 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLotus: Creating Short Videos From Long Videos With Abstractive and Extractive Summarization
Feb 10, 2025Short-form videos are popular on platforms like TikTok and Instagram as they quickly capture viewers' attention. Many creators repurpose their long-form videos to produce short-form videos, but creators report that planning, extracting, and arranging clips from long-form videos is challenging. Currently, creators make extractive short-form videos composed of existing long-form video clips or abstractive short-form videos by adding newly recorded narration to visuals. While extractive videos maintain the original connection between audio and visuals, abstractive videos offer flexibility in selecting content to be included in a shorter time. We present Lotus, a system that combines both approaches to balance preserving the original content with flexibility over the content. Lotus first creates an abstractive short-form video by generating both a short-form script and its corresponding speech, then matching long-form video clips to the generated narration. Creators can then add extractive clips with an automated method or Lotus's editing interface. Lotus's interface can be used to further refine the short-form video. We compare short-form videos generated by Lotus with those using an extractive baseline method. In our user study, we compare creating short-form videos using Lotus to participants' existing practice.
Long-Form Answers to Visual Questions from Blind and Low Vision People
Aug 12, 2024



Vision language models can now generate long-form answers to questions about images - long-form visual question answers (LFVQA). We contribute VizWiz-LF, a dataset of long-form answers to visual questions posed by blind and low vision (BLV) users. VizWiz-LF contains 4.2k long-form answers to 600 visual questions, collected from human expert describers and six VQA models. We develop and annotate functional roles of sentences of LFVQA and demonstrate that long-form answers contain information beyond the question answer such as explanations and suggestions. We further conduct automatic and human evaluations with BLV and sighted people to evaluate long-form answers. BLV people perceive both human-written and generated long-form answers to be plausible, but generated answers often hallucinate incorrect visual details, especially for unanswerable visual questions (e.g., blurry or irrelevant images). To reduce hallucinations, we evaluate the ability of VQA models to abstain from answering unanswerable questions across multiple prompting strategies.
Controlling Dialogue Generation with Semantic Exemplars
Aug 20, 2020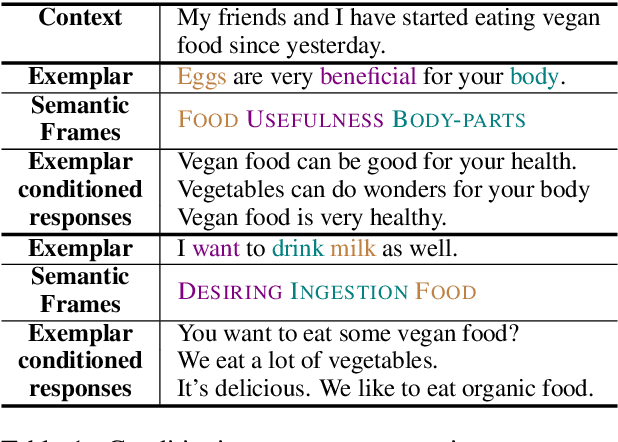
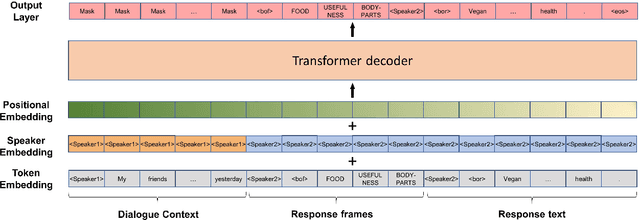
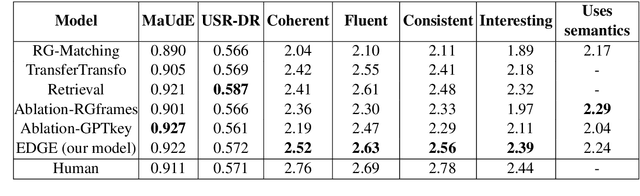
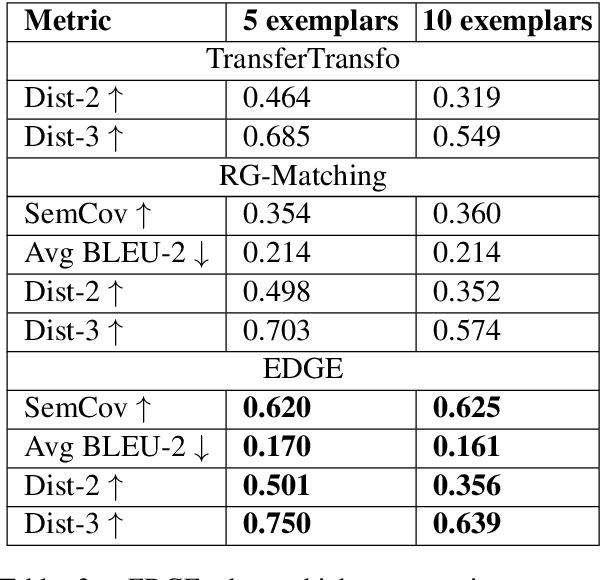
Dialogue systems pretrained with large language models generate locally coherent responses, but lack the fine-grained control over responses necessary to achieve specific goals. A promising method to control response generation is exemplar-based generation, in which models edit exemplar responses that are retrieved from training data, or hand-written to strategically address discourse-level goals, to fit new dialogue contexts. But, current exemplar-based approaches often excessively copy words from the exemplar responses, leading to incoherent replies. We present an Exemplar-based Dialogue Generation model, EDGE, that uses the semantic frames present in exemplar responses to guide generation. We show that controlling dialogue generation based on the semantic frames of exemplars, rather than words in the exemplar itself, improves the coherence of generated responses, while preserving semantic meaning and conversation goals present in exemplar responses.
