 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePocket-Dentist: On-Device Dental Image Understanding via Efficient Multimodal Large Language Models
May 28, 2026Evaluations of dental vision-language models remain fragmented across datasets, task definitions and metrics, and often ignore their computational cost. This limits their widespread deployment for dental screening outside specialist centres, where timely inference, limited hardware, and local handling of patient images are vital for practical, privacy-preserving clinical prescreening. Here we present Pocket-Dentist, an efficiency-aware benchmark for dental multimodal question answering that brings together three datasets spanning approximately 1,159 patients, five task types and seven metrics. Across typical 14 VLMs, our results reveals an interesting observation: compact VLMs (e.g., 2B-parameter models) outperform larger VLMs in accuracy while requiring substantially lower computational costs in dental image understanding. Deployed locally on an iPhone 17 Pro, our finetuned compact VLM Pocket-Dentist-2B processed each sample in 4.31 s, reducing latency by 4.9-fold and memory use by 2.3-fold compared with a 7B baseline.
Revisiting Image Deblurring with an Efficient ConvNet
Feb 04, 2023Image deblurring aims to recover the latent sharp image from its blurry counterpart and has a wide range of applications in computer vision. The Convolution Neural Networks (CNNs) have performed well in this domain for many years, and until recently an alternative network architecture, namely Transformer, has demonstrated even stronger performance. One can attribute its superiority to the multi-head self-attention (MHSA) mechanism, which offers a larger receptive field and better input content adaptability than CNNs. However, as MHSA demands high computational costs that grow quadratically with respect to the input resolution, it becomes impractical for high-resolution image deblurring tasks. In this work, we propose a unified lightweight CNN network that features a large effective receptive field (ERF) and demonstrates comparable or even better performance than Transformers while bearing less computational costs. Our key design is an efficient CNN block dubbed LaKD, equipped with a large kernel depth-wise convolution and spatial-channel mixing structure, attaining comparable or larger ERF than Transformers but with a smaller parameter scale. Specifically, we achieve +0.17dB / +0.43dB PSNR over the state-of-the-art Restormer on defocus / motion deblurring benchmark datasets with 32% fewer parameters and 39% fewer MACs. Extensive experiments demonstrate the superior performance of our network and the effectiveness of each module. Furthermore, we propose a compact and intuitive ERFMeter metric that quantitatively characterizes ERF, and shows a high correlation to the network performance. We hope this work can inspire the research community to further explore the pros and cons of CNN and Transformer architectures beyond image deblurring tasks.
Learning to Deblur using Light Field Generated and Real Defocus Images
Apr 01, 2022

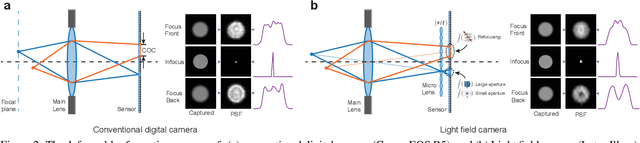
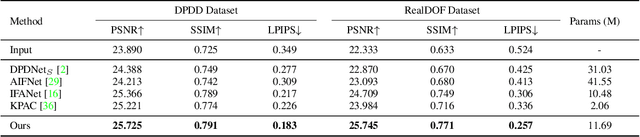
Defocus deblurring is a challenging task due to the spatially varying nature of defocus blur. While deep learning approach shows great promise in solving image restoration problems, defocus deblurring demands accurate training data that consists of all-in-focus and defocus image pairs, which is difficult to collect. Naive two-shot capturing cannot achieve pixel-wise correspondence between the defocused and all-in-focus image pairs. Synthetic aperture of light fields is suggested to be a more reliable way to generate accurate image pairs. However, the defocus blur generated from light field data is different from that of the images captured with a traditional digital camera. In this paper, we propose a novel deep defocus deblurring network that leverages the strength and overcomes the shortcoming of light fields. We first train the network on a light field-generated dataset for its highly accurate image correspondence. Then, we fine-tune the network using feature loss on another dataset collected by the two-shot method to alleviate the differences between the defocus blur exists in the two domains. This strategy is proved to be highly effective and able to achieve the state-of-the-art performance both quantitatively and qualitatively on multiple test sets. Extensive ablation studies have been conducted to analyze the effect of each network module to the final performance.