 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsicEdit: Precise generative image manipulation in intrinsic space
May 15, 2025



Generative diffusion models have advanced image editing with high-quality results and intuitive interfaces such as prompts and semantic drawing. However, these interfaces lack precise control, and the associated methods typically specialize on a single editing task. We introduce a versatile, generative workflow that operates in an intrinsic-image latent space, enabling semantic, local manipulation with pixel precision for a range of editing operations. Building atop the RGB-X diffusion framework, we address key challenges of identity preservation and intrinsic-channel entanglement. By incorporating exact diffusion inversion and disentangled channel manipulation, we enable precise, efficient editing with automatic resolution of global illumination effects -- all without additional data collection or model fine-tuning. We demonstrate state-of-the-art performance across a variety of tasks on complex images, including color and texture adjustments, object insertion and removal, global relighting, and their combinations.
Learning Images Across Scales Using Adversarial Training
Jun 13, 2024



The real world exhibits rich structure and detail across many scales of observation. It is difficult, however, to capture and represent a broad spectrum of scales using ordinary images. We devise a novel paradigm for learning a representation that captures an orders-of-magnitude variety of scales from an unstructured collection of ordinary images. We treat this collection as a distribution of scale-space slices to be learned using adversarial training, and additionally enforce coherency across slices. Our approach relies on a multiscale generator with carefully injected procedural frequency content, which allows to interactively explore the emerging continuous scale space. Training across vastly different scales poses challenges regarding stability, which we tackle using a supervision scheme that involves careful sampling of scales. We show that our generator can be used as a multiscale generative model, and for reconstructions of scale spaces from unstructured patches. Significantly outperforming the state of the art, we demonstrate zoom-in factors of up to 256x at high quality and scale consistency.
Cinematic Gaussians: Real-Time HDR Radiance Fields with Depth of Field
Jun 11, 2024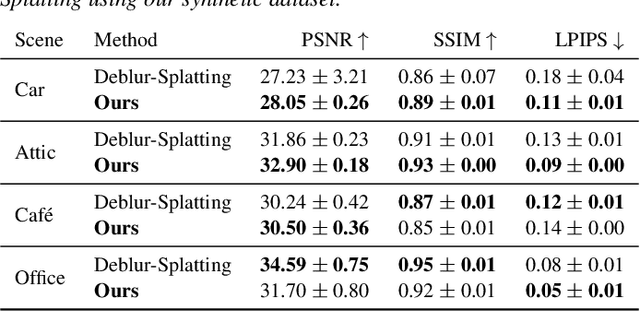

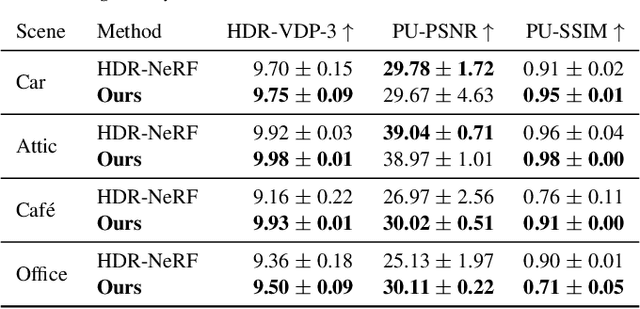

Radiance field methods represent the state of the art in reconstructing complex scenes from multi-view photos. However, these reconstructions often suffer from one or both of the following limitations: First, they typically represent scenes in low dynamic range (LDR), which restricts their use to evenly lit environments and hinders immersive viewing experiences. Secondly, their reliance on a pinhole camera model, assuming all scene elements are in focus in the input images, presents practical challenges and complicates refocusing during novel-view synthesis. Addressing these limitations, we present a lightweight method based on 3D Gaussian Splatting that utilizes multi-view LDR images of a scene with varying exposure times, apertures, and focus distances as input to reconstruct a high-dynamic-range (HDR) radiance field. By incorporating analytical convolutions of Gaussians based on a thin-lens camera model as well as a tonemapping module, our reconstructions enable the rendering of HDR content with flexible refocusing capabilities. We demonstrate that our combined treatment of HDR and depth of field facilitates real-time cinematic rendering, outperforming the state of the art.
Neural Gaussian Scale-Space Fields
May 31, 2024



