 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Spherical Harmonics: Rethinking Appearance Models for Radiance Reconstruction
Jun 08, 2026View-dependent appearance modeling remains a challenging problem in novel-view synthesis and reconstruction. Accurately representing complex angular effects often requires substantial memory and computational resources. For new learning-based methods, a common approach is to rely on SH. However, capturing high-frequency phenomena such as specular reflections demands high-order expansions, which increase memory usage and computational cost. Consequently, most methods employ low-order SH, which limits the ability to model complex view-dependent effects, resulting in overly smooth or diffuse representations. To address these limitations, we systematically evaluate a wide range of spherical functions in the context of scene reconstruction. Some of them are introduced to graphics and computer vision for the first time in this paper. Based on the insights from the experiment, we develop a novel spherical formulation, the Normalized Anisotropic Spherical Gabor function that enables efficient modeling and learning of high-frequency appearance effects while maintaining compact representation. Compared to existing approaches, our function achieves higher-quality reconstruction of view-dependent phenomena such as glints, while being up to five times more memory-efficient and more efficient to evaluate. We validate its performance in radiance-field reconstruction tasks.
Neural Harmonic Textures for High-Quality Primitive Based Neural Reconstruction
Apr 01, 2026Primitive-based methods such as 3D Gaussian Splatting have recently become the state-of-the-art for novel-view synthesis and related reconstruction tasks. Compared to neural fields, these representations are more flexible, adaptive, and scale better to large scenes. However, the limited expressivity of individual primitives makes modeling high-frequency detail challenging. We introduce Neural Harmonic Textures, a neural representation approach that anchors latent feature vectors on a virtual scaffold surrounding each primitive. These features are interpolated within the primitive at ray intersection points. Inspired by Fourier analysis, we apply periodic activations to the interpolated features, turning alpha blending into a weighted sum of harmonic components. The resulting signal is then decoded in a single deferred pass using a small neural network, significantly reducing computational cost. Neural Harmonic Textures yield state-of-the-art results in real-time novel view synthesis while bridging the gap between primitive- and neural-field-based reconstruction. Our method integrates seamlessly into existing primitive-based pipelines such as 3DGUT, Triangle Splatting, and 2DGS. We further demonstrate its generality with applications to 2D image fitting and semantic reconstruction.
Gabor Fields: Orientation-Selective Level-of-Detail for Volume Rendering
Feb 04, 2026Gaussian-based representations have enabled efficient physically-based volume rendering at a fraction of the memory cost of regular, discrete, voxel-based distributions. However, several remaining issues hamper their widespread use. One of the advantages of classic voxel grids is the ease of constructing hierarchical representations by either storing volumetric mipmaps or selectively pruning branches of an already hierarchical voxel grid. Such strategies reduce rendering time and eliminate aliasing when lower levels of detail are required. Constructing similar strategies for Gaussian-based volumes is not trivial. Straightforward solutions, such as prefiltering or computing mipmap-style representations, lead to increased memory requirements or expensive re-fitting of each level separately. Additionally, such solutions do not guarantee a smooth transition between different hierarchy levels. To address these limitations, we propose Gabor Fields, an orientation-selective mixture of Gabor kernels that enables continuous frequency filtering at no cost. The frequency content of the asset is reduced by selectively pruning primitives, directly benefiting rendering performance. Beyond filtering, we demonstrate that stochastically sampling from different frequencies and orientations at each ray recursion enables masking substantial portions of the volume, accelerating ray traversal time in single- and multiple-scattering settings. Furthermore, inspired by procedural volumes, we present an application for efficient design and rendering of procedural clouds as Gabor-noise-modulated Gaussians.
Temporal Brightness Management for Immersive Content
Jan 24, 2025



Modern virtual reality headsets demand significant computational resources to render high-resolution content in real-time. Therefore, prioritizing power efficiency becomes crucial, particularly for portable versions reliant on batteries. A significant portion of the energy consumed by these systems is attributed to their displays. Dimming the screen can save a considerable amount of energy; however, it may also result in a loss of visible details and contrast in the displayed content. While contrast may be partially restored by applying post-processing contrast enhancement steps, our work is orthogonal to these approaches, and focuses on optimal temporal modulation of screen brightness. We propose a technique that modulates brightness over time while minimizing the potential loss of visible details and avoiding noticeable temporal instability. Given a predetermined power budget and a video sequence, we achieve this by measuring contrast loss through band decomposition of the luminance image and optimizing the brightness level of each frame offline to ensure uniform temporal contrast loss. We evaluate our method through a series of subjective experiments and an ablation study, on a variety of content. We showcase its power-saving capabilities in practice using a built-in hardware proxy. Finally, we present an online version of our approach which further emphasizes the potential for low level vision models to be leveraged in power saving settings to preserve content quality.
Perceptually Optimized Super Resolution
Nov 26, 2024



