 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
Mar 12, 2026Multimodal Large Language Models (MLLMs) are increasingly used to carry out visual workflows such as navigating GUIs, where the next step depends on verified visual compositional conditions (e.g., "if a permission dialog appears and the color of the interface is green, click Allow") and the process may branch or terminate early. Yet this capability remains under-evaluated: existing benchmarks focus on shallow-compositions or independent-constraints rather than deeply chained compositional conditionals. In this paper, we introduce MM-CondChain, a benchmark for visually grounded deep compositional reasoning. Each benchmark instance is organized as a multi-layer reasoning chain, where every layer contains a non-trivial compositional condition grounded in visual evidence and built from multiple objects, attributes, or relations. To answer correctly, an MLLM must perceive the image in detail, reason over multiple visual elements at each step, and follow the resulting execution path to the final outcome. To scalably construct such workflow-style data, we propose an agentic synthesis pipeline: a Planner orchestrates layer-by-layer generation of compositional conditions, while a Verifiable Programmatic Intermediate Representation (VPIR) ensures each layer's condition is mechanically verifiable. A Composer then assembles these verified layers into complete instructions. Using this pipeline, we construct benchmarks across three visual domains: natural images, data charts, and GUI trajectories. Experiments on a range of MLLMs show that even the strongest model attains only 53.33 Path F1, with sharp drops on hard negatives and as depth or predicate complexity grows, confirming that deep compositional reasoning remains a fundamental challenge.
Geo-R1: Improving Few-Shot Geospatial Referring Expression Understanding with Reinforcement Fine-Tuning
Sep 26, 2025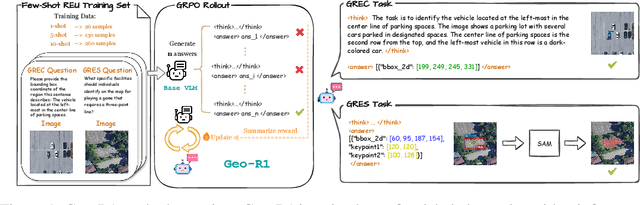


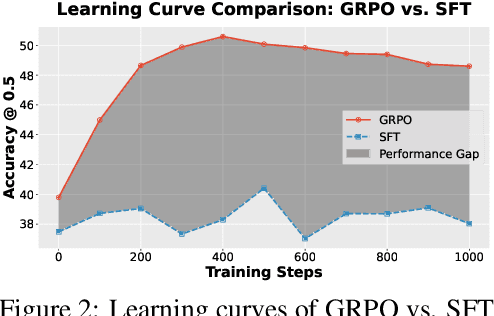
Referring expression understanding in remote sensing poses unique challenges, as it requires reasoning over complex object-context relationships. While supervised fine-tuning (SFT) on multimodal large language models achieves strong performance with massive labeled datasets, they struggle in data-scarce scenarios, leading to poor generalization. To address this limitation, we propose Geo-R1, a reasoning-centric reinforcement fine-tuning (RFT) paradigm for few-shot geospatial referring. Geo-R1 enforces the model to first generate explicit, interpretable reasoning chains that decompose referring expressions, and then leverage these rationales to localize target objects. This "reason first, then act" process enables the model to make more effective use of limited annotations, enhances generalization, and provides interpretability. We validate Geo-R1 on three carefully designed few-shot geospatial referring benchmarks, where our model consistently and substantially outperforms SFT baselines. It also demonstrates strong cross-dataset generalization, highlighting its robustness. Code and data will be released at http://geo-r1.github.io.
Unifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research
May 30, 2025


Language agents powered by large language models (LLMs) have demonstrated remarkable capabilities in understanding, reasoning, and executing complex tasks. However, developing robust agents presents significant challenges: substantial engineering overhead, lack of standardized components, and insufficient evaluation frameworks for fair comparison. We introduce Agent Graph-based Orchestration for Reasoning and Assessment (AGORA), a flexible and extensible framework that addresses these challenges through three key contributions: (1) a modular architecture with a graph-based workflow engine, efficient memory management, and clean component abstraction; (2) a comprehensive suite of reusable agent algorithms implementing state-of-the-art reasoning approaches; and (3) a rigorous evaluation framework enabling systematic comparison across multiple dimensions. Through extensive experiments on mathematical reasoning and multimodal tasks, we evaluate various agent algorithms across different LLMs, revealing important insights about their relative strengths and applicability. Our results demonstrate that while sophisticated reasoning approaches can enhance agent capabilities, simpler methods like Chain-of-Thought often exhibit robust performance with significantly lower computational overhead. AGORA not only simplifies language agent development but also establishes a foundation for reproducible agent research through standardized evaluation protocols.
