 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Pretraining Paradigm Better Serves Spatial Intelligence? An Empirical Comparison of Vision-Language and Video Generation Models
May 27, 2026Spatial intelligence requires visual representations that capture both semantic objects and geometric structure in the physical world. To support this, two major pre-training schemes are now widely used as foundation backbones: Vision-Language Models (VLMs), which use language supervision to align visual observations with semantic concepts, and Video Generation Models (VGMs), which learn from temporally evolving visual worlds. However, it still remains unclear which pre-training scheme provides a better representation substrate for spatial intelligence. In this paper, we present the first systematic frozen-feature probing study of VLMs and VGMs across three representative axes of spatial intelligence: semantic tagging, instance grouping, and 3D geometry prediction. Using the lightweight probe, our framework enables a controlled comparison of what information is already encoded in frozen representations from two model families. Experimental results reveal a clear complementarity: VLMs are stronger at semantic tagging and instance grouping, while VGMs provide more accessible signals for dense geometry and camera motion. Moreover, a naive fusion of the two already yields a representation that excels at both geometry and semantics, suggesting a promising direction for building stronger spatial-intelligence backbones by effectively integrating features from both model families. Our code is available at \href{https://github.com/om-ai-lab/Probing-VLM-VGM}{https://github.com/om-ai-lab/Probing-VLM-VGM}.
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Apr 10, 2025
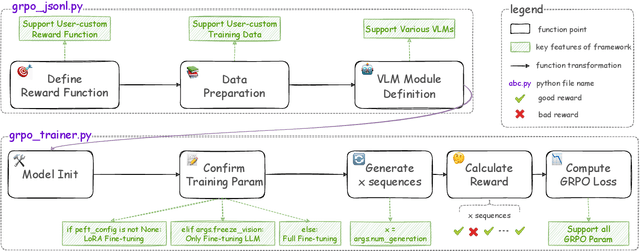
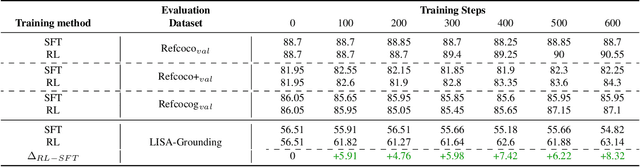
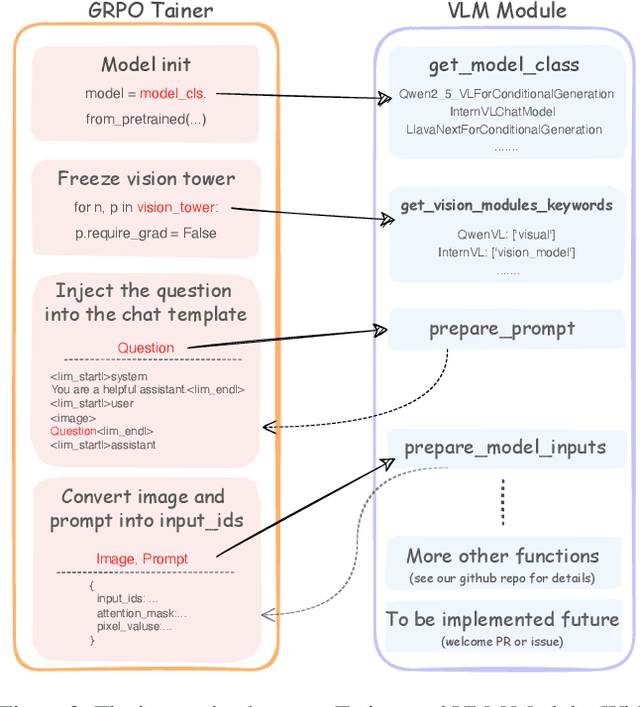
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs' performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the "OD aha moment", the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
GUI Testing Arena: A Unified Benchmark for Advancing Autonomous GUI Testing Agent
Dec 24, 2024



Nowadays, research on GUI agents is a hot topic in the AI community. However, current research focuses on GUI task automation, limiting the scope of applications in various GUI scenarios. In this paper, we propose a formalized and comprehensive environment to evaluate the entire process of automated GUI Testing (GTArena), offering a fair, standardized environment for consistent operation of diverse multimodal large language models. We divide the testing process into three key subtasks: test intention generation, test task execution, and GUI defect detection, and construct a benchmark dataset based on these to conduct a comprehensive evaluation. It evaluates the performance of different models using three data types: real mobile applications, mobile applications with artificially injected defects, and synthetic data, thoroughly assessing their capabilities in this relevant task. Additionally, we propose a method that helps researchers explore the correlation between the performance of multimodal language large models in specific scenarios and their general capabilities in standard benchmark tests. Experimental results indicate that even the most advanced models struggle to perform well across all sub-tasks of automated GUI Testing, highlighting a significant gap between the current capabilities of Autonomous GUI Testing and its practical, real-world applicability. This gap provides guidance for the future direction of GUI Agent development. Our code is available at https://github.com/ZJU-ACES-ISE/ChatUITest.
ZoomEye: Enhancing Multimodal LLMs with Human-Like Zooming Capabilities through Tree-Based Image Exploration
Nov 25, 2024

