 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEDiff: Latent Exposure Diffusion for HDR Generation
Dec 19, 2024While consumer displays increasingly support more than 10 stops of dynamic range, most image assets such as internet photographs and generative AI content remain limited to 8-bit low dynamic range (LDR), constraining their utility across high dynamic range (HDR) applications. Currently, no generative model can produce high-bit, high-dynamic range content in a generalizable way. Existing LDR-to-HDR conversion methods often struggle to produce photorealistic details and physically-plausible dynamic range in the clipped areas. We introduce LEDiff, a method that enables a generative model with HDR content generation through latent space fusion inspired by image-space exposure fusion techniques. It also functions as an LDR-to-HDR converter, expanding the dynamic range of existing low-dynamic range images. Our approach uses a small HDR dataset to enable a pretrained diffusion model to recover detail and dynamic range in clipped highlights and shadows. LEDiff brings HDR capabilities to existing generative models and converts any LDR image to HDR, creating photorealistic HDR outputs for image generation, image-based lighting (HDR environment map generation), and photographic effects such as depth of field simulation, where linear HDR data is essential for realistic quality.
Learning Images Across Scales Using Adversarial Training
Jun 13, 2024



The real world exhibits rich structure and detail across many scales of observation. It is difficult, however, to capture and represent a broad spectrum of scales using ordinary images. We devise a novel paradigm for learning a representation that captures an orders-of-magnitude variety of scales from an unstructured collection of ordinary images. We treat this collection as a distribution of scale-space slices to be learned using adversarial training, and additionally enforce coherency across slices. Our approach relies on a multiscale generator with carefully injected procedural frequency content, which allows to interactively explore the emerging continuous scale space. Training across vastly different scales poses challenges regarding stability, which we tackle using a supervision scheme that involves careful sampling of scales. We show that our generator can be used as a multiscale generative model, and for reconstructions of scale spaces from unstructured patches. Significantly outperforming the state of the art, we demonstrate zoom-in factors of up to 256x at high quality and scale consistency.
Cinematic Gaussians: Real-Time HDR Radiance Fields with Depth of Field
Jun 11, 2024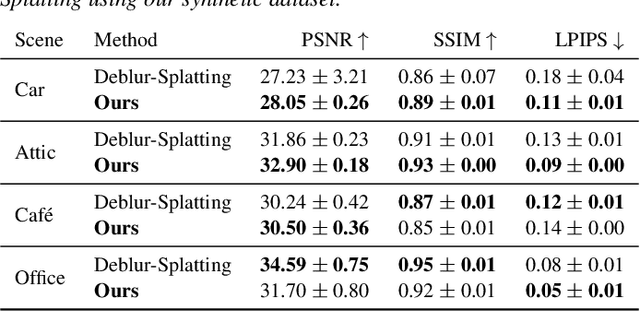

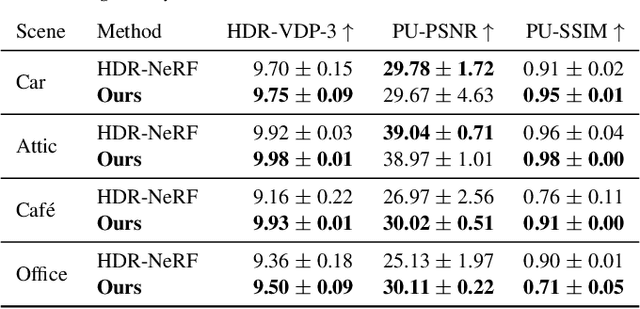

Radiance field methods represent the state of the art in reconstructing complex scenes from multi-view photos. However, these reconstructions often suffer from one or both of the following limitations: First, they typically represent scenes in low dynamic range (LDR), which restricts their use to evenly lit environments and hinders immersive viewing experiences. Secondly, their reliance on a pinhole camera model, assuming all scene elements are in focus in the input images, presents practical challenges and complicates refocusing during novel-view synthesis. Addressing these limitations, we present a lightweight method based on 3D Gaussian Splatting that utilizes multi-view LDR images of a scene with varying exposure times, apertures, and focus distances as input to reconstruct a high-dynamic-range (HDR) radiance field. By incorporating analytical convolutions of Gaussians based on a thin-lens camera model as well as a tonemapping module, our reconstructions enable the rendering of HDR content with flexible refocusing capabilities. We demonstrate that our combined treatment of HDR and depth of field facilitates real-time cinematic rendering, outperforming the state of the art.
Exposure Diffusion: HDR Image Generation by Consistent LDR denoising
May 23, 2024