OSVBench: Benchmarking LLMs on Specification Generation Tasks for Operating System Verification
Apr 29, 2025



We introduce OSVBench, a new benchmark for evaluating Large Language Models (LLMs) in generating complete specification code pertaining to operating system kernel verification tasks. The benchmark first defines the specification generation problem into a program synthesis problem within a confined scope of syntax and semantics by providing LLMs with the programming model. The LLMs are required to understand the provided verification assumption and the potential syntax and semantics space to search for, then generate the complete specification for the potentially buggy operating system code implementation under the guidance of the high-level functional description of the operating system. This benchmark is built upon a real-world operating system kernel, Hyperkernel, and consists of 245 complex specification generation tasks in total, each is a long context task of about 20k-30k tokens. Our comprehensive evaluation of 12 LLMs exhibits the limited performance of the current LLMs on the specification generation tasks for operating system verification. Significant disparities in their performance on the benchmark highlight differences in their ability to handle long-context code generation tasks. The evaluation toolkit and benchmark are available at https://github.com/lishangyu-hkust/OSVBench.
SRMF: A Data Augmentation and Multimodal Fusion Approach for Long-Tail UHR Satellite Image Segmentation
Apr 28, 2025The long-tail problem presents a significant challenge to the advancement of semantic segmentation in ultra-high-resolution (UHR) satellite imagery. While previous efforts in UHR semantic segmentation have largely focused on multi-branch network architectures that emphasize multi-scale feature extraction and fusion, they have often overlooked the importance of addressing the long-tail issue. In contrast to prior UHR methods that focused on independent feature extraction, we emphasize data augmentation and multimodal feature fusion to alleviate the long-tail problem. In this paper, we introduce SRMF, a novel framework for semantic segmentation in UHR satellite imagery. Our approach addresses the long-tail class distribution by incorporating a multi-scale cropping technique alongside a data augmentation strategy based on semantic reordering and resampling. To further enhance model performance, we propose a multimodal fusion-based general representation knowledge injection method, which, for the first time, fuses text and visual features without the need for individual region text descriptions, extracting more robust features. Extensive experiments on the URUR, GID, and FBP datasets demonstrate that our method improves mIoU by 3.33\%, 0.66\%, and 0.98\%, respectively, achieving state-of-the-art performance. Code is available at: https://github.com/BinSpa/SRMF.git.
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Apr 10, 2025
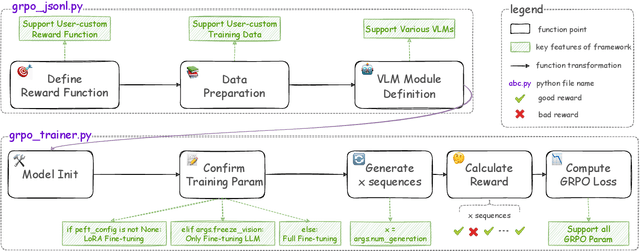
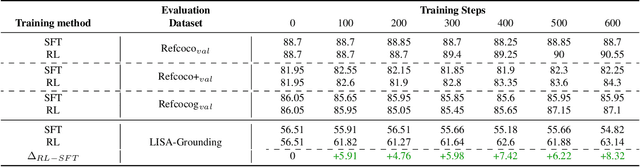
