resolution techniques. The core is a perceptual model that dynamically guides super-resolution methods according to the human's sensitivity to image details. Our technique leverages the limitations of the human visual system to improve the efficiency of super-resolution techniques by focusing computational resources on perceptually important regions; judged on the basis of factors such as adapting luminance, contrast, spatial frequency, motion, and viewing conditions. We demonstrate the application of our proposed model in combination with network branching, and network complexity reduction to improve the computational efficiency of super-resolution methods without visible quality loss. Quantitative and qualitative evaluations, including user studies, demonstrate the effectiveness of our approach in reducing FLOPS by factors of 2$\mathbf{x}$ and greater, without sacrificing perceived quality.
Noise-based Enhancement for Foveated Rendering
Apr 09, 2022
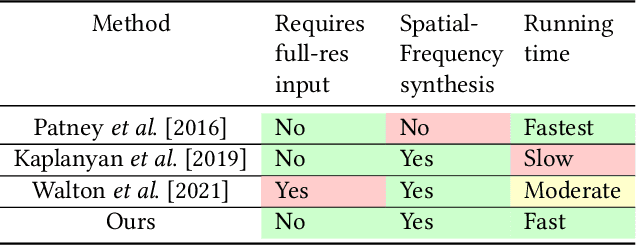
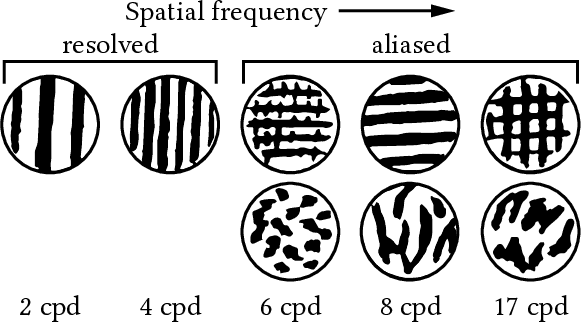
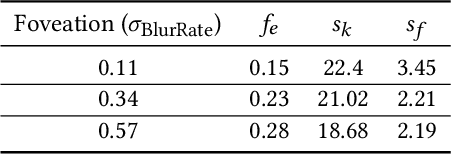
Human visual sensitivity to spatial details declines towards the periphery. Novel image synthesis techniques, so-called foveated rendering, exploit this observation and reduce the spatial resolution of synthesized images for the periphery, avoiding the synthesis of high-spatial-frequency details that are costly to generate but not perceived by a viewer. However, contemporary techniques do not make a clear distinction between the range of spatial frequencies that must be reproduced and those that can be omitted. For a given eccentricity, there is a range of frequencies that are detectable but not resolvable. While the accurate reproduction of these frequencies is not required, an observer can detect their absence if completely omitted. We use this observation to improve the performance of existing foveated rendering techniques. We demonstrate that this specific range of frequencies can be efficiently replaced with procedural noise whose parameters are carefully tuned to image content and human perception. Consequently, these frequencies do not have to be synthesized during rendering, allowing more aggressive foveation, and they can be replaced by noise generated in a less expensive post-processing step, leading to improved performance of the rendering system. Our main contribution is a perceptually-inspired technique for deriving the parameters of the noise required for the enhancement and its calibration. The method operates on rendering output and runs at rates exceeding 200FPS at 4K resolution, making it suitable for integration with real-time foveated rendering systems for VR and AR devices. We validate our results and compare them to the existing contrast enhancement technique in user experiments.