Extracting Structured Data from Physician-Patient Conversations By Predicting Noteworthy Utterances
Jul 14, 2020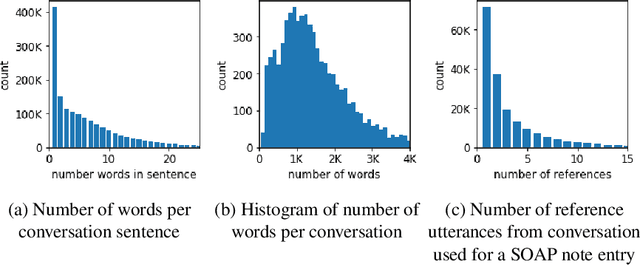
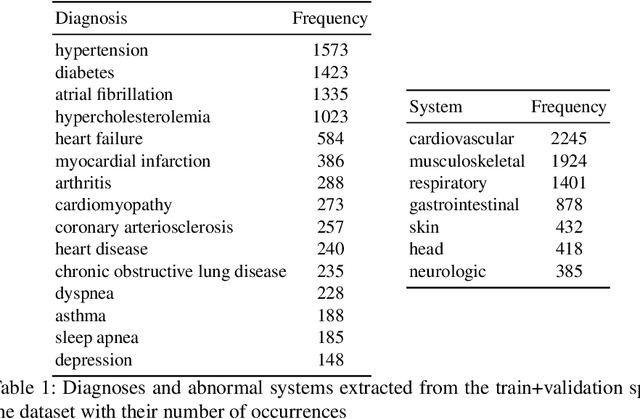
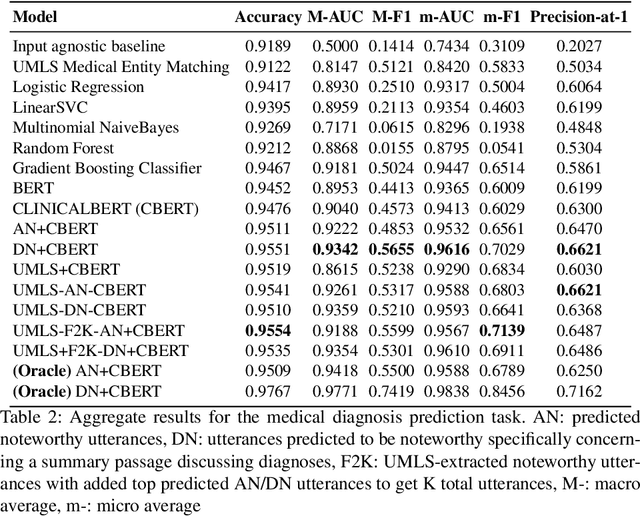
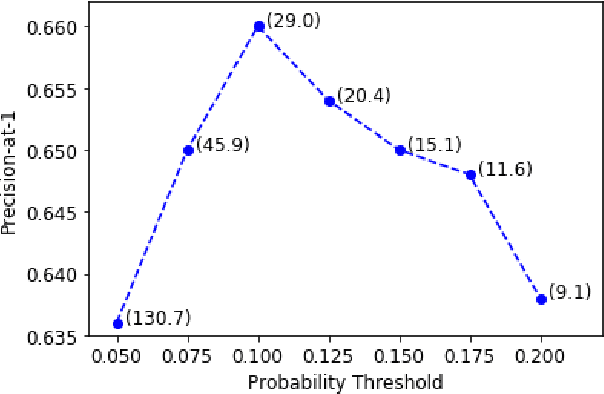
Despite diverse efforts to mine various modalities of medical data, the conversations between physicians and patients at the time of care remain an untapped source of insights. In this paper, we leverage this data to extract structured information that might assist physicians with post-visit documentation in electronic health records, potentially lightening the clerical burden. In this exploratory study, we describe a new dataset consisting of conversation transcripts, post-visit summaries, corresponding supporting evidence (in the transcript), and structured labels. We focus on the tasks of recognizing relevant diagnoses and abnormalities in the review of organ systems (RoS). One methodological challenge is that the conversations are long (around 1500 words), making it difficult for modern deep-learning models to use them as input. To address this challenge, we extract noteworthy utterances---parts of the conversation likely to be cited as evidence supporting some summary sentence. We find that by first filtering for (predicted) noteworthy utterances, we can significantly boost predictive performance for recognizing both diagnoses and RoS abnormalities.
