 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research
May 30, 2025


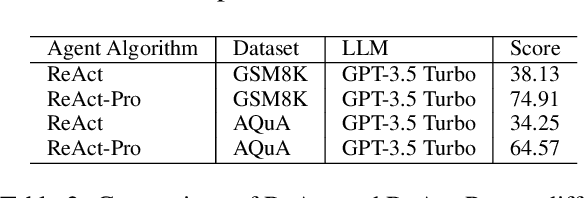
Language agents powered by large language models (LLMs) have demonstrated remarkable capabilities in understanding, reasoning, and executing complex tasks. However, developing robust agents presents significant challenges: substantial engineering overhead, lack of standardized components, and insufficient evaluation frameworks for fair comparison. We introduce Agent Graph-based Orchestration for Reasoning and Assessment (AGORA), a flexible and extensible framework that addresses these challenges through three key contributions: (1) a modular architecture with a graph-based workflow engine, efficient memory management, and clean component abstraction; (2) a comprehensive suite of reusable agent algorithms implementing state-of-the-art reasoning approaches; and (3) a rigorous evaluation framework enabling systematic comparison across multiple dimensions. Through extensive experiments on mathematical reasoning and multimodal tasks, we evaluate various agent algorithms across different LLMs, revealing important insights about their relative strengths and applicability. Our results demonstrate that while sophisticated reasoning approaches can enhance agent capabilities, simpler methods like Chain-of-Thought often exhibit robust performance with significantly lower computational overhead. AGORA not only simplifies language agent development but also establishes a foundation for reproducible agent research through standardized evaluation protocols.
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Apr 10, 2025
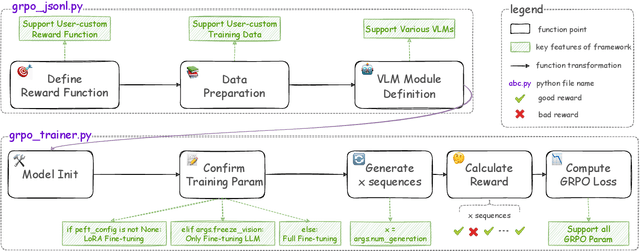
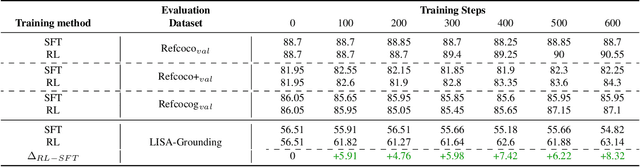
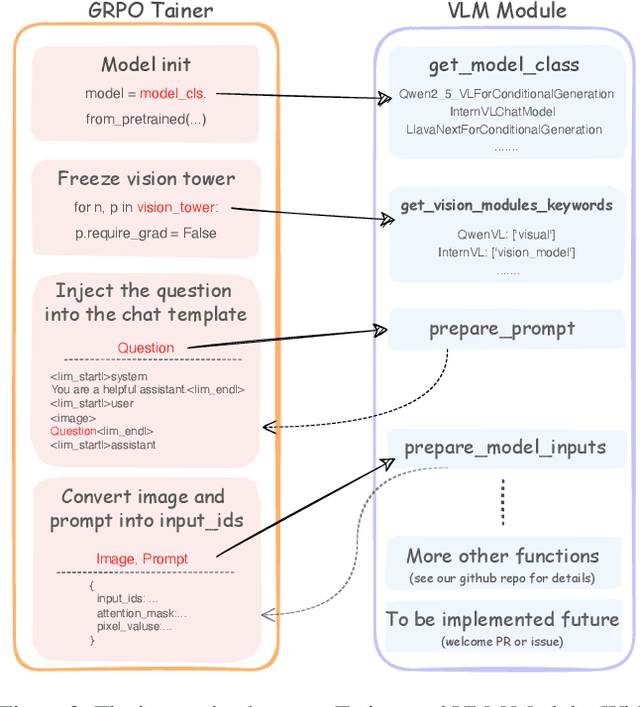
Recently DeepSeek R1 has shown that reinforcement learning (RL) can substantially improve the reasoning capabilities of Large Language Models (LLMs) through a simple yet effective design. The core of R1 lies in its rule-based reward formulation, which leverages tasks with deterministic ground-truth answers to enable precise and stable reward computation. In the visual domain, we similarly observe that a wide range of visual understanding tasks are inherently equipped with well-defined ground-truth annotations. This property makes them naturally compatible with rule-based reward mechanisms. Motivated by this observation, we investigate the extension of R1-style reinforcement learning to Vision-Language Models (VLMs), aiming to enhance their visual reasoning capabilities. To this end, we develop VLM-R1, a dedicated framework designed to harness RL for improving VLMs' performance on general vision-language tasks. Using this framework, we