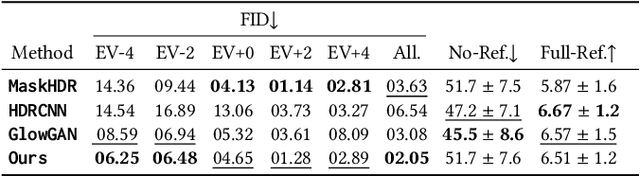
We demonstrate generating high-dynamic range (HDR) images using the concerted action of multiple black-box, pre-trained low-dynamic range (LDR) image diffusion models. Common diffusion models are not HDR as, first, there is no sufficiently large HDR image dataset available to re-train them, and second, even if it was, re-training such models is impossible for most compute budgets. Instead, we seek inspiration from the HDR image capture literature that traditionally fuses sets of LDR images, called "brackets", to produce a single HDR image. We operate multiple denoising processes to generate multiple LDR brackets that together form a valid HDR result. To this end, we introduce an exposure consistency term into the diffusion process to couple the brackets such that they agree across the exposure range they share. We demonstrate HDR versions of state-of-the-art unconditional and conditional as well as restoration-type (LDR2HDR) generative modeling.
Joint Sampling and Optimisation for Inverse Rendering
Sep 27, 2023
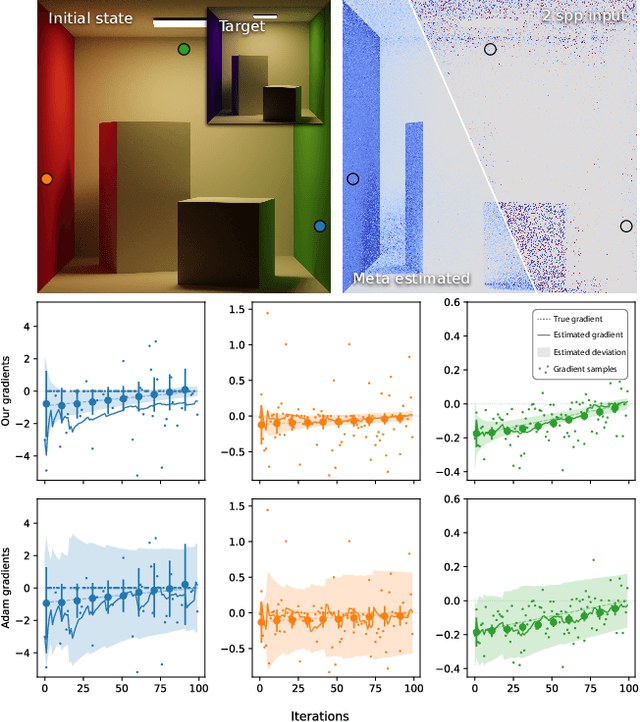
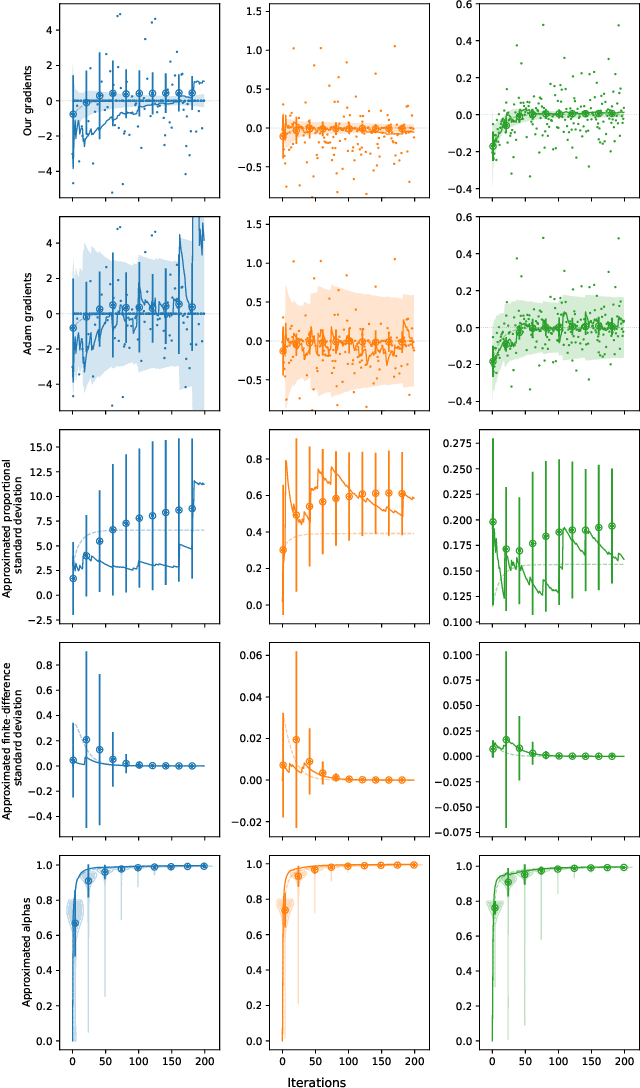

