 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-Aware Gloss Control for Generative Non-Photorealistic Rendering
Feb 19, 2026Humans can infer material characteristics of objects from their visual appearance, and this ability extends to artistic depictions, where similar perceptual strategies guide the interpretation of paintings or drawings. Among the factors that define material appearance, gloss, along with color, is widely regarded as one of the most important, and recent studies indicate that humans can perceive gloss independently of the artistic style used to depict an object. To investigate how gloss and artistic style are represented in learned models, we train an unsupervised generative model on a newly curated dataset of painterly objects designed to systematically vary such factors. Our analysis reveals a hierarchical latent space in which gloss is disentangled from other appearance factors, allowing for a detailed study of how gloss is represented and varies across artistic styles. Building on this representation, we introduce a lightweight adapter that connects our style- and gloss-aware latent space to a latent-diffusion model, enabling the synthesis of non-photorealistic images with fine-grained control of these factors. We compare our approach with previous models and observe improved disentanglement and controllability of the learned factors.
Cinematic Gaussians: Real-Time HDR Radiance Fields with Depth of Field
Jun 11, 2024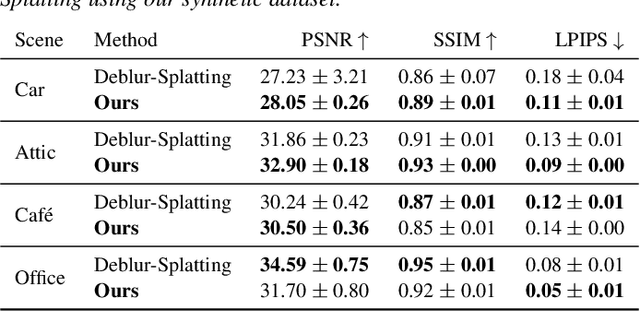

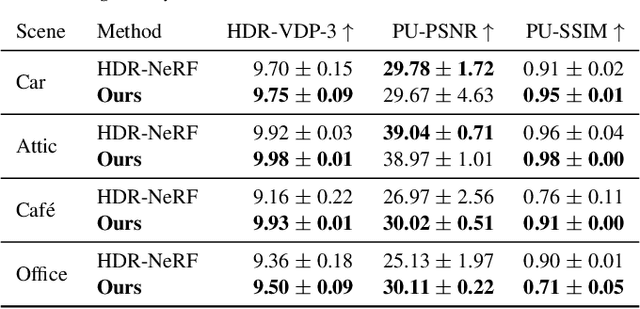

Radiance field methods represent the state of the art in reconstructing complex scenes from multi-view photos. However, these reconstructions often suffer from one or both of the following limitations: First, they typically represent scenes in low dynamic range (LDR), which restricts their use to evenly lit environments and hinders immersive viewing experiences. Secondly, their reliance on a pinhole camera model, assuming all scene elements are in focus in the input images, presents practical challenges and complicates refocusing during novel-view synthesis. Addressing these limitations, we present a lightweight method based on 3D Gaussian Splatting that utilizes multi-view LDR images of a scene with varying exposure times, apertures, and focus distances as input to reconstruct a high-dynamic-range (HDR) radiance field. By incorporating analytical convolutions of Gaussians based on a thin-lens camera model as well as a tonemapping module, our reconstructions enable the rendering of HDR content with flexible refocusing capabilities. We demonstrate that our combined treatment of HDR and depth of field facilitates real-time cinematic rendering, outperforming the state of the art.
Predicting Perceived Gloss: Do Weak Labels Suffice?
Mar 26, 2024Estimating perceptual attributes of materials directly from images is a challenging task due to their complex, not fully-understood interactions with external factors, such as geometry and lighting. Supervised deep learning models have recently been shown to outperform traditional approaches, but rely on large datasets of human-annotated images for accurate perception predictions. Obtaining reliable annotations is a costly endeavor, aggravated by the limited ability of these models to generalise to different aspects of appearance. In this work, we show how a much smaller set of human annotations ("strong labels") can be effectively augmented with automatically derived "weak labels" in the context of learning a low-dimensional image-computable gloss metric. We evaluate three alternative weak labels for predicting human gloss perception from limited annotated data. Incorporating weak labels enhances our gloss prediction beyond the current state of the art. Moreover, it enables a substantial reduction in human annotation costs without sacrificing accuracy, whether working with rendered images or real photographs.
GlowGAN: Unsupervised Learning of HDR Images from LDR Images in the Wild
Nov 23, 2022