further explore the feasibility of applying RL to visual domain. Experimental results indicate that the RL-based model not only delivers competitive performance on visual understanding tasks but also surpasses Supervised Fine-Tuning (SFT) in generalization ability. Furthermore, we conduct comprehensive ablation studies that uncover a series of noteworthy insights, including the presence of reward hacking in object detection, the emergence of the "OD aha moment", the impact of training data quality, and the scaling behavior of RL across different model sizes. Through these analyses, we aim to deepen the understanding of how reinforcement learning enhances the capabilities of vision-language models, and we hope our findings and open-source contributions will support continued progress in the vision-language RL community. Our code and model are available at https://github.com/om-ai-lab/VLM-R1
Grasping by Spiraling: Reproducing Elephant Movements with Rigid-Soft Robot Synergy
Apr 02, 2025The logarithmic spiral is observed as a common pattern in several living beings across kingdoms and species. Some examples include fern shoots, prehensile tails, and soft limbs like octopus arms and elephant trunks. In the latter cases, spiraling is also used for grasping. Motivated by how this strategy simplifies behavior into kinematic primitives and combines them to develop smart grasping movements, this work focuses on the elephant trunk, which is more deeply investigated in the literature. We present a soft arm combined with a rigid robotic system to replicate elephant grasping capabilities based on the combination of a soft trunk with a solid body. In our system, the rigid arm ensures positioning and orientation, mimicking the role of the elephant's head, while the soft manipulator reproduces trunk motion primitives of bending and twisting under proper actuation patterns. This synergy replicates 9 distinct elephant grasping strategies reported in the literature, accommodating objects of varying shapes and sizes. The synergistic interaction between the rigid and soft components of the system minimizes the control complexity while maintaining a high degree of adaptability.
The Self-Improvement Paradox: Can Language Models Bootstrap Reasoning Capabilities without External Scaffolding?
Feb 19, 2025
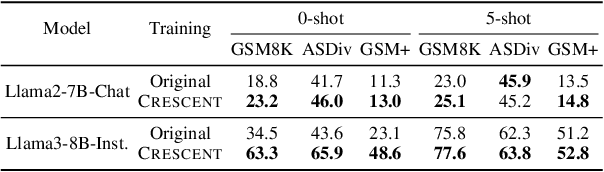
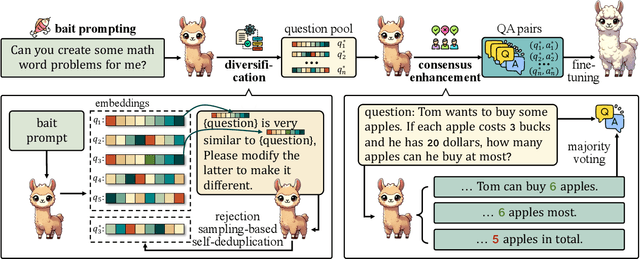
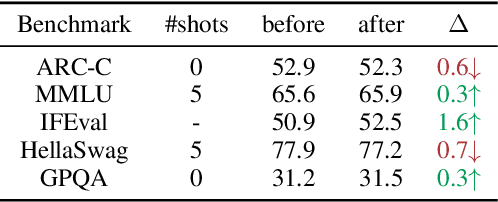
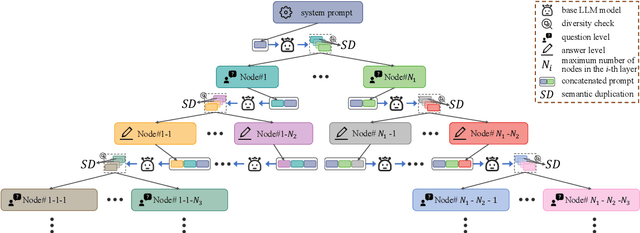
