 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
Nov 18, 2025Serving deep learning based recommendation models (DLRM) at scale is challenging. Existing systems rely on CPU-based ANN indexing and filtering services, suffering from non-negligible costs and forgoing joint optimization opportunities. Such inefficiency makes them difficult to support more complex model architectures, such as learned similarities and multi-task retrieval. In this paper, we propose SilverTorch, a model-based system for serving recommendation models on GPUs. SilverTorch unifies model serving by replacing standalone indexing and filtering services with layers of served models. We propose a Bloom index algorithm on GPUs for feature filtering and a tensor-native fused Int8 ANN kernel on GPUs for nearest neighbor search. We further co-design the ANN search index and filtering index to reduce GPU memory utilization and eliminate unnecessary computation. Benefit from SilverTorch's serving paradigm, we introduce a OverArch scoring layer and a Value Model to aggregate results across multi-tasks. These advancements improve the accuracy for retrieval and enable future studies for serving more complex models. For ranking, SilverTorch's design accelerates item embedding calculation by caching the pre-calculated embeddings inside the serving model. Our evaluation on the industry-scale datasets show that SilverTorch achieves up to 5.6x lower latency and 23.7x higher throughput compared to the state-of-the-art approaches. We also demonstrate that SilverTorch's solution is 13.35x more cost-efficient than CPU-based solution while improving accuracy via serving more complex models. SilverTorch serves over hundreds of models online across major products and recommends contents for billions of daily active users.
Privacy Preserving Semantic Communications Using Vision Language Models: A Segmentation and Generation Approach
Sep 09, 2025Semantic communication has emerged as a promising paradigm for next-generation wireless systems, improving the communication efficiency by transmitting high-level semantic features. However, reliance on unimodal representations can degrade reconstruction under poor channel conditions, and privacy concerns of the semantic information attack also gain increasing attention. In this work, a privacy-preserving semantic communication framework is proposed to protect sensitive content of the image data. Leveraging a vision-language model (VLM), the proposed framework identifies and removes private content regions from input images prior to transmission. A shared privacy database enables semantic alignment between the transmitter and receiver to ensure consistent identification of sensitive entities. At the receiver, a generative module reconstructs the masked regions using learned semantic priors and conditioned on the received text embedding. Simulation results show that generalizes well to unseen image processing tasks, improves reconstruction quality at the authorized receiver by over 10% using text embedding, and reduces identity leakage to the eavesdropper by more than 50%.
Unifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research
May 30, 2025


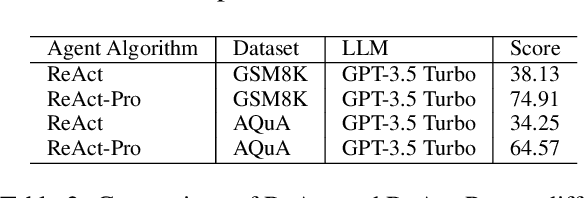
Language agents powered by large language models (LLMs) have demonstrated remarkable capabilities in understanding, reasoning, and executing complex tasks. However, developing robust agents presents significant challenges: substantial engineering overhead, lack of standardized components, and insufficient evaluation frameworks for fair comparison. We introduce Agent Graph-based Orchestration for Reasoning and Assessment (AGORA), a flexible and extensible framework that addresses these challenges through three key contributions: (1) a modular architecture with a graph-based workflow engine, efficient memory management, and clean component abstraction; (2) a comprehensive suite of reusable agent algorithms implementing state-of-the-art reasoning approaches; and (3) a rigorous evaluation framework enabling systematic comparison across multiple dimensions. Through extensive experiments on mathematical reasoning and multimodal tasks, we evaluate various agent algorithms across different LLMs, revealing important insights about their relative strengths and applicability. Our results demonstrate that while sophisticated reasoning approaches can enhance agent capabilities, simpler methods like Chain-of-Thought often exhibit robust performance with significantly lower computational overhead. AGORA not only simplifies language agent development but also establishes a foundation for reproducible agent research through standardized evaluation protocols.
