 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLaGS: Relational Language Gaussian Splatting
Mar 18, 2026Achieving unified 3D perception and reasoning across tasks such as segmentation, retrieval, and relation understanding remains challenging, as existing methods are either object-centric or rely on costly training for inter-object reasoning. We present a novel framework that constructs a hierarchical language-distilled Gaussian scene and its 3D semantic scene graph without scene-specific training. A Gaussian pruning mechanism refines scene geometry, while a robust multi-view language alignment strategy aggregates noisy 2D features into accurate 3D object embeddings. On top of this hierarchy, we build an open-vocabulary 3D scene graph with Vision Language derived annotations and Graph Neural Network-based relational reasoning. Our approach enables efficient and scalable open-vocabulary 3D reasoning by jointly modeling hierarchical semantics and inter/intra-object relationships, validated across tasks including open-vocabulary segmentation, scene graph generation, and relation-guided retrieval. Project page: https://dfki-av.github.io/ReLaGS/
Fine-Grained Uncertainty Decomposition in Large Language Models: A Spectral Approach
Sep 26, 2025As Large Language Models (LLMs) are increasingly integrated in diverse applications, obtaining reliable measures of their predictive uncertainty has become critically important. A precise distinction between aleatoric uncertainty, arising from inherent ambiguities within input data, and epistemic uncertainty, originating exclusively from model limitations, is essential to effectively address each uncertainty source. In this paper, we introduce Spectral Uncertainty, a novel approach to quantifying and decomposing uncertainties in LLMs. Leveraging the Von Neumann entropy from quantum information theory, Spectral Uncertainty provides a rigorous theoretical foundation for separating total uncertainty into distinct aleatoric and epistemic components. Unlike existing baseline methods, our approach incorporates a fine-grained representation of semantic similarity, enabling nuanced differentiation among various semantic interpretations in model responses. Empirical evaluations demonstrate that Spectral Uncertainty outperforms state-of-the-art methods in estimating both aleatoric and total uncertainty across diverse models and benchmark datasets.
Optimal Conformal Prediction under Epistemic Uncertainty
May 25, 2025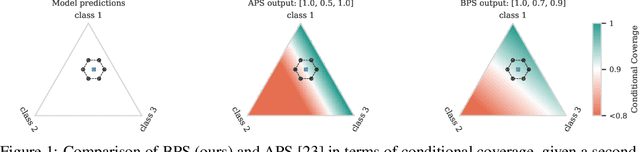

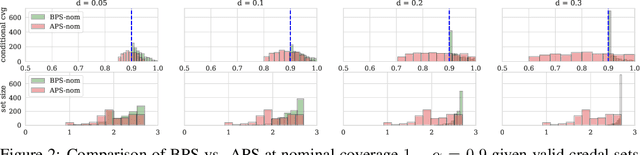
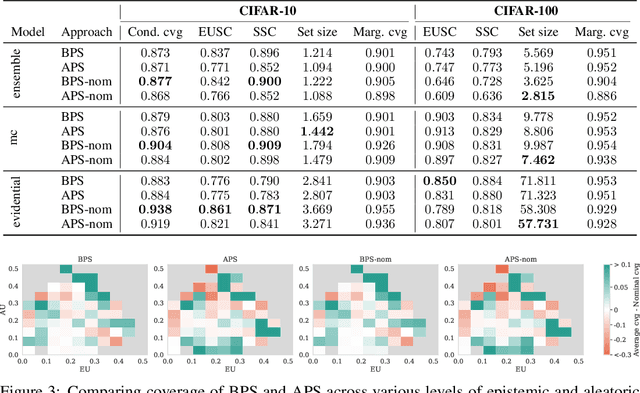
Conformal prediction (CP) is a popular frequentist framework for representing uncertainty by providing prediction sets that guarantee coverage of the true label with a user-adjustable probability. In most applications, CP operates on confidence scores coming from a standard (first-order) probabilistic predictor (e.g., softmax outputs). Second-order predictors, such as credal set predictors or Bayesian models, are also widely used for uncertainty quantification and are known for their ability to represent both aleatoric and epistemic uncertainty. Despite their popularity, there is still an open question on ``how they can be incorporated into CP''. In this paper, we discuss the desiderata for CP when valid second-order predictions are available. We then introduce Bernoulli prediction sets (BPS), which produce the smallest prediction sets that ensure conditional coverage in this setting. When given first-order predictions, BPS reduces to the well-known adaptive prediction sets (APS). Furthermore, when the validity assumption on the second-order predictions is compromised, we apply conformal risk control to obtain a marginal coverage guarantee while still accounting for epistemic uncertainty.
Masked Autoencoder Self Pre-Training for Defect Detection in Microelectronics
Apr 14, 2025