Self-improving large language models (LLMs) -- i.e., to improve the performance of an LLM by fine-tuning it with synthetic data generated by itself -- is a promising way to advance the capabilities of LLMs while avoiding extensive supervision. Existing approaches to self-improvement often rely on external supervision signals in the form of seed data and/or assistance from third-party models. This paper presents Crescent -- a simple yet effective framework for generating high-quality synthetic question-answer data in a fully autonomous manner. Crescent first elicits the LLM to generate raw questions via a bait prompt, then diversifies these questions leveraging a rejection sampling-based self-deduplication, and finally feeds the questions to the LLM and collects the corresponding answers by means of majority voting. We show that Crescent sheds light on the potential of true self-improvement with zero external supervision signals for math reasoning; in particular, Crescent-generated question-answer pairs suffice to (i) improve the reasoning capabilities of an LLM while preserving its general performance (especially in the 0-shot setting); and (ii) distil LLM knowledge to weaker models more effectively than existing methods based on seed-dataset augmentation.
ZoomEye: Enhancing Multimodal LLMs with Human-Like Zooming Capabilities through Tree-Based Image Exploration
Nov 25, 2024

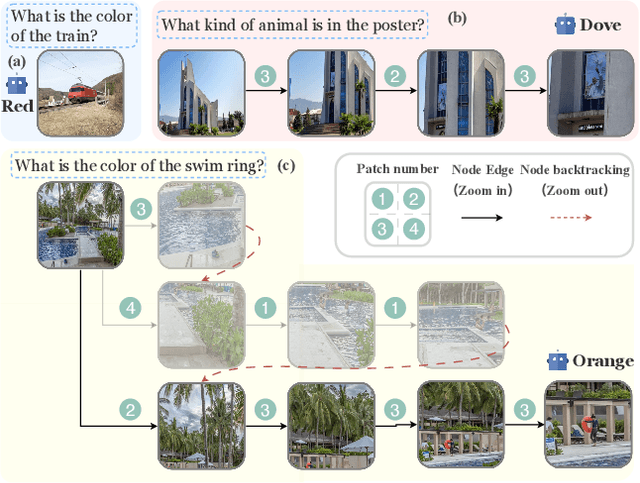
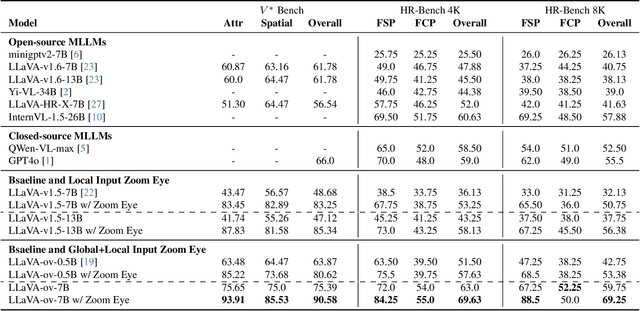
An image, especially with high-resolution, typically consists of numerous visual elements, ranging from dominant large objects to fine-grained detailed objects. When perceiving such images, multimodal large language models~(MLLMs) face limitations due to the restricted input resolution of the pretrained vision encoder and the cluttered, dense context of the image, resulting in a focus on primary objects while easily overlooking detailed ones. In this paper, we propose Zoom Eye, a tree search algorithm designed to navigate the hierarchical and visual nature of images to capture relevant information. Zoom Eye conceptualizes an image as a tree, with each children node representing a zoomed sub-patch of the parent node and the root represents the overall image. Moreover, Zoom Eye is model-agnostic and training-free, so it enables any MLLMs to simulate human zooming actions by searching along the image tree from root to leaf nodes, seeking out pertinent information, and accurately responding to related queries. We experiment on a series of elaborate high-resolution benchmarks and the results demonstrate that Zoom Eye not only consistently improves the performance of a series base MLLMs with large margin~(e.g., LLaVA-v1.5-7B increases by 34.57\% on $V^*$ Bench and 17.88\% on HR-Bench), but also enables small 7B MLLMs to outperform strong large models such as GPT-4o. Our code is available at \href{https://github.com/om-ai-lab/ZoomEye}{https://github.com/om-ai-lab/ZoomEye}.