Selective Structured State Space for Multispectral-fused Small Target Detection
May 21, 2025Target detection in high-resolution remote sensing imagery faces challenges due to the low recognition accuracy of small targets and high computational costs. The computational complexity of the Transformer architecture increases quadratically with image resolution, while Convolutional Neural Networks (CNN) architectures are forced to stack deeper convolutional layers to expand their receptive fields, leading to an explosive growth in computational demands. To address these computational constraints, we leverage Mamba's linear complexity for efficiency. However, Mamba's performance declines for small targets, primarily because small targets occupy a limited area in the image and have limited semantic information. Accurate identification of these small targets necessitates not only Mamba's global attention capabilities but also the precise capture of fine local details. To this end, we enhance Mamba by developing the Enhanced Small Target Detection (ESTD) module and the Convolutional Attention Residual Gate (CARG) module. The ESTD module bolsters local attention to capture fine-grained details, while the CARG module, built upon Mamba, emphasizes spatial and channel-wise information, collectively improving the model's ability to capture distinctive representations of small targets. Additionally, to highlight the semantic representation of small targets, we design a Mask Enhanced Pixel-level Fusion (MEPF) module for multispectral fusion, which enhances target features by effectively fusing visible and infrared multimodal information.
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Apr 10, 2025
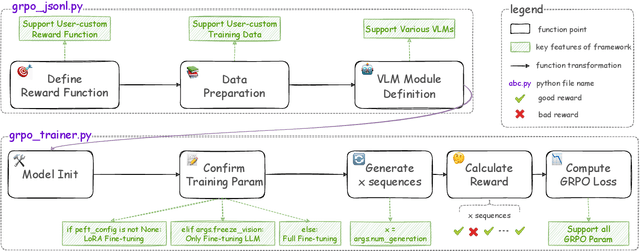
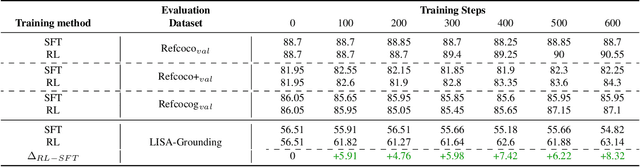
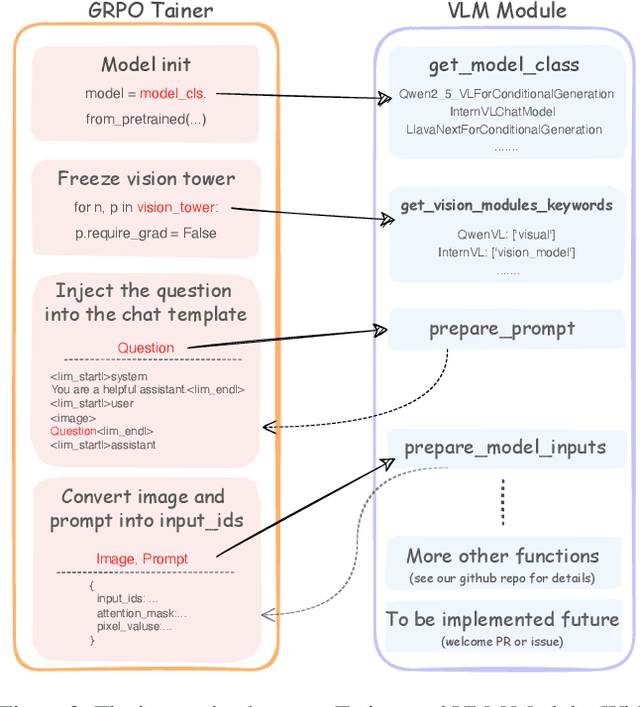
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs' performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the "OD aha moment", the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
Latency Optimization in LEO Satellite Communications with Hybrid Beam Pattern and Interference Control
Nov 14, 2024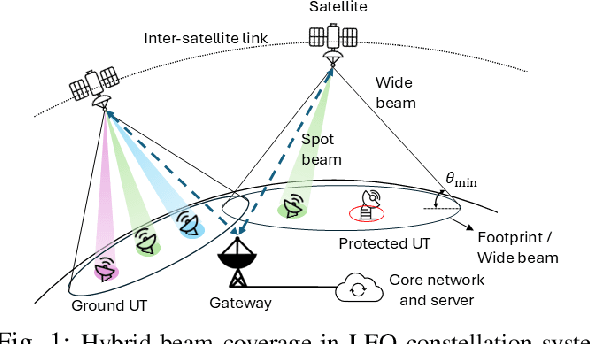
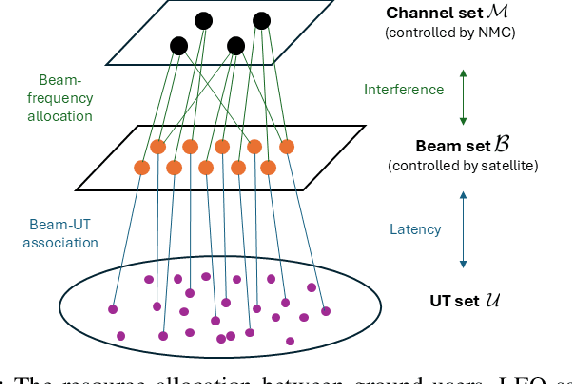
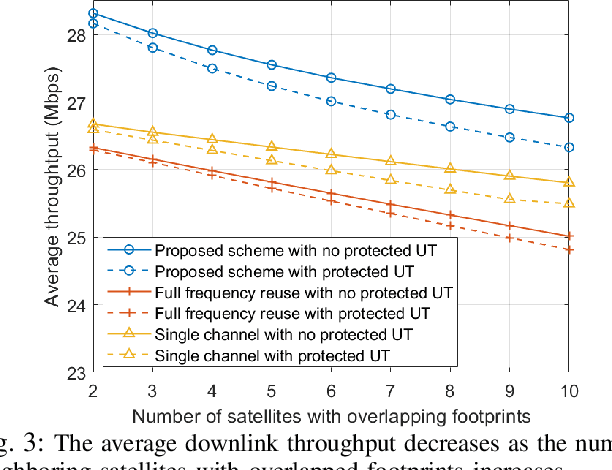
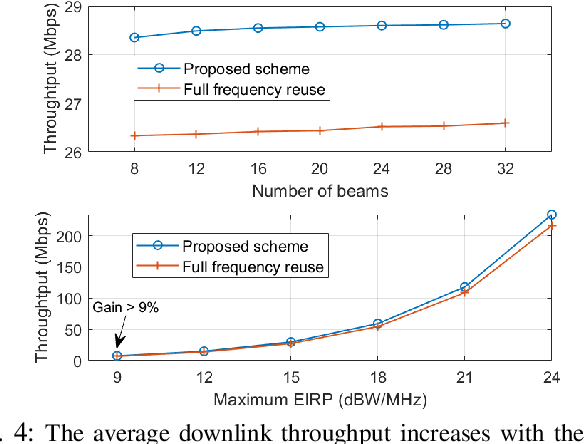
The rapid advancement of low Earth orbit (LEO) satellite communication systems has significantly enhanced global connectivity, offering high-capacity, low-latency services crucial for next-generation applications. However, the dense configuration of LEO constellations poses challenges in resource allocation optimization and interference management, complicating coexistence with other communication systems. To address these limitations, this paper proposes a novel framework for optimizing the beam scheduling and resource allocation in multi-beam LEO systems. To satisfy the uneven terrestrial traffic demand, a hybrid beam pattern is employed to enhance the downlink quality of service and minimize the transmission latency from LEO satellites to ground user terminals. Additionally, a dynamic co-channel interference (CCI) control