Investigating Evaluation of Open-Domain Dialogue Systems With Human Generated Multiple References
Sep 08, 2019
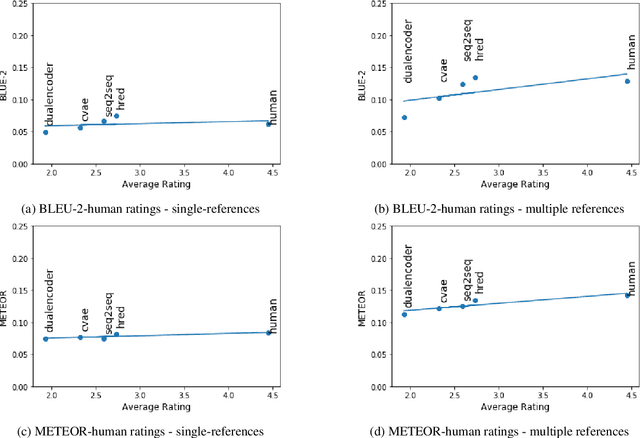
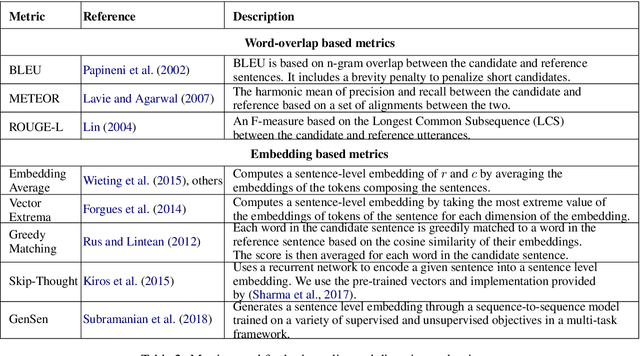
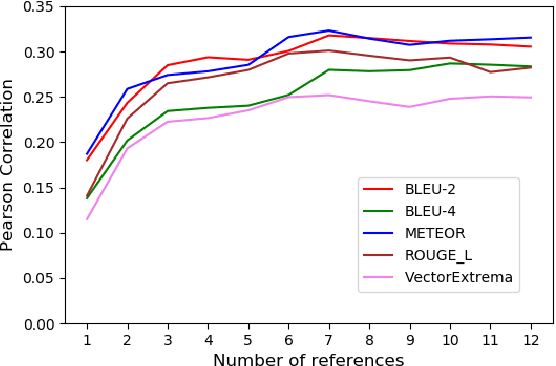
The aim of this paper is to mitigate the shortcomings of automatic evaluation of open-domain dialog systems through multi-reference evaluation. Existing metrics have been shown to correlate poorly with human judgement, particularly in open-domain dialog. One alternative is to collect human annotations for evaluation, which can be expensive and time consuming. To demonstrate the effectiveness of multi-reference evaluation, we augment the test set of DailyDialog with multiple references. A series of experiments show that the use of multiple references results in improved correlation between several automatic metrics and human judgement for both the quality and the diversity of system output.
How do people explore virtual environments?
Sep 19, 2017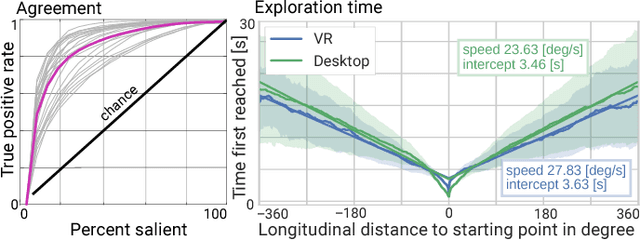



Understanding how people explore immersive virtual environments is crucial for many applications, such as designing virtual reality (VR) content, developing new compression algorithms, or learning computational models of saliency or visual attention. Whereas a body of recent work has focused on modeling saliency in desktop viewing conditions, VR is very different from these conditions in that viewing behavior is governed by stereoscopic vision and by the complex interaction of head orientation, gaze, and other kinematic constraints. To further our understanding of viewing behavior and saliency in VR, we capture and analyze gaze and head orientation data of 169 users exploring stereoscopic, static omni-directional panoramas, for a total of 1980 head and gaze trajectories for three different viewing conditions. We provide a thorough analysis of our data, which leads to several important insights, such as the existence of a particular fixation bias, which we then use to adapt existing saliency predictors to immersive VR conditions. In addition, we explore other applications of our data and analysis, including automatic alignment of VR video cuts, panorama thumbnails, panorama video synopsis, and saliency-based compression.