Modern deep-learning based super-resolution techniques process images and videos independently of the underlying content and viewing conditions. However, the sensitivity of the human visual system to image details changes depending on the underlying content characteristics, such as spatial frequency, luminance, color, contrast, or motion. This observation hints that computational resources spent on up-sampling visual content may be wasted whenever a viewer cannot resolve the results. Motivated by this observation, we propose a perceptually inspired and architecture-agnostic approach for controlling the visual quality and efficiency of super-resolution techniques. The core is a perceptual model that dynamically guides super-resolution methods according to the human's sensitivity to image details. Our technique leverages the limitations of the human visual system to improve the efficiency of super-resolution techniques by focusing computational resources on perceptually important regions; judged on the basis of factors such as adapting luminance, contrast, spatial frequency, motion, and viewing conditions. We demonstrate the application of our proposed model in combination with network branching, and network complexity reduction to improve the computational efficiency of super-resolution methods without visible quality loss. Quantitative and qualitative evaluations, including user studies, demonstrate the effectiveness of our approach in reducing FLOPS by factors of 2$\mathbf{x}$ and greater, without sacrificing perceived quality.
Puzzle Similarity: A Perceptually-guided No-Reference Metric for Artifact Detection in 3D Scene Reconstructions
Nov 26, 2024


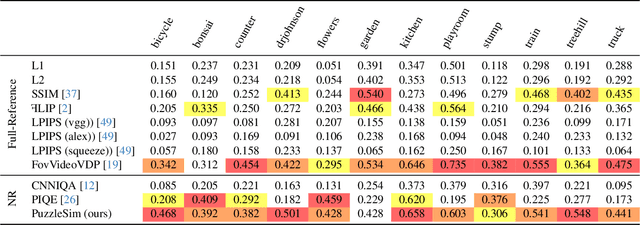
Modern reconstruction techniques can effectively model complex 3D scenes from sparse 2D views. However, automatically assessing the quality of novel views and identifying artifacts is challenging due to the lack of ground truth images and the limitations of no-reference image metrics in predicting detailed artifact maps. The absence of such quality metrics hinders accurate predictions of the quality of generated views and limits the adoption of post-processing techniques, such as inpainting, to enhance reconstruction quality. In this work, we propose a new no-reference metric, Puzzle Similarity, which is designed to localize artifacts in novel views. Our approach utilizes image patch statistics from the input views to establish a scene-specific distribution that is later used to identify poorly reconstructed regions in the novel views. We test and evaluate our method in the context of 3D reconstruction; to this end, we collected a novel dataset of human quality assessment in unseen reconstructed views. Through this dataset, we demonstrate that our method can not only successfully localize artifacts in novel views, correlating with human assessment, but do so without direct references. Surprisingly, our metric outperforms both no-reference metrics and popular full-reference image metrics. We can leverage our new metric to enhance applications like automatic image restoration, guided acquisition, or 3D reconstruction from sparse inputs.
Volumetric Primitives for Modeling and Rendering Scattering and Emissive Media
May 24, 2024



We propose a volumetric representation based on primitives to model scattering and emissive media. Accurate scene representations enabling efficient rendering are essential for many computer graphics applications. General and unified representations that can handle surface and volume-based representations simultaneously, allowing for physically accurate modeling, remain a research challenge. Inspired by recent methods for scene reconstruction that leverage mixtures of 3D Gaussians to model radiance fields, we formalize and generalize the modeling of scattering and emissive media using mixtures of simple kernel-based volumetric primitives. We introduce closed-form solutions for transmittance and free-flight distance sampling for 3D Gaussian kernels, and propose several optimizations to use our method efficiently within any off-the-shelf volumetric path tracer by leveraging ray tracing for efficiently querying the medium. We demonstrate our method as an alternative to other forms of volume modeling (e.g. voxel grid-based representations) for forward and inverse rendering of scattering media. Furthermore, we adapt our method to the problem of radiance field optimization and rendering, and demonstrate comparable performance to the state of the art, while providing additional flexibility in terms of performance and usability.
A Learned Radiance-Field Representation for Complex Luminaires
Jul 11, 2022



We propose an efficient method for rendering complex luminaires using a high-quality octree-based representation of the luminaire emission. Complex luminaires are a particularly challenging problem in rendering, due to their caustic light paths inside the luminaire. We reduce the geometric complexity of luminaires by using a simple proxy geometry and encode the visually-complex emitted light field by using a neural radiance field. We tackle the multiple challenges of using NeRFs for representing luminaires, including their high dynamic range, high-frequency content and null-emission areas, by proposing a specialized loss function. For rendering, we distill our luminaires' NeRF into a Plenoctree, which we can be easily integrated into traditional rendering systems. Our approach allows for speed-ups of up to 2 orders of magnitude in scenes containing complex luminaires introducing minimal error.
* 10 pages, 7 figures. Eurographics Proceedings (EGSR 2022, Symposium-only track) (https://diglib.eg.org/handle/10.2312/sr20221155)