A HVS-inspired Attention Map to Improve CNN-based Perceptual Losses for Image Restoration
Mar 30, 2019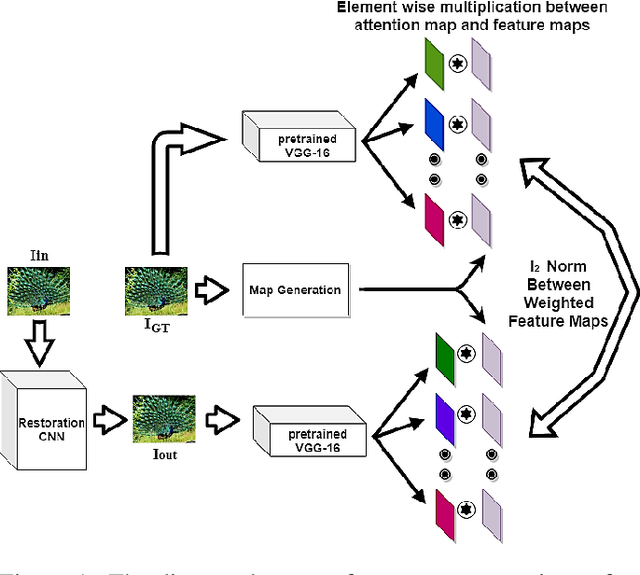
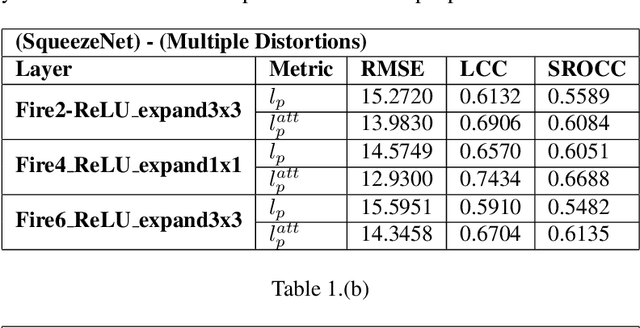
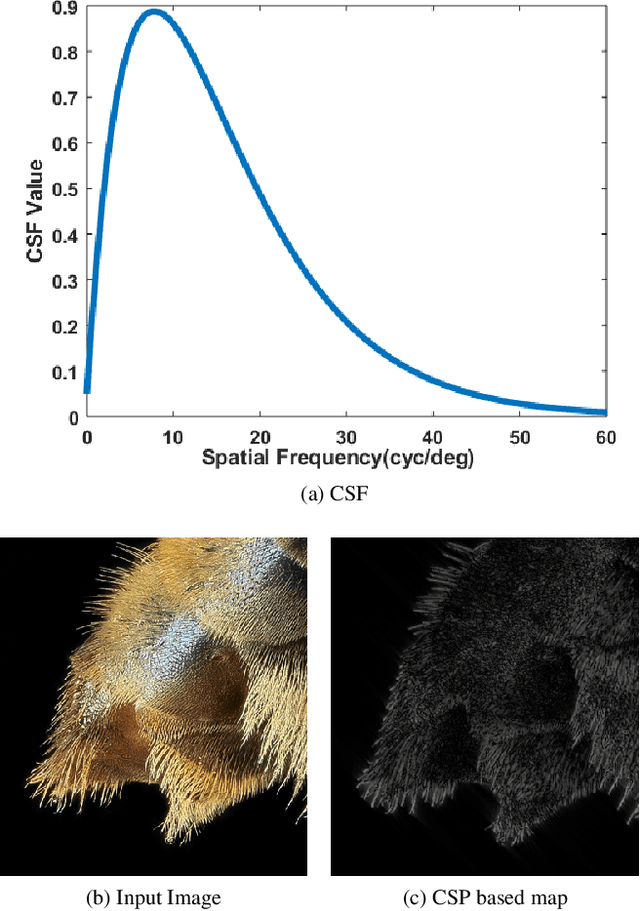
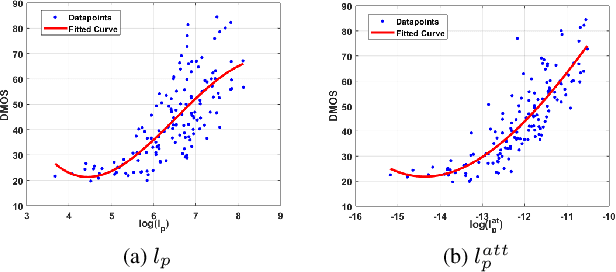
Deep Convolutional Neural Network (CNN) features have been demonstrated to be effective perceptual quality features. The perceptual loss, based on feature maps of pre-trained CNN's has proven to be remarkably effective for CNN based perceptual image restoration problems. In this work, taking inspiration from the the Human Visual System (HVS) and our visual perception, we propose a spatial attention mechanism based on the dependency human contrast sensitivity on spatial frequency. We identify regions in input images, based on underlying spatial frequency where the visual system might be most sensitive to distortions. Based on this prior, we design an attention map that is applied to feature maps in the perceptual loss, helping it to identify regions that are of more perceptual importance. The results will demonstrate that the proposed technique helps improving the correlation of the perceptual loss with human subjective assessment of perceptual quality and also results in a loss which delivers a better perception-distortion trade-off compared to the widely used perceptual loss in CNN based image restoration problems.
