 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research
May 30, 2025


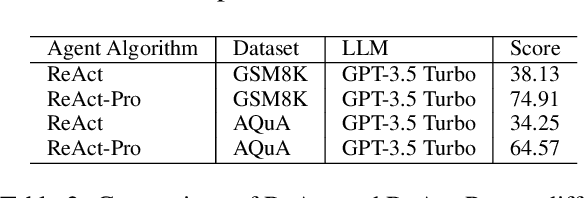
Language agents powered by large language models (LLMs) have demonstrated remarkable capabilities in understanding, reasoning, and executing complex tasks. However, developing robust agents presents significant challenges: substantial engineering overhead, lack of standardized components, and insufficient evaluation frameworks for fair comparison. We introduce Agent Graph-based Orchestration for Reasoning and Assessment (AGORA), a flexible and extensible framework that addresses these challenges through three key contributions: (1) a modular architecture with a graph-based workflow engine, efficient memory management, and clean component abstraction; (2) a comprehensive suite of reusable agent algorithms implementing state-of-the-art reasoning approaches; and (3) a rigorous evaluation framework enabling systematic comparison across multiple dimensions. Through extensive experiments on mathematical reasoning and multimodal tasks, we evaluate various agent algorithms across different LLMs, revealing important insights about their relative strengths and applicability. Our results demonstrate that while sophisticated reasoning approaches can enhance agent capabilities, simpler methods like Chain-of-Thought often exhibit robust performance with significantly lower computational overhead. AGORA not only simplifies language agent development but also establishes a foundation for reproducible agent research through standardized evaluation protocols.
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Apr 10, 2025
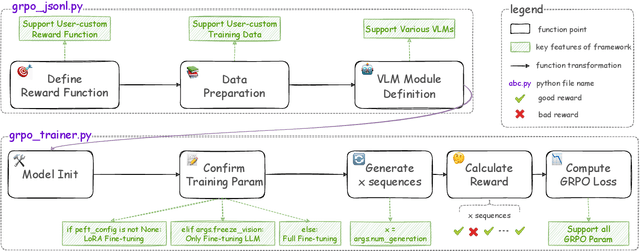
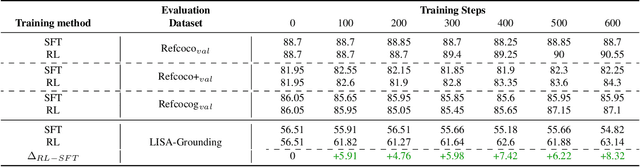
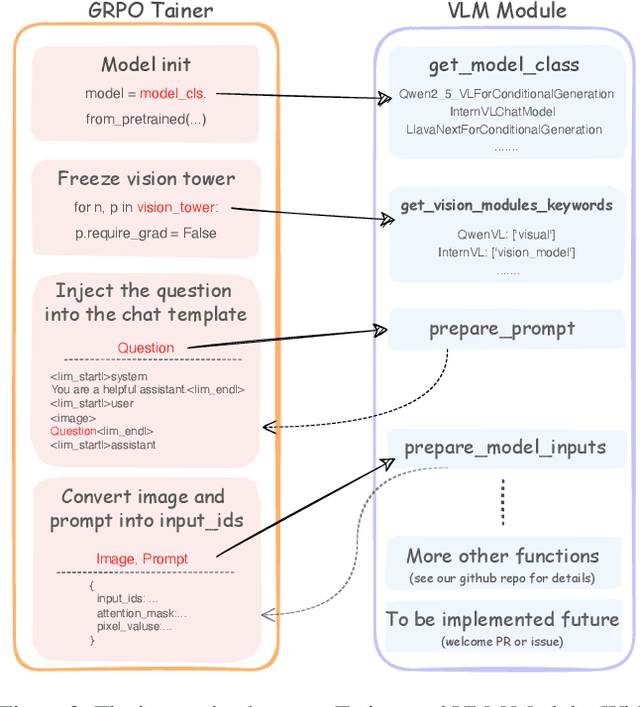
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs' performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the "OD aha moment", the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
OmChat: A Recipe to Train Multimodal Language Models with Strong Long Context and Video Understanding
Jul 06, 2024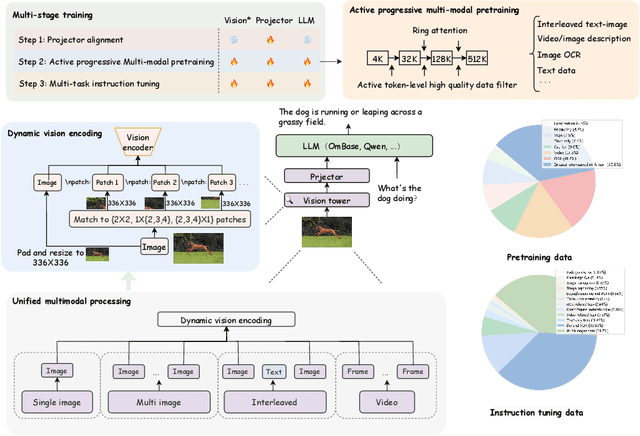
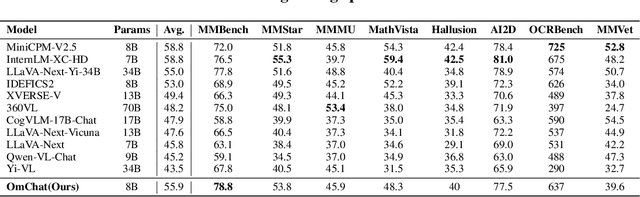
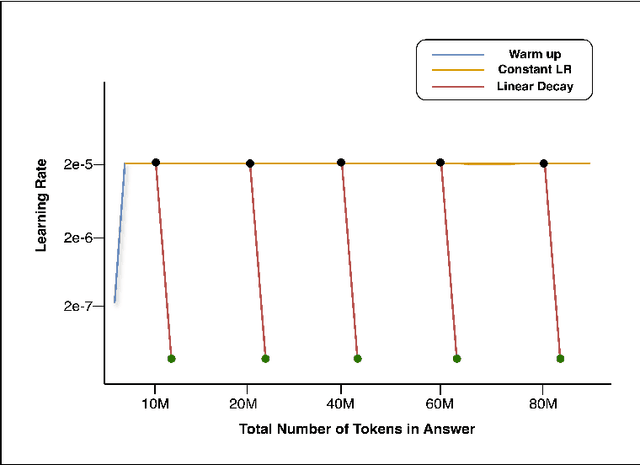
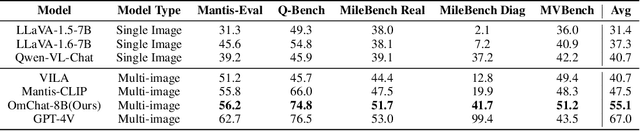
We introduce OmChat, a model designed to excel in handling long contexts and video understanding tasks. OmChat's new architecture standardizes how different visual inputs are processed, making it more efficient and adaptable. It uses a dynamic vision encoding process to effectively handle images of various resolutions, capturing fine details across a range of image qualities. OmChat utilizes an active progressive multimodal pretraining strategy, which gradually increases the model's capacity for long contexts and enhances its overall