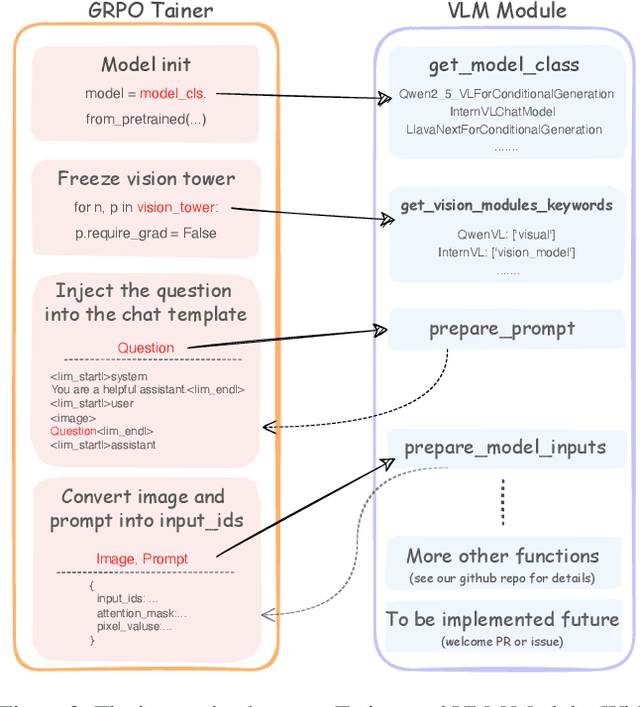
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs' performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the "OD aha moment", the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
GeoRSMLLM: A Multimodal Large Language Model for Vision-Language Tasks in Geoscience and Remote Sensing
Mar 16, 2025The application of Vision-Language Models (VLMs) in remote sensing (RS) has demonstrated significant potential in traditional tasks such as scene classification, object detection, and image captioning. However, current models, which excel in Referring Expression Comprehension (REC), struggle with tasks involving complex instructions (e.g., exists multiple conditions) or pixel-level operations like segmentation and change detection. In this white paper, we provide a comprehensive hierarchical summary of vision-language tasks in RS, categorized by the varying levels of cognitive capability required. We introduce the Remote Sensing Vision-Language Task Set (RSVLTS), which includes Open-Vocabulary Tasks (OVT), Referring Expression Tasks (RET), and Described Object Tasks (DOT) with increased difficulty, and Visual Question Answering (VQA) aloneside. Moreover, we propose a novel unified data representation using a set-of-points approach for RSVLTS, along with a condition parser and a self-augmentation strategy based on cyclic referring. These features are integrated into the GeoRSMLLM model, and this enhanced model is designed to handle a broad range of tasks of RSVLTS, paving the way for a more generalized solution for vision-language tasks in geoscience and remote sensing.
The Self-Improvement Paradox: Can Language Models Bootstrap Reasoning Capabilities without External Scaffolding?
Feb 19, 2025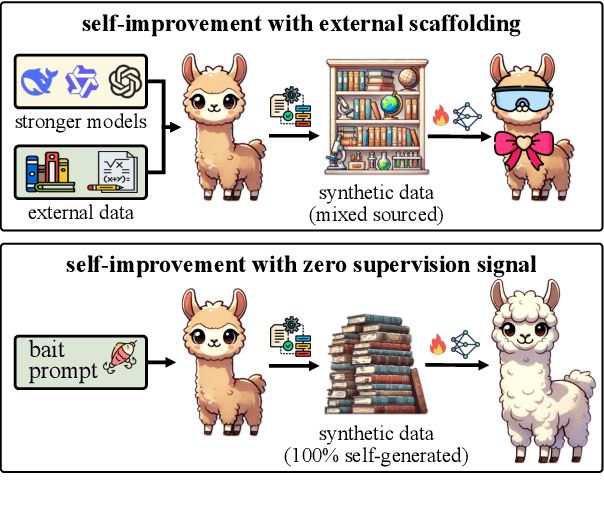
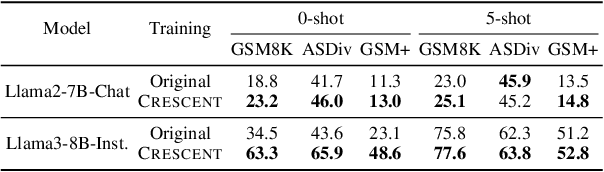
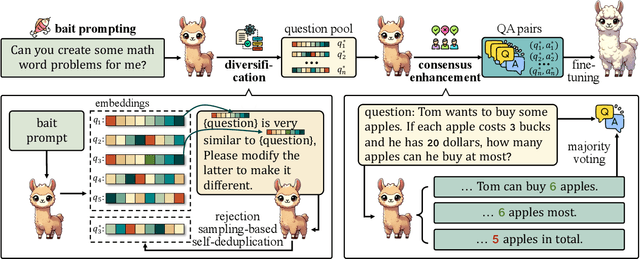
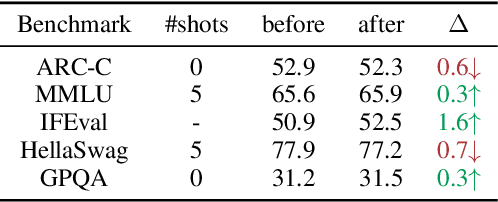
Self-improving large language models (LLMs) -- i.e., to improve the performance of an LLM by fine-tuning it with synthetic data generated by itself -- is a promising way to advance the capabilities of LLMs while avoiding extensive supervision. Existing approaches to self-improvement often rely on external supervision signals in the form of seed data and/or assistance from third-party models. This paper presents Crescent -- a simple yet effective framework for generating high-quality synthetic question-answer data in a fully autonomous manner. Crescent first elicits the LLM to generate raw questions via a bait prompt, then diversifies these questions leveraging a rejection sampling-based self-deduplication, and finally feeds the questions to the LLM and collects the corresponding answers by means of majority voting. We show that Crescent sheds light on the potential of true self-improvement with zero external supervision signals for math reasoning; in particular, Crescent-generated question-answer pairs suffice to (i) improve the reasoning capabilities of an LLM while preserving its general performance (especially in the 0-shot setting); and (ii) distil LLM knowledge to weaker models more effectively than existing methods based on seed-dataset augmentation.