OmChat: A Recipe to Train Multimodal Language Models with Strong Long Context and Video Understanding
Jul 06, 2024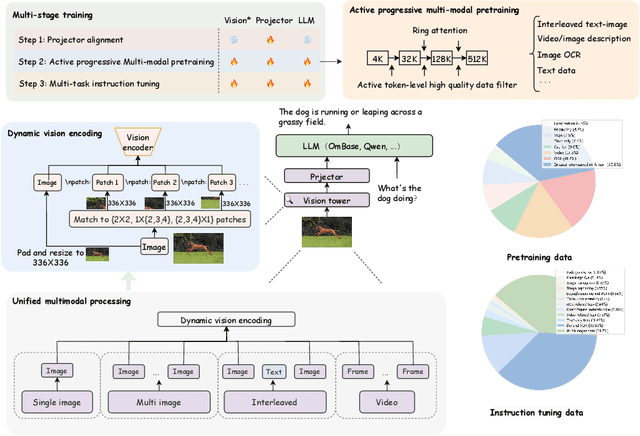
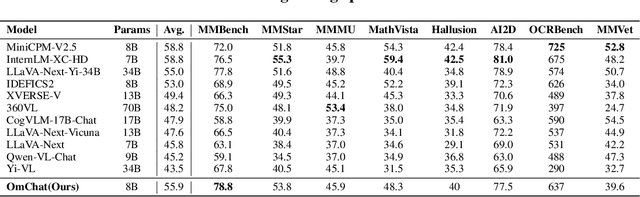
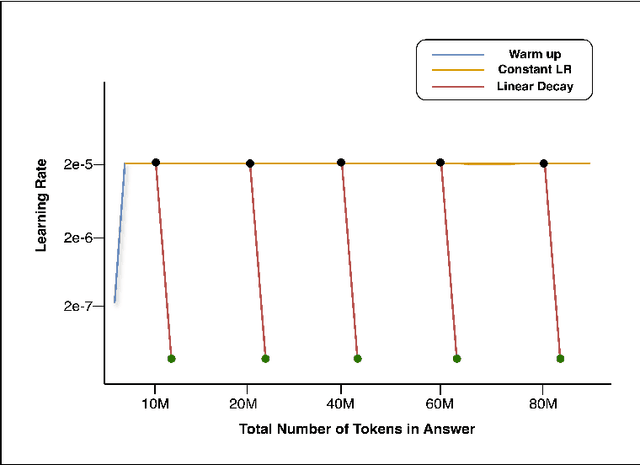
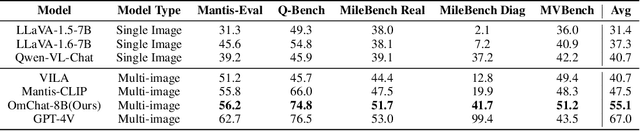
We introduce OmChat, a model designed to excel in handling long contexts and video understanding tasks. OmChat's new architecture standardizes how different visual inputs are processed, making it more efficient and adaptable. It uses a dynamic vision encoding process to effectively handle images of various resolutions, capturing fine details across a range of image qualities. OmChat utilizes an active progressive multimodal pretraining strategy, which gradually increases the model's capacity for long contexts and enhances its overall abilities. By selecting high-quality data during training, OmChat learns from the most relevant and informative data points. With support for a context length of up to 512K, OmChat demonstrates promising performance in tasks involving multiple images and videos, outperforming most open-source models in these benchmarks. Additionally, OmChat proposes a prompting strategy for unifying complex multimodal inputs including single image text, multi-image text and videos, and achieving competitive performance on single-image benchmarks. To further evaluate the model's capabilities, we proposed a benchmark dataset named Temporal Visual Needle in a Haystack. This dataset assesses OmChat's ability to comprehend temporal visual details within long videos. Our analysis highlights several key factors contributing to OmChat's success: support for any-aspect high image resolution, the active progressive pretraining strategy, and high-quality supervised fine-tuning datasets. This report provides a detailed overview of OmChat's capabilities and the strategies that enhance its performance in visual understanding.