Gaussian scale spaces are a cornerstone of signal representation and processing, with applications in filtering, multiscale analysis, anti-aliasing, and many more. However, obtaining such a scale space is costly and cumbersome, in particular for continuous representations such as neural fields. We present an efficient and lightweight method to learn the fully continuous, anisotropic Gaussian scale space of an arbitrary signal. Based on Fourier feature modulation and Lipschitz bounding, our approach is trained self-supervised, i.e., training does not require any manual filtering. Our neural Gaussian scale-space fields faithfully capture multiscale representations across a broad range of modalities, and support a diverse set of applications. These include images, geometry, light-stage data, texture anti-aliasing, and multiscale optimization.
Exposure Diffusion: HDR Image Generation by Consistent LDR denoising
May 23, 2024


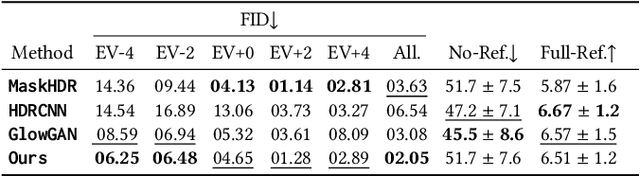
We demonstrate generating high-dynamic range (HDR) images using the concerted action of multiple black-box, pre-trained low-dynamic range (LDR) image diffusion models. Common diffusion models are not HDR as, first, there is no sufficiently large HDR image dataset available to re-train them, and second, even if it was, re-training such models is impossible for most compute budgets. Instead, we seek inspiration from the HDR image capture literature that traditionally fuses sets of LDR images, called "brackets", to produce a single HDR image. We operate multiple denoising processes to generate multiple LDR brackets that together form a valid HDR result. To this end, we introduce an exposure consistency term into the diffusion process to couple the brackets such that they agree across the exposure range they share. We demonstrate HDR versions of state-of-the-art unconditional and conditional as well as restoration-type (LDR2HDR) generative modeling.
Diffusion Posterior Illumination for Ambiguity-aware Inverse Rendering
Sep 30, 2023Inverse rendering, the process of inferring scene properties from images, is a challenging inverse problem. The task is ill-posed, as many different scene configurations can give rise to the same image. Most existing solutions incorporate priors into the inverse-rendering pipeline to encourage plausible solutions, but they do not consider the inherent ambiguities and the multi-modal distribution of possible decompositions. In this work, we propose a novel scheme that integrates a denoising diffusion probabilistic model pre-trained on natural illumination maps into an optimization framework involving a differentiable path tracer. The proposed method allows sampling from combinations of illumination and spatially-varying surface materials that are, both, natural and explain the image observations. We further conduct an extensive comparative study of different priors on illumination used in previous work on inverse rendering. Our method excels in recovering materials and producing highly realistic and diverse environment map samples that faithfully explain the illumination of the input images.
ROAM: Robust and Object-aware Motion Generation using Neural Pose Descriptors
Aug 24, 2023



Existing automatic approaches for 3D virtual character motion synthesis supporting scene interactions do not generalise well to new objects outside training distributions, even when trained on extensive motion capture datasets with diverse objects and annotated interactions. This paper addresses this limitation and shows that robustness and generalisation to novel scene objects in 3D object-aware character synthesis can be achieved by training a motion model with as few as one reference object. We leverage an implicit feature representation trained on object-only datasets, which encodes an SE(3)-equivariant descriptor field around the object. Given an unseen object and a reference pose-object pair, we optimise for the object-aware pose that is closest in the feature space to the reference pose. Finally, we use l-NSM, i.e., our motion generation model that is trained to seamlessly transition from locomotion to object interaction with the proposed bidirectional pose blending scheme. Through comprehensive numerical comparisons to state-of-the-art methods and in a user study, we demonstrate substantial improvements in 3D virtual character motion and interaction quality and robustness to scenarios with unseen objects. Our project page is available at https://vcai.mpi-inf.mpg.de/projects/ROAM/.
3D Gaussian Splatting for Real-Time Radiance Field Rendering
Aug 08, 2023