GUI Testing Arena: A Unified Benchmark for Advancing Autonomous GUI Testing Agent
Dec 24, 2024



Nowadays, research on GUI agents is a hot topic in the AI community. However, current research focuses on GUI task automation, limiting the scope of applications in various GUI scenarios. In this paper, we propose a formalized and comprehensive environment to evaluate the entire process of automated GUI Testing (GTArena), offering a fair, standardized environment for consistent operation of diverse multimodal large language models. We divide the testing process into three key subtasks: test intention generation, test task execution, and GUI defect detection, and construct a benchmark dataset based on these to conduct a comprehensive evaluation. It evaluates the performance of different models using three data types: real mobile applications, mobile applications with artificially injected defects, and synthetic data, thoroughly assessing their capabilities in this relevant task. Additionally, we propose a method that helps researchers explore the correlation between the performance of multimodal language large models in specific scenarios and their general capabilities in standard benchmark tests. Experimental results indicate that even the most advanced models struggle to perform well across all sub-tasks of automated GUI Testing, highlighting a significant gap between the current capabilities of Autonomous GUI Testing and its practical, real-world applicability. This gap provides guidance for the future direction of GUI Agent development. Our code is available at https://github.com/ZJU-ACES-ISE/ChatUITest.
Evaluating and Enhancing LLMs for Multi-turn Text-to-SQL with Multiple Question Types
Dec 21, 2024Recent advancements in large language models (LLMs) have significantly advanced text-to-SQL systems. However, most LLM-based methods often narrowly focus on SQL generation, neglecting the complexities of real-world conversational queries. This oversight can lead to unreliable responses, particularly for ambiguous questions that cannot be directly addressed with SQL. To bridge this gap, we propose MMSQL, a comprehensive test suite designed to evaluate the question classification and SQL generation capabilities of LLMs by simulating real-world scenarios with diverse question types and multi-turn Q\&A interactions. Using MMSQL, we assessed the performance of popular LLMs, including both open-source and closed-source models, and identified key factors impacting their performance in such scenarios. Moreover, we introduce an LLM-based multi-agent framework that employs specialized agents to identify question types and determine appropriate answering strategies. Our experiments demonstrate that this approach significantly enhances the model's ability to navigate the complexities of conversational dynamics, effectively handling the diverse and complex nature of user queries.