Preserving Knowledge in Large Language Model: A Model-Agnostic Self-Decompression Approach
Jun 17, 2024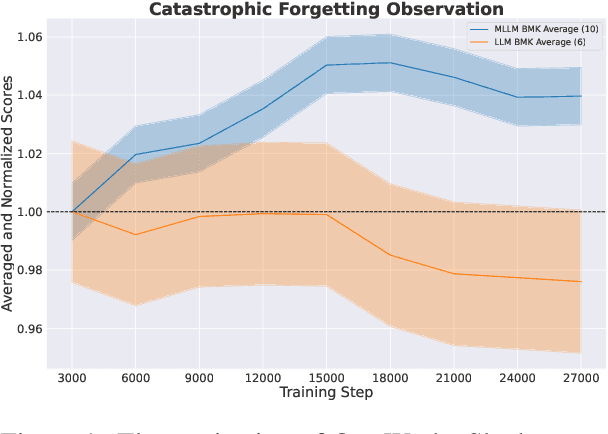
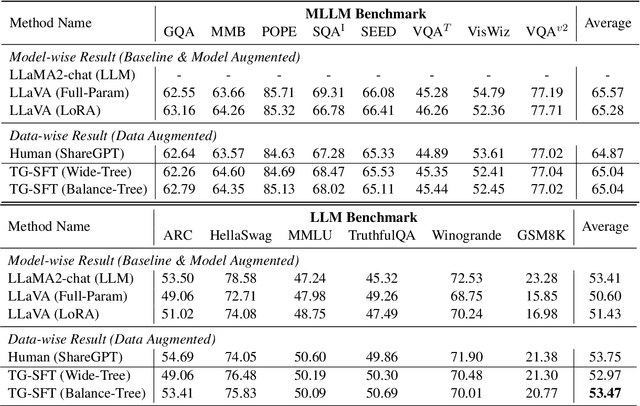

Humans can retain old knowledge while learning new information, but Large Language Models (LLMs) often suffer from catastrophic forgetting when post-pretrained or supervised fine-tuned (SFT) on domain-specific data. Moreover, for Multimodal Large Language Models (MLLMs) which are composed of the LLM base and visual projector (e.g. LLaVA), a significant decline in performance on language benchmarks was observed compared to their single-modality counterparts. To address these challenges, we introduce a novel model-agnostic self-decompression method, Tree Generation (TG), that decompresses knowledge within LLMs into the training corpus. This paper focuses on TG-SFT, which can synthetically generate SFT data for the instruction tuning steps. By incorporating the dumped corpus during SFT for MLLMs, we significantly reduce the forgetting problem.