Whereas in general computer vision, transformer-based architectures have quickly become the gold standard, microelectronics defect detection still heavily relies on convolutional neural networks (CNNs). We hypothesize that this is due to the fact that a) transformers have an increased need for data and b) labelled image generation procedures for microelectronics are costly, and labelled data is therefore sparse. Whereas in other domains, pre-training on large natural image datasets can mitigate this problem, in microelectronics transfer learning is hindered due to the dissimilarity of domain data and natural images. Therefore, we evaluate self pre-training, where models are pre-trained on the target dataset, rather than another dataset. We propose a vision transformer (ViT) pre-training framework for defect detection in microelectronics based on masked autoencoders (MAE). In MAE, a large share of image patches is masked and reconstructed by the model during pre-training. We perform pre-training and defect detection using a dataset of less than 10.000 scanning acoustic microscopy (SAM) images labelled using transient thermal analysis (TTA). Our experimental results show that our approach leads to substantial performance gains compared to a) supervised ViT, b) ViT pre-trained on natural image datasets, and c) state-of-the-art CNN-based defect detection models used in the literature. Additionally, interpretability analysis reveals that our self pre-trained models, in comparison to ViT baselines, correctly focus on defect-relevant features such as cracks in the solder material. This demonstrates that our approach yields fault-specific feature representations, making our self pre-trained models viable for real-world defect detection in microelectronics.
Conformal Prediction in Hierarchical Classification
Jan 31, 2025Conformal prediction has emerged as a widely used framework for constructing valid prediction sets in classification and regression tasks. In this work, we extend the split conformal prediction framework to hierarchical classification, where prediction sets are commonly restricted to internal nodes of a predefined hierarchy, and propose two computationally efficient inference algorithms. The first algorithm returns internal nodes as prediction sets, while the second relaxes this restriction, using the notion of representation complexity, yielding a more general and combinatorial inference problem, but smaller set sizes. Empirical evaluations on several benchmark datasets demonstrate the effectiveness of the proposed algorithms in achieving nominal coverage.
G3FA: Geometry-guided GAN for Face Animation
Aug 23, 2024



Animating human face images aims to synthesize a desired source identity in a natural-looking way mimicking a driving video's facial movements. In this context, Generative Adversarial Networks have demonstrated remarkable potential in real-time face reenactment using a single source image, yet are constrained by limited geometry consistency compared to graphic-based approaches. In this paper, we introduce Geometry-guided GAN for Face Animation (G3FA) to tackle this limitation. Our novel approach empowers the face animation model to incorporate 3D information using only 2D images, improving the image generation capabilities of the talking head synthesis model. We integrate inverse rendering techniques to extract 3D facial geometry properties, improving the feedback loop to the generator through a weighted average ensemble of discriminators. In our face reenactment model, we leverage 2D motion warping to capture motion dynamics along with orthogonal ray sampling and volume rendering techniques to produce the ultimate visual output. To evaluate the performance of our G3FA, we conducted comprehensive experiments using various evaluation protocols on VoxCeleb2 and TalkingHead benchmarks to demonstrate the effectiveness of our proposed framework compared to the state-of-the-art real-time face animation methods.
Learning Images Across Scales Using Adversarial Training
Jun 13, 2024



The real world exhibits rich structure and detail across many scales of observation. It is difficult, however, to capture and represent a broad spectrum of scales using ordinary images. We devise a novel paradigm for learning a representation that captures an orders-of-magnitude variety of scales from an unstructured collection of ordinary images. We treat this collection as a distribution of scale-space slices to be learned using adversarial training, and additionally enforce coherency across slices. Our approach relies on a multiscale generator with carefully injected procedural frequency content, which allows to interactively explore the emerging continuous scale space. Training across vastly different scales poses challenges regarding stability, which we tackle using a supervision scheme that involves careful sampling of scales. We show that our generator can be used as a multiscale generative model, and for reconstructions of scale spaces from unstructured patches. Significantly outperforming the state of the art, we demonstrate zoom-in factors of up to 256x at high quality and scale consistency.
Conformalized Credal Set Predictors
Feb 16, 2024Credal sets are sets of probability distributions that are considered as candidates for an imprecisely known ground-truth distribution. In machine learning, they have recently attracted attention as an appealing formalism for uncertainty representation, in particular due to their ability to represent both the aleatoric and epistemic uncertainty in a prediction. However, the design of methods for learning credal set predictors remains a challenging problem. In this paper, we make use of conformal prediction for this purpose. More specifically, we propose a method for predicting credal sets in the classification task, given training data labeled by probability distributions. Since our method inherits the coverage guarantees of conformal prediction, our conformal credal sets are guaranteed to be valid with high probability (without any assumptions on model or distribution). We demonstrate the applicability of our method to natural language inference, a highly ambiguous natural language task where it is common to obtain multiple annotations per example.
Conformal Prediction with Partially Labeled Data
Jun 01, 2023



While the predictions produced by conformal prediction are set-valued, the data used for training and calibration is supposed to be precise. In the setting of superset learning or learning from partial labels, a variant of weakly supervised learning, it is exactly the other way around: training data is possibly imprecise (set-valued), but the model induced from this data yields precise predictions. In this paper, we combine the two settings by making conformal prediction amenable to set-valued training data. We propose a generalization of the conformal prediction procedure that can be applied to set-valued training and calibration data. We prove the validity of the proposed method and present experimental studies in which it compares favorably to natural baselines.
Conformal Prediction Intervals for Remaining Useful Lifetime Estimation
Dec 30, 2022



The main objective of Prognostics and Health Management is to estimate the Remaining Useful Lifetime (RUL), namely, the time that a system or a piece of equipment is still in working order before starting to function incorrectly. In recent years, numerous machine learning algorithms have been proposed for RUL estimation, mainly focusing on providing more accurate RUL predictions. However, there are many sources of uncertainty in the problem, such as inherent randomness of systems failure, lack of knowledge regarding their future states, and inaccuracy of the underlying predictive models, making it infeasible to predict the RULs precisely. Hence, it is of utmost importance to quantify the uncertainty alongside the RUL predictions. In this work, we investigate the conformal prediction (CP) framework that represents uncertainty by predicting sets of possible values for the target variable (intervals in the case of RUL) instead of making point predictions. Under very mild technical assumptions, CP formally guarantees that the actual value (true RUL) is covered by the predicted set with a degree of certainty that can be prespecified. We study three CP algorithms to conformalize any single-point RUL predictor and turn it into a valid interval predictor. Finally, we conformalize two single-point RUL predictors, deep convolutional neural networks and gradient boosting, and illustrate their performance on the Commercial Modular Aero-Propulsion System Simulation (C-MAPSS) data sets.