Most in-the-wild images are stored in Low Dynamic Range (LDR) form, serving as a partial observation of the High Dynamic Range (HDR) visual world. Despite limited dynamic range, these LDR images are often captured with different exposures, implicitly containing information about the underlying HDR image distribution. Inspired by this intuition, in this work we present, to the best of our knowledge, the first method for learning a generative model of HDR images from in-the-wild LDR image collections in a fully unsupervised manner. The key idea is to train a generative adversarial network (GAN) to generate HDR images which, when projected to LDR under various exposures, are indistinguishable from real LDR images. The projection from HDR to LDR is achieved via a camera model that captures the stochasticity in exposure and camera response function. Experiments show that our method GlowGAN can synthesize photorealistic HDR images in many challenging cases such as landscapes, lightning, or windows, where previous supervised generative models produce overexposed images. We further demonstrate the new application of unsupervised inverse tone mapping (ITM) enabled by GlowGAN. Our ITM method does not need HDR images or paired multi-exposure images for training, yet it reconstructs more plausible information for overexposed regions than state-of-the-art supervised learning models trained on such data.
Learning a self-supervised tone mapping operator via feature contrast masking loss
Oct 19, 2021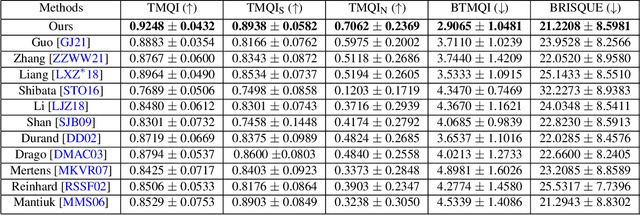
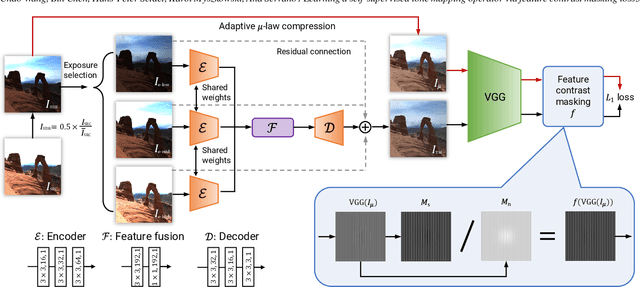