When dealing with difficult inverse problems such as inverse rendering, using Monte Carlo estimated gradients to optimise parameters can slow down convergence due to variance. Averaging many gradient samples in each iteration reduces this variance trivially. However, for problems that require thousands of optimisation iterations, the computational cost of this approach rises quickly. We derive a theoretical framework for interleaving sampling and optimisation. We update and reuse past samples with low-variance finite-difference estimators that describe the change in the estimated gradients between each iteration. By combining proportional and finite-difference samples, we continuously reduce the variance of our novel gradient meta-estimators throughout the optimisation process. We investigate how our estimator interlinks with Adam and derive a stable combination. We implement our method for inverse path tracing and demonstrate how our estimator speeds up convergence on difficult optimisation tasks.
Enhancing image quality prediction with self-supervised visual masking
May 31, 2023Full-reference image quality metrics (FR-IQMs) aim to measure the visual differences between a pair of reference and distorted images, with the goal of accurately predicting human judgments. However, existing FR-IQMs, including traditional ones like PSNR and SSIM and even perceptual ones such as HDR-VDP, LPIPS, and DISTS, still fall short in capturing the complexities and nuances of human perception. In this work, rather than devising a novel IQM model, we seek to improve upon the perceptual quality of existing FR-IQM methods. We achieve this by considering visual masking, an important characteristic of the human visual system that changes its sensitivity to distortions as a function of local image content. Specifically, for a given FR-IQM metric, we propose to predict a visual masking model that modulates reference and distorted images in a way that penalizes the visual errors based on their visibility. Since the ground truth visual masks are difficult to obtain, we demonstrate how they can be derived in a self-supervised manner solely based on mean opinion scores (MOS) collected from an FR-IQM dataset. Our approach results in enhanced FR-IQM metrics that are more in line with human prediction both visually and quantitatively.
Revisiting Image Deblurring with an Efficient ConvNet
Feb 04, 2023Image deblurring aims to recover the latent sharp image from its blurry counterpart and has a wide range of applications in computer vision. The Convolution Neural Networks (CNNs) have performed well in this domain for many years, and until recently an alternative network architecture, namely Transformer, has demonstrated even stronger performance. One can attribute its superiority to the multi-head self-attention (MHSA) mechanism, which offers a larger receptive field and better input content adaptability than CNNs. However, as MHSA demands high computational costs that grow quadratically with respect to the input resolution, it becomes impractical for high-resolution image deblurring tasks. In this work, we propose a unified lightweight CNN network that features a large effective receptive field (ERF) and demonstrates comparable or even better performance than Transformers while bearing less computational costs. Our key design is an efficient CNN block dubbed LaKD, equipped with a large kernel depth-wise convolution and spatial-channel mixing structure, attaining comparable or larger ERF than Transformers but with a smaller parameter scale. Specifically, we achieve +0.17dB / +0.43dB PSNR over the state-of-the-art Restormer on defocus / motion deblurring benchmark datasets with 32% fewer parameters and 39% fewer MACs. Extensive experiments demonstrate the superior performance of our network and the effectiveness of each module. Furthermore, we propose a compact and intuitive ERFMeter metric that quantitatively characterizes ERF, and shows a high correlation to the network performance. We hope this work can inspire the research community to further explore the pros and cons of CNN and Transformer architectures beyond image deblurring tasks.
GlowGAN: Unsupervised Learning of HDR Images from LDR Images in the Wild
Nov 23, 2022



