 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Brightness Management for Immersive Content
Jan 24, 2025Modern virtual reality headsets demand significant computational resources to render high-resolution content in real-time. Therefore, prioritizing power efficiency becomes crucial, particularly for portable versions reliant on batteries. A significant portion of the energy consumed by these systems is attributed to their displays. Dimming the screen can save a considerable amount of energy; however, it may also result in a loss of visible details and contrast in the displayed content. While contrast may be partially restored by applying post-processing contrast enhancement steps, our work is orthogonal to these approaches, and focuses on optimal temporal modulation of screen brightness. We propose a technique that modulates brightness over time while minimizing the potential loss of visible details and avoiding noticeable temporal instability. Given a predetermined power budget and a video sequence, we achieve this by measuring contrast loss through band decomposition of the luminance image and optimizing the brightness level of each frame offline to ensure uniform temporal contrast loss. We evaluate our method through a series of subjective experiments and an ablation study, on a variety of content. We showcase its power-saving capabilities in practice using a built-in hardware proxy. Finally, we present an online version of our approach which further emphasizes the potential for low level vision models to be leveraged in power saving settings to preserve content quality.
Learning Foveated Reconstruction to Preserve Perceived Image Statistics
Aug 07, 2021



Foveated image reconstruction recovers full image from a sparse set of samples distributed according to the human visual system's retinal sensitivity that rapidly drops with eccentricity. Recently, the use of Generative Adversarial Networks was shown to be a promising solution for such a task as they can successfully hallucinate missing image information. Like for other supervised learning approaches, also for this one, the definition of the loss function and training strategy heavily influences the output quality. In this work, we pose the question of how to efficiently guide the training of foveated reconstruction techniques such that they are fully aware of the human visual system's capabilities and limitations, and therefore, reconstruct visually important image features. Due to the nature of GAN-based solutions, we concentrate on the human's sensitivity to hallucination for different input sample densities. We present new psychophysical experiments, a dataset, and a procedure for training foveated image reconstruction. The strategy provides flexibility to the generator network by penalizing only perceptually important deviations in the output. As a result, the method aims to preserve perceived image statistics rather than natural image statistics. We evaluate our strategy and compare it to alternative solutions using a newly trained objective metric and user experiments.
Emotion Recognition in the Wild using Deep Neural Networks and Bayesian Classifiers
Sep 12, 2017

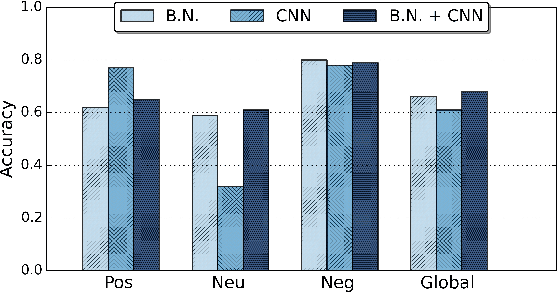
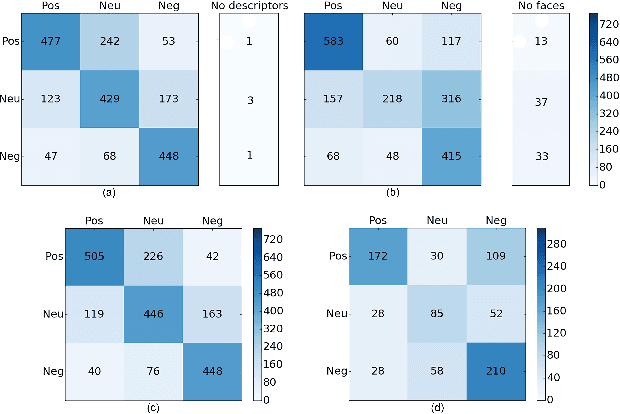
Group emotion recognition in the wild is a challenging problem, due to the unstructured environments in which everyday life pictures are taken. Some of the obstacles for an effective classification are occlusions, variable lighting conditions, and image quality. In this work we present a solution based on a novel combination of deep neural networks and Bayesian classifiers. The neural network works on a bottom-up approach, analyzing emotions expressed by isolated faces. The Bayesian classifier estimates a global emotion integrating top-down features obtained through a scene descriptor. In order to validate the system we tested the framework on the dataset released for the Emotion Recognition in the Wild Challenge 2017. Our method achieved an accuracy of 64.68% on the test set, significantly outperforming the 53.62% competition baseline.