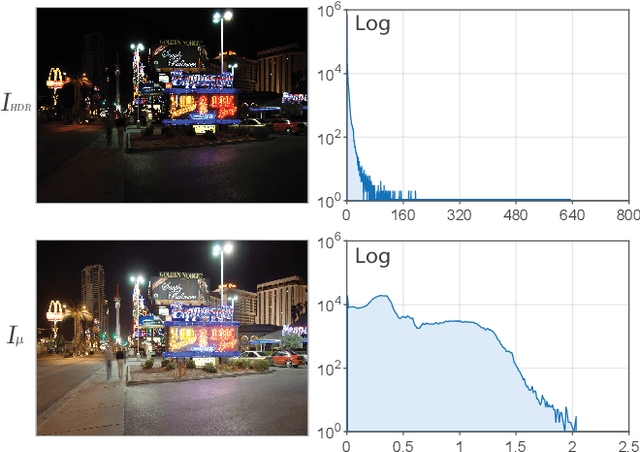
High Dynamic Range (HDR) content is becoming ubiquitous due to the rapid development of capture technologies. Nevertheless, the dynamic range of common display devices is still limited, therefore tone mapping (TM) remains a key challenge for image visualization. Recent work has demonstrated that neural networks can achieve remarkable performance in this task when compared to traditional methods, however, the quality of the results of these learning-based methods is limited by the training data. Most existing works use as training set a curated selection of best-performing results from existing traditional tone mapping operators (often guided by a quality metric), therefore, the quality of newly generated results is fundamentally limited by the performance of such operators. This quality might be even further limited by the pool of HDR content that is used for training. In this work we propose a learning-based self-supervised tone mapping operator that is trained at test time specifically for each HDR image and does not need any data labeling. The key novelty of our approach is a carefully designed loss function built upon fundamental knowledge on contrast perception that allows for directly comparing the content in the HDR and tone mapped images. We achieve this goal by reformulating classic VGG feature maps into feature contrast maps that normalize local feature differences by their average magnitude in a local neighborhood, allowing our loss to account for contrast masking effects. We perform extensive ablation studies and exploration of parameters and demonstrate that our solution outperforms existing approaches with a single set of fixed parameters, as confirmed by both objective and subjective metrics.
ScanGAN360: A Generative Model of Realistic Scanpaths for 360$^{\circ}$ Images
Mar 25, 2021
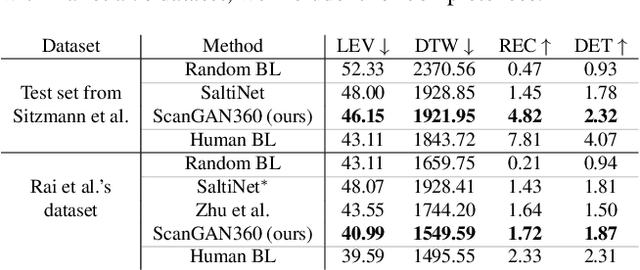
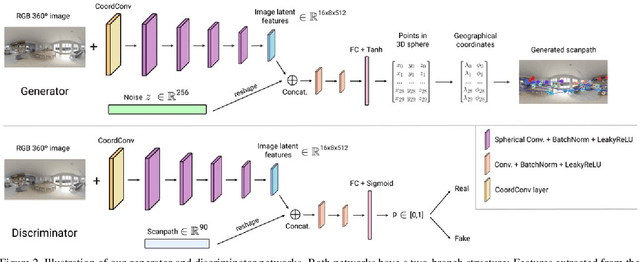
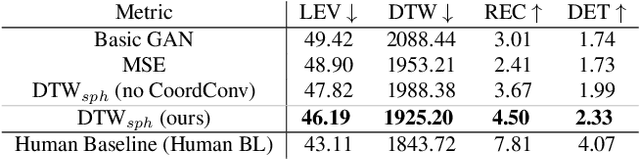
Understanding and modeling the dynamics of human gaze behavior in 360$^\circ$ environments is a key challenge in computer vision and virtual reality. Generative adversarial approaches could alleviate this challenge by generating a large number of possible scanpaths for unseen images. Existing methods for scanpath generation, however, do not adequately predict realistic scanpaths for 360$^\circ$ images. We present ScanGAN360, a new generative adversarial approach to address this challenging problem. Our network generator is tailored to the specifics of 360$^\circ$ images representing immersive environments. Specifically, we accomplish this by leveraging the use of a spherical adaptation of dynamic-time warping as a loss function and proposing a novel parameterization of 360$^\circ$ scanpaths. The quality of our scanpaths outperforms competing approaches by a large margin and is almost on par with the human baseline. ScanGAN360 thus allows fast simulation of large numbers of virtual observers, whose behavior mimics real users, enabling a better understanding of gaze behavior and novel applications in virtual scene design.
The joint role of geometry and illumination on material recognition
Feb 04, 2021



Observing and recognizing materials is a fundamental part of our daily life. Under typical viewing conditions, we are capable of effortlessly identifying the objects that surround us and recognizing the materials they are made of. Nevertheless, understanding the underlying perceptual processes that take place to accurately discern the visual properties of an object is a long-standing problem. In this work, we perform a comprehensive and systematic analysis of how the interplay of geometry, illumination, and their spatial frequencies affects human performance on material recognition tasks. We carry out large-scale behavioral experiments where participants are asked to recognize different reference materials among a pool of candidate samples. In the different experiments, we carefully sample the information in the frequency domain of the stimuli. From our analysis, we find significant first-order interactions between the geometry and the illumination, of both the reference and the candidates. In addition, we observe that simple image statistics and higher-order image histograms do not correlate with human performance. Therefore, we perform a high-level comparison of highly non-linear statistics by training a deep neural network on material recognition tasks. Our results show that such models can accurately classify materials, which suggests that they are capable of defining a meaningful representation of material appearance from labeled proximal image data. Last, we find preliminary evidence that these highly non-linear models and humans may use similar high-level factors for material recognition tasks.
* 15 pages, 16 figures, Accepted to the Journal of Vision, 2021
A Similarity Measure for Material Appearance
May 04, 2019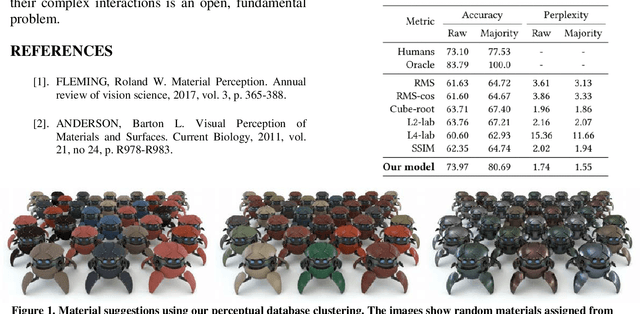
We present a model to measure the similarity in appearance between different materials, which correlates with human similarity judgments. We first create a database of 9,000 rendered images depicting objects with varying materials, shape and illumination. We then gather data on perceived similarity from crowdsourced experiments; our analysis of over 114,840 answers suggests that indeed a shared perception of appearance similarity exists. We feed this data to a deep learning architecture with a novel loss function, which learns a feature space for materials that correlates with such perceived appearance similarity. Our evaluation shows that our model outperforms existing metrics. Last, we demonstrate several applications enabled by our metric, including appearance-based search for material suggestions, database visualization, clustering and summarization, and gamut mapping.
* 12 pages, 17 figures
Convolutional Sparse Coding for High Dynamic Range Imaging
Jun 13, 2018
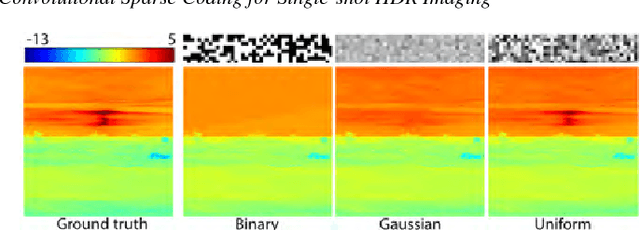


