 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoomEye: Enhancing Multimodal LLMs with Human-Like Zooming Capabilities through Tree-Based Image Exploration
Nov 25, 2024