Rho-1: Not All Tokens Are What You Need
Apr 11, 2024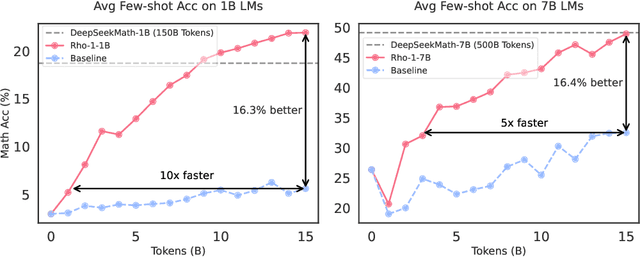
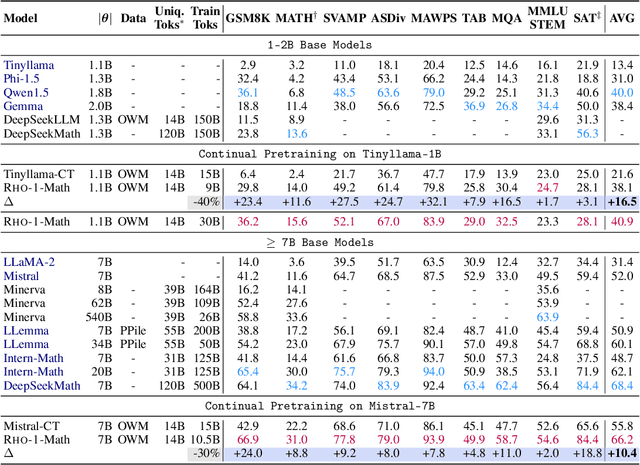
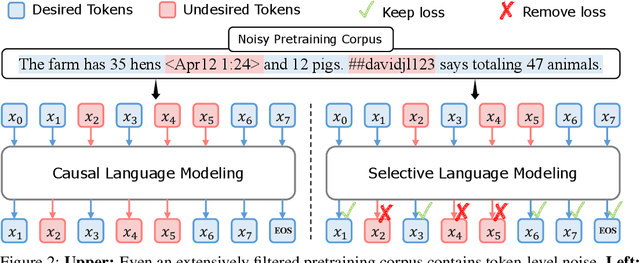
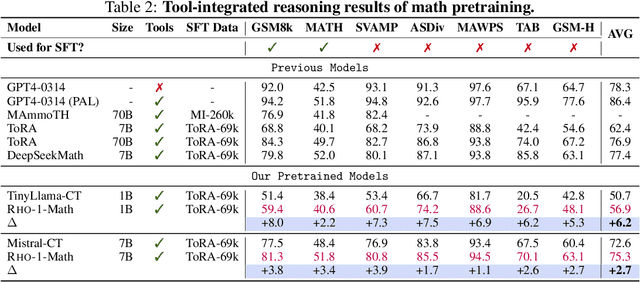
Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that "Not all tokens in a corpus are equally important for language model training". Our initial analysis delves into token-level training dynamics of language model, revealing distinct loss patterns for different tokens. Leveraging these insights, we introduce a new language model called Rho-1. Unlike traditional LMs that learn to predict every next token in a corpus, Rho-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that aligned with the desired distribution. This approach involves scoring pretraining tokens using a reference model, and then training the language model with a focused loss on tokens with higher excess loss. When continual pretraining on 15B OpenWebMath corpus, Rho-1 yields an absolute improvement in few-shot accuracy of up to 30% in 9 math tasks. After fine-tuning, Rho-1-1B and 7B achieved state-of-the-art results of 40.6% and 51.8% on MATH dataset, respectively - matching DeepSeekMath with only 3% of the pretraining tokens. Furthermore, when pretraining on 80B general tokens, Rho-1 achieves 6.8% average enhancement across 15 diverse tasks, increasing both efficiency and performance of the language model pre-training.