Current HDR acquisition techniques are based on either (i) fusing multibracketed, low dynamic range (LDR) images, (ii) modifying existing hardware and capturing different exposures simultaneously with multiple sensors, or (iii) reconstructing a single image with spatially-varying pixel exposures. In this paper, we propose a novel algorithm to recover high-quality HDRI images from a single, coded exposure. The proposed reconstruction method builds on recently-introduced ideas of convolutional sparse coding (CSC); this paper demonstrates how to make CSC practical for HDR imaging. We demonstrate that the proposed algorithm achieves higher-quality reconstructions than alternative methods, we evaluate optical coding schemes, analyze algorithmic parameters, and build a prototype coded HDR camera that demonstrates the utility of convolutional sparse HDRI coding with a custom hardware platform.
Convolutional sparse coding for capturing high speed video content
Jun 13, 2018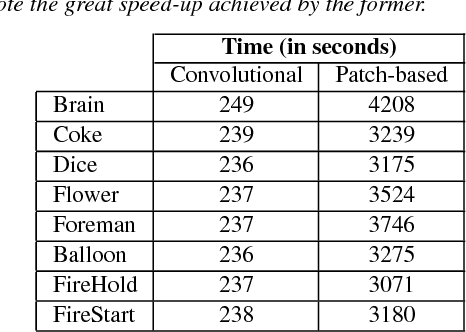
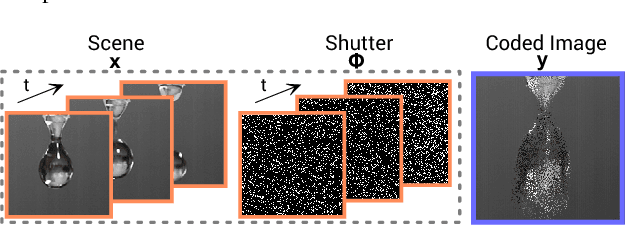


Video capture is limited by the trade-off between spatial and temporal resolution: when capturing videos of high temporal resolution, the spatial resolution decreases due to bandwidth limitations in the capture system. Achieving both high spatial and temporal resolution is only possible with highly specialized and very expensive hardware, and even then the same basic trade-off remains. The recent introduction of compressive sensing and sparse reconstruction techniques allows for the capture of single-shot high-speed video, by coding the temporal information in a single frame, and then reconstructing the full video sequence from this single coded image and a trained dictionary of image patches. In this paper, we first analyze this approach, and find insights that help improve the quality of the reconstructed videos. We then introduce a novel technique, based on convolutional sparse coding (CSC), and show how it outperforms the state-of-the-art, patch-based approach in terms of flexibility and efficiency, due to the convolutional nature of its filter banks. The key idea for CSC high-speed video acquisition is extending the basic formulation by imposing an additional constraint in the temporal dimension, which enforces sparsity of the first-order derivatives over time.