mechanism is developed to mitigate inter-beam interference within the LEO constellation and limit cross-system interference affecting protected users from other networks. The problem of user-beam-frequency allocation with power optimization is formulated as a mixed-integer dynamic programming model and solved using a low-complexity neural network-based graph generation algorithm. Simulation results show that the proposed approach outperforms the baseline methods of full frequency reuse and single-channel transmission, and highlights the potential for further performance improvement with multi-user transmissions.
OmChat: A Recipe to Train Multimodal Language Models with Strong Long Context and Video Understanding
Jul 06, 2024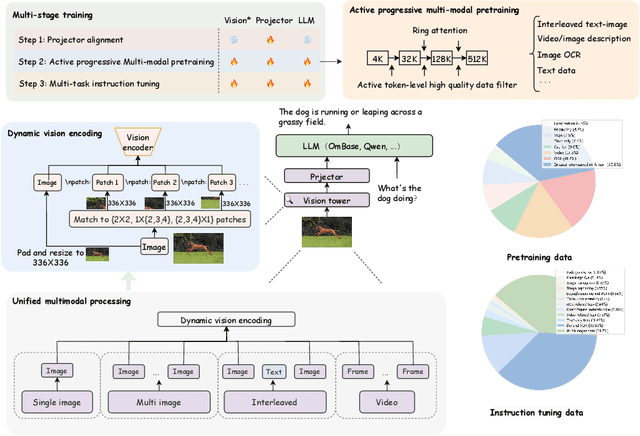
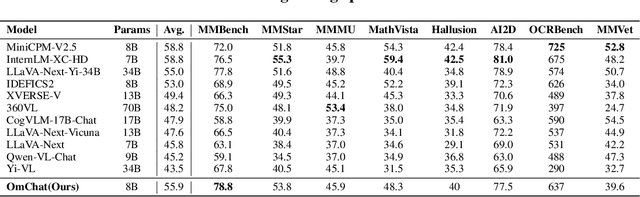
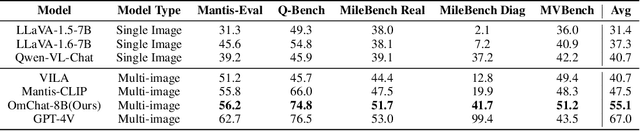
We introduce OmChat, a model designed to excel in handling long contexts and video understanding tasks. OmChat's new architecture standardizes how different visual inputs are processed, making it more efficient and adaptable. It uses a dynamic vision encoding process to effectively handle images of various resolutions, capturing fine details across a range of image qualities. OmChat utilizes an active progressive multimodal pretraining strategy, which gradually increases the model's capacity for long contexts and enhances its overall abilities. By selecting high-quality data during training, OmChat learns from the most relevant and informative data points. With support for a context length of up to 512K, OmChat demonstrates promising performance in tasks involving multiple images and videos, outperforming most open-source models in these benchmarks. Additionally, OmChat proposes a prompting strategy for unifying complex multimodal inputs including single image text, multi-image text and videos, and achieving competitive performance on single-image benchmarks. To further evaluate the model's capabilities, we proposed a benchmark dataset named Temporal Visual Needle in a Haystack. This dataset assesses OmChat's ability to comprehend temporal visual details within long videos. Our analysis highlights several key factors contributing to OmChat's success: support for any-aspect high image resolution, the active progressive pretraining strategy, and high-quality supervised fine-tuning datasets. This report provides a detailed overview of OmChat's capabilities and the strategies that enhance its performance in visual understanding.
Hierarchical Cognitive Spectrum Sharing in Space-Air-Ground Integrated Networks
Dec 13, 2023



In space-air-ground integrated networks (SAGINs), cognitive spectrum sharing has been regarded as a promising solution to improve spectrum efficiency by enabling a secondary network to access the spectrum of a primary network. However, different networks in SAGIN may have different quality of service (QoS) requirements, which can not be well satisfied with the traditional cognitive spectrum sharing architecture. For example, the aerial network typically has high QoS requirements, which however may not be met when it acts as a secondary