A Psychovisual Analysis on Deep CNN Features for Perceptual Metrics and A Novel Psychovisual Loss
Dec 02, 2018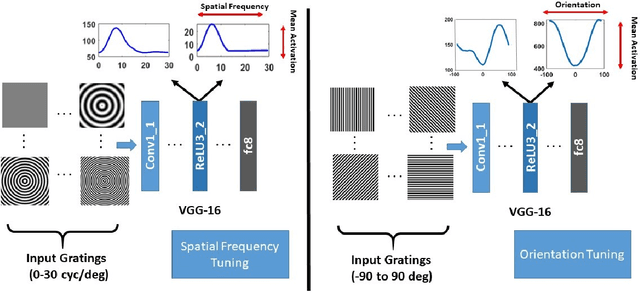
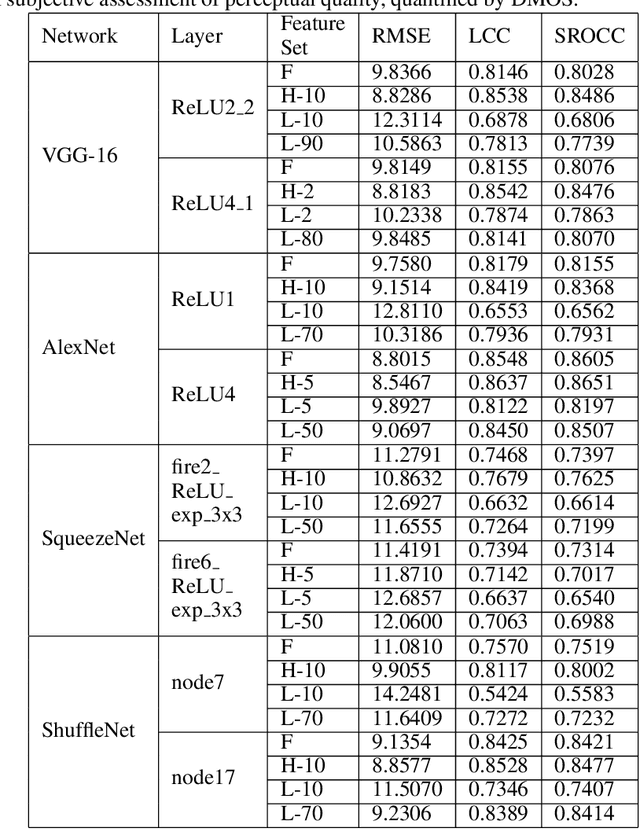

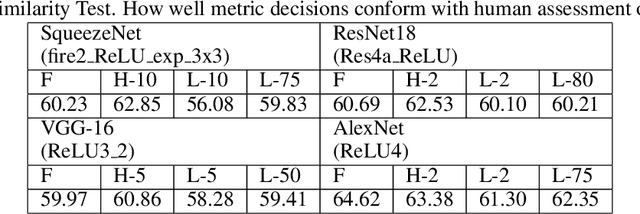
The efficacy of Deep Convolutional Neural Network (CNN) features as perceptual metrics has been demonstrated by researchers. Nevertheless, any thorough analysis in the context of human visual perception on 'why deep CNN features perform well as perceptual metrics?', 'Which layers are better?', 'Which feature maps are better?' and most importantly, 'Why they are better?' has not been studied. In this paper, we address these issues and provide an analysis for deep CNN features in terms of Human Visual System (HVS) characteristics. We scrutinize the frequency tuning of feature maps in a trained deep CNN (e.g., VGG-16) by applying grating stimuli of different spatial frequencies as input, presenting a novel analytical technique that may help us to better understand and compare characteristics of CNNs with the human brain. We observe that feature maps behave as spatial frequency-selective filters which can be best explained by the well-established 'spatial frequency theory' for the visual cortex. We analyze the frequency sensitivity of deep features in relation to the human contrast sensitivity function. Based on this, we design a novel Visual Frequency Sensitivity Score (VFSS) to explain and quantify the efficacy of feature maps as perceptual metrics. Based on our psychovisual analysis, we propose a weighting mechanism to discriminate between feature maps on the basis of their perceptual properties and use this weighting to improve the VGG perceptual loss. The proposed psychovisual loss results in reconstructions with less distortion and better perceptive visual quality.