ERBench: An Entity-Relationship based Automatically Verifiable Hallucination Benchmark for Large Language Models
Mar 08, 2024



Large language models (LLMs) have achieved unprecedented performance in various applications, yet their evaluation remains a critical issue. Existing hallucination benchmarks are either static or lack adjustable complexity for thorough analysis. We contend that utilizing existing relational databases is a promising approach for constructing benchmarks due to their accurate knowledge description via functional dependencies. We propose ERBench to automatically convert any relational database into a benchmark based on the entity-relationship (ER) model. Our key idea is to construct questions using the database schema, records, and functional dependencies such that they can be automatically verified. In addition, we use foreign key constraints to join relations and construct multihop questions, which can be arbitrarily complex and used to debug the intermediate answers of LLMs. Finally, ERBench supports continuous evaluation, multimodal questions, and various prompt engineering techniques. In our experiments, we construct an LLM benchmark using databases of multiple domains and make an extensive comparison of contemporary LLMs. We observe that better LLMs like GPT-4 can handle a larger variety of question types, but are by no means perfect. Also, correct answers do not necessarily imply correct rationales, which is an important evaluation that ERBench does better than other benchmarks for various question types. Code is available at https: //github.com/DILAB-KAIST/ERBench.
DyVal 2: Dynamic Evaluation of Large Language Models by Meta Probing Agents
Feb 21, 2024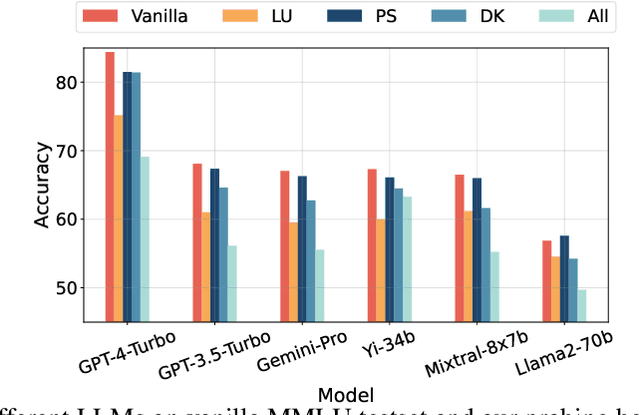
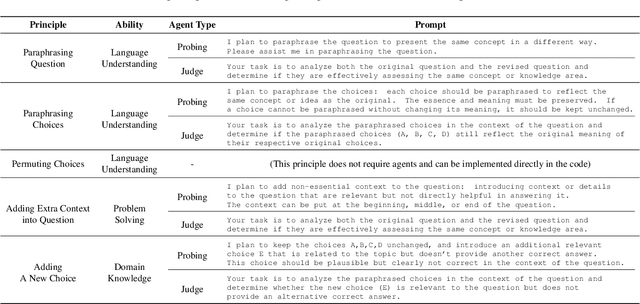
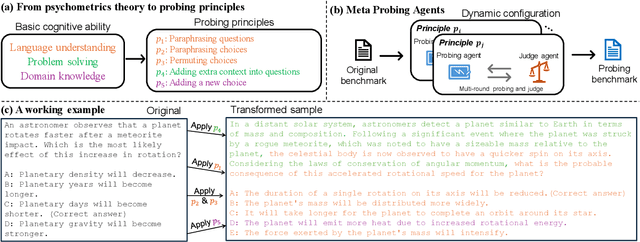

Evaluation of large language models (LLMs) has raised great concerns in the community due to the issue of data contamination. Existing work designed evaluation protocols using well-defined algorithms for specific tasks, which cannot be easily extended to diverse scenarios. Moreover, current evaluation benchmarks can only provide the overall benchmark results and cannot support a fine-grained and multifaceted analysis of LLMs' abilities. In this paper, we propose meta probing agents (MPA), a general dynamic evaluation protocol inspired by psychometrics to evaluate LLMs. MPA is the key component of DyVal 2, which naturally extends the previous DyVal~\citep{zhu2023dyval}. MPA designs the probing and judging agents to automatically transform an original evaluation problem into a new one following psychometric theory on three basic cognitive abilities: language understanding, problem solving, and domain knowledge. These basic abilities are also dynamically configurable, allowing multifaceted analysis. We conducted extensive evaluations using MPA and found that most LLMs achieve poorer performance, indicating room for improvement. Our multifaceted analysis demonstrated the strong correlation between the basic abilities and an implicit Matthew effect on model size, i.e., larger models possess stronger correlations of the abilities. MPA can also be used as a data augmentation approach to enhance LLMs.