network. To address this issue, in this paper, we propose a hierarchical cognitive spectrum sharing architecture (HCSSA) for SAGINs, where the secondary networks are divided into a preferential one and an ordinary one. Specifically, the aerial and terrestrial networks can access the spectrum of the satellite network under the condition that the caused interference to the satellite terminal is below a certain threshold. Besides, considering that the aerial network has a higher priority than the terrestrial network, we aim to use a rate constraint to ensure the performance of the aerial network. Subject to these two constraints, we consider a sum-rate maximization for the terrestrial network by jointly optimizing the transmit beamforming vectors of the aerial and terrestrial base stations. To solve this non-convex problem, we propose a penalty-based iterative beamforming (PIBF) scheme that uses the penalty method and the successive convex approximation technique. Moreover, we also develop three low-complexity schemes by optimizing the normalized beamforming vectors and power control. Finally, we provide extensive numerical simulations to compare the performance of the proposed PIBF scheme and the low-complexity schemes. The results also demonstrate the advantages of the proposed HCSSA compared with the traditional cognitive spectrum sharing architecture.
Pilot Design and Signal Detection for Symbiotic Radio over OFDM Carriers
Nov 06, 2023



Symbiotic radio (SR) is a promising solution to achieve high spectrum- and energy-efficiency due to its spectrum sharing and low-power consumption properties, in which the secondary system achieves data transmissions by backscattering the signal originating from the primary system. In this paper, we are interested in the pilot design and signal detection when the primary transmission adopts orthogonal frequency division multiplexing (OFDM). In particular, to preserve the channel orthogonality among the OFDM sub-carriers, each secondary symbol is designed to span an entire OFDM symbol. The comb-type pilot structure is employed by the primary transmission, while the preamble pilot structure is used by the secondary transmission. With the designed pilot structures, the primary signal can be detected via the conventional methods by treating the secondary signal as a part of the composite channel, i.e., the effective channel of the primary transmission. Furthermore, the secondary signal can be extracted from the estimated composite channel with the help of the detected primary signal. The bit error rate (BER) performance with both perfect and estimated CSI, the diversity orders of the primary and secondary transmissions, and the sensitivity to symbol synchronization error are analyzed. Simulation results show that the performance of the primary transmission is enhanced thanks to the backscatter link established by the secondary transmission. More importantly, even without the direct link, the primary and secondary transmissions can be supported via only the backscatter link.
* This paper has been accepted for publication in IEEE Transactions on Wireless Communications