Radiance Field methods have recently revolutionized novel-view synthesis of scenes captured with multiple photos or videos. However, achieving high visual quality still requires neural networks that are costly to train and render, while recent faster methods inevitably trade off speed for quality. For unbounded and complete scenes (rather than isolated objects) and 1080p resolution rendering, no current method can achieve real-time display rates. We introduce three key elements that allow us to achieve state-of-the-art visual quality while maintaining competitive training times and importantly allow high-quality real-time (>= 30 fps) novel-view synthesis at 1080p resolution. First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene; Third, we develop a fast visibility-aware rendering algorithm that supports anisotropic splatting and both accelerates training and allows realtime rendering. We demonstrate state-of-the-art visual quality and real-time rendering on several established datasets.
* https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
May 18, 2023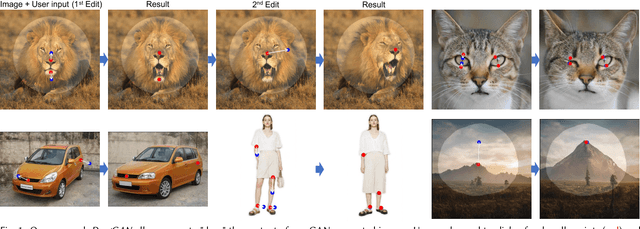
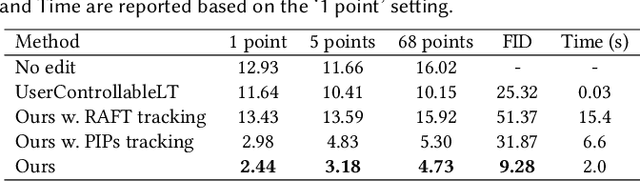
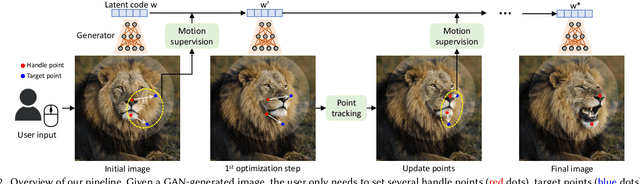
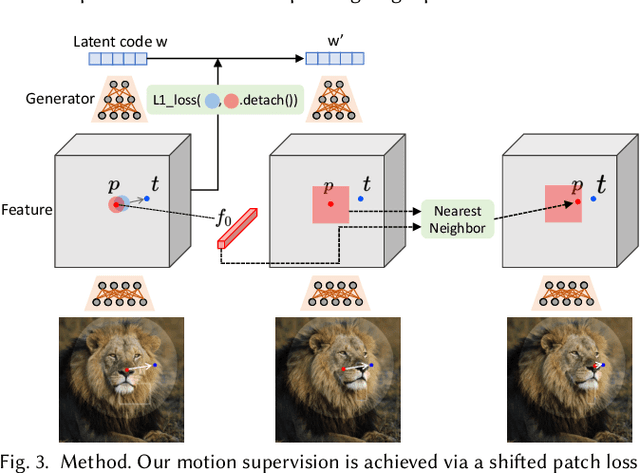
Synthesizing visual content that meets users' needs often requires flexible and precise controllability of the pose, shape, expression, and layout of the generated objects. Existing approaches gain controllability of generative adversarial networks (GANs) via manually annotated training data or a prior 3D model, which often lack flexibility, precision, and generality. In this work, we study a powerful yet much less explored way of controlling GANs, that is, to "drag" any points of the image to precisely reach target points in a user-interactive manner, as shown in Fig.1. To achieve this, we propose DragGAN, which consists of two main components: 1) a feature-based motion supervision that drives the handle point to move towards the target position, and 2) a new point tracking approach that leverages the discriminative generator features to keep localizing the position of the handle points. Through DragGAN, anyone can deform an image with precise control over where pixels go, thus manipulating the pose, shape, expression, and layout of diverse categories such as animals, cars, humans, landscapes, etc. As these manipulations are performed on the learned generative image manifold of a GAN, they tend to produce realistic outputs even for challenging scenarios such as hallucinating occluded content and deforming shapes that consistently follow the object's rigidity. Both qualitative and quantitative comparisons demonstrate the advantage of DragGAN over prior approaches in the tasks of image manipulation and point tracking. We also showcase the manipulation of real images through GAN inversion.
Neural Field Convolutions by Repeated Differentiation
Apr 04, 2023



Neural fields are evolving towards a general-purpose continuous representation for visual computing. Yet, despite their numerous appealing properties, they are hardly amenable to signal processing. As a remedy, we present a method to perform general continuous convolutions with general continuous signals such as neural fields. Observing that piecewise polynomial kernels reduce to a sparse set of Dirac deltas after repeated differentiation, we leverage convolution identities and train a repeated integral field to efficiently execute large-scale convolutions. We demonstrate our approach on a variety of data modalities and spatially-varying kernels.