Most in-the-wild images are stored in Low Dynamic Range (LDR) form, serving as a partial observation of the High Dynamic Range (HDR) visual world. Despite limited dynamic range, these LDR images are often captured with different exposures, implicitly containing information about the underlying HDR image distribution. Inspired by this intuition, in this work we present, to the best of our knowledge, the first method for learning a generative model of HDR images from in-the-wild LDR image collections in a fully unsupervised manner. The key idea is to train a generative adversarial network (GAN) to generate HDR images which, when projected to LDR under various exposures, are indistinguishable from real LDR images. The projection from HDR to LDR is achieved via a camera model that captures the stochasticity in exposure and camera response function. Experiments show that our method GlowGAN can synthesize photorealistic HDR images in many challenging cases such as landscapes, lightning, or windows, where previous supervised generative models produce overexposed images. We further demonstrate the new application of unsupervised inverse tone mapping (ITM) enabled by GlowGAN. Our ITM method does not need HDR images or paired multi-exposure images for training, yet it reconstructs more plausible information for overexposed regions than state-of-the-art supervised learning models trained on such data.
Video frame interpolation for high dynamic range sequences captured with dual-exposure sensors
Jun 19, 2022

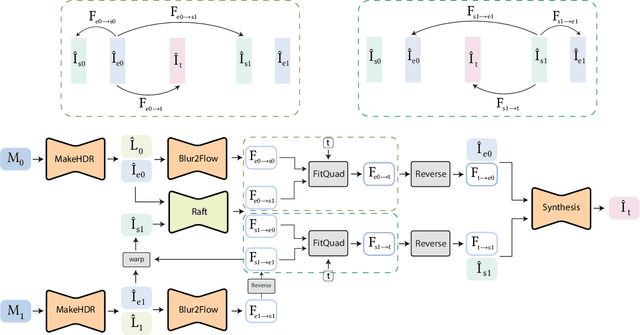

Video frame interpolation (VFI) enables many important applications that might involve the temporal domain, such as slow motion playback, or the spatial domain, such as stop motion sequences. We are focusing on the former task, where one of the key challenges is handling high dynamic range (HDR) scenes in the presence of complex motion. To this end, we explore possible advantages of dual-exposure sensors that readily provide sharp short and blurry long exposures that are spatially registered and whose ends are temporally aligned. This way, motion blur registers temporally continuous information on the scene motion that, combined with the sharp reference, enables more precise motion sampling within a single camera shot. We demonstrate that this facilitates a more complex motion reconstruction in the VFI task, as well as HDR frame reconstruction that so far has been considered only for the originally captured frames, not in-between interpolated frames. We design a neural network trained in these tasks that clearly outperforms existing solutions. We also propose a metric for scene motion complexity that provides important insights into the performance of VFI methods at the test time.
Eikonal Fields for Refractive Novel-View Synthesis
Feb 11, 2022
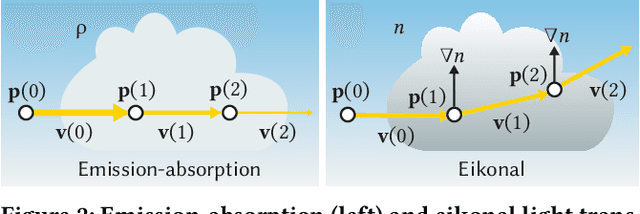

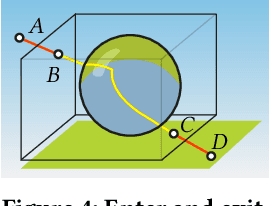
We tackle the problem of generating novel-view images from collections of 2D images showing refractive and reflective objects. Current solutions assume opaque or transparent light transport along straight paths following the emission-absorption model. Instead, we optimize for a field of 3D-varying Index of Refraction (IoR) and trace light through it that bends toward the spatial gradients of said IoR according to the laws of eikonal light transport.