abilities. By selecting high-quality data during training, OmChat learns from the most relevant and informative data points. With support for a context length of up to 512K, OmChat demonstrates promising performance in tasks involving multiple images and videos, outperforming most open-source models in these benchmarks. Additionally, OmChat proposes a prompting strategy for unifying complex multimodal inputs including single image text, multi-image text and videos, and achieving competitive performance on single-image benchmarks. To further evaluate the model's capabilities, we proposed a benchmark dataset named Temporal Visual Needle in a Haystack. This dataset assesses OmChat's ability to comprehend temporal visual details within long videos. Our analysis highlights several key factors contributing to OmChat's success: support for any-aspect high image resolution, the active progressive pretraining strategy, and high-quality supervised fine-tuning datasets. This report provides a detailed overview of OmChat's capabilities and the strategies that enhance its performance in visual understanding.
How to Evaluate the Generalization of Detection? A Benchmark for Comprehensive Open-Vocabulary Detection
Aug 25, 2023



Object detection (OD) in computer vision has made significant progress in recent years, transitioning from closed-set labels to open-vocabulary detection (OVD) based on large-scale vision-language pre-training (VLP). However, current evaluation methods and datasets are limited to testing generalization over object types and referral expressions, which do not provide a systematic, fine-grained, and accurate benchmark of OVD models' abilities. In this paper, we propose a new benchmark named OVDEval, which includes 9 sub-tasks and introduces evaluations on commonsense knowledge, attribute understanding, position understanding, object relation comprehension, and more. The dataset is meticulously created to provide hard negatives that challenge models' true understanding of visual and linguistic input. Additionally, we identify a problem with the popular Average Precision (AP) metric when benchmarking models on these fine-grained label datasets and propose a new metric called Non-Maximum Suppression Average Precision (NMS-AP) to address this issue. Extensive experimental results show that existing top OVD models all fail on the new tasks except for simple object types, demonstrating the value of the proposed dataset in pinpointing the weakness of current OVD models and guiding future research. Furthermore, the proposed NMS-AP metric is verified by experiments to provide a much more truthful evaluation of OVD models, whereas traditional AP metrics yield deceptive results. Data is available at \url{https://github.com/om-ai-lab/OVDEval}