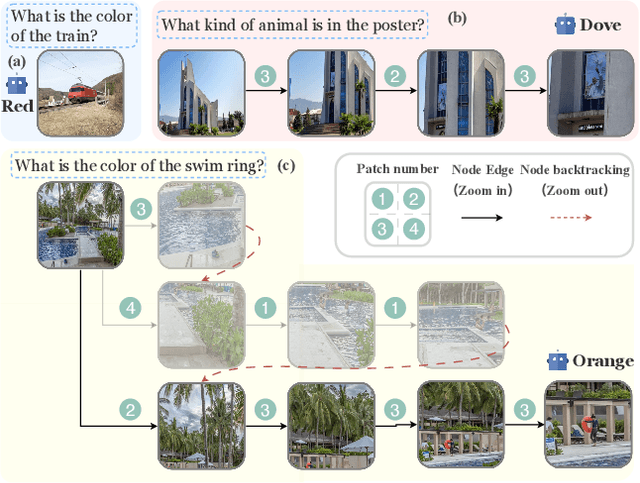
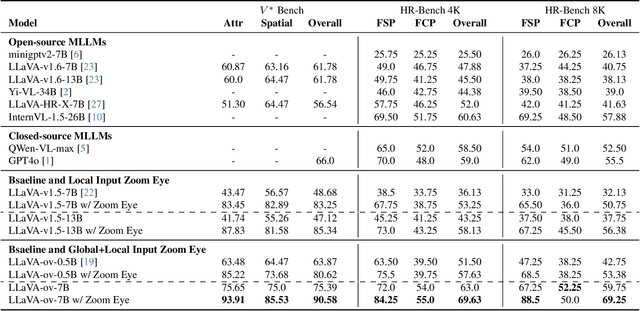
An image, especially with high-resolution, typically consists of numerous visual elements, ranging from dominant large objects to fine-grained detailed objects. When perceiving such images, multimodal large language models~(MLLMs) face limitations due to the restricted input resolution of the pretrained vision encoder and the cluttered, dense context of the image, resulting in a focus on primary objects while easily overlooking detailed ones. In this paper, we propose Zoom Eye, a tree search algorithm designed to navigate the hierarchical and visual nature of images to capture relevant information. Zoom Eye conceptualizes an image as a tree, with each children node representing a zoomed sub-patch of the parent node and the root represents the overall image. Moreover, Zoom Eye is model-agnostic and training-free, so it enables any MLLMs to simulate human zooming actions by searching along the image tree from root to leaf nodes, seeking out pertinent information, and accurately responding to related queries. We experiment on a series of elaborate high-resolution benchmarks and the results demonstrate that Zoom Eye not only consistently improves the performance of a series base MLLMs with large margin~(e.g., LLaVA-v1.5-7B increases by 34.57\% on $V^*$ Bench and 17.88\% on HR-Bench), but also enables small 7B MLLMs to outperform strong large models such as GPT-4o. Our code is available at \href{https://github.com/om-ai-lab/ZoomEye}{https://github.com/om-ai-lab/ZoomEye}.
HORAE: A Domain-Agnostic Modeling Language for Automating Multimodal Service Regulation
Jun 06, 2024



Artificial intelligence is rapidly encroaching on the field of service regulation. This work presents the design principles behind HORAE, a unified specification language to model multimodal regulation rules across a diverse set of domains. We show how HORAE facilitates an intelligent service regulation pipeline by further exploiting a fine-tuned large language model named HORAE that automates the HORAE modeling process, thereby yielding an end-to-end framework for fully automated intelligent service regulation.
Benchmarking Sequential Visual Input Reasoning and Prediction in Multimodal Large Language Models
Oct 20, 2023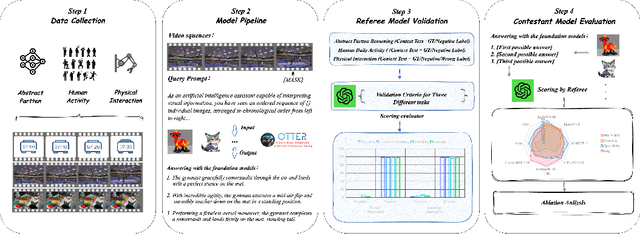
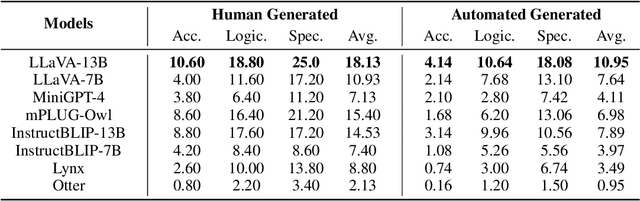

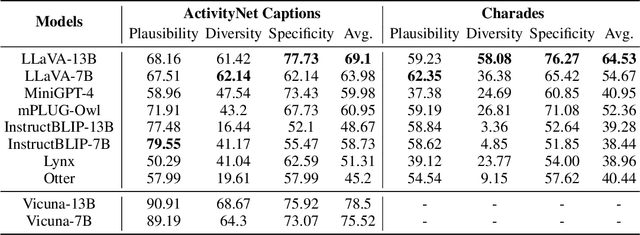
Multimodal large language models (MLLMs) have shown great potential in perception and interpretation tasks, but their capabilities in predictive reasoning remain under-explored. To address this gap, we introduce a novel benchmark that assesses the predictive reasoning capabilities of MLLMs across diverse scenarios. Our benchmark targets three important domains: abstract pattern reasoning, human activity prediction, and physical interaction prediction. We further develop three evaluation methods powered by large language model to robustly quantify a model's performance in predicting and reasoning the future based on multi-visual context. Empirical experiments confirm the soundness of the proposed benchmark and evaluation methods via rigorous testing and reveal pros and cons of current popular MLLMs in the task of predictive reasoning. Lastly, our proposed benchmark provides a standardized evaluation framework for MLLMs and can facilitate the development of more advanced models that can reason and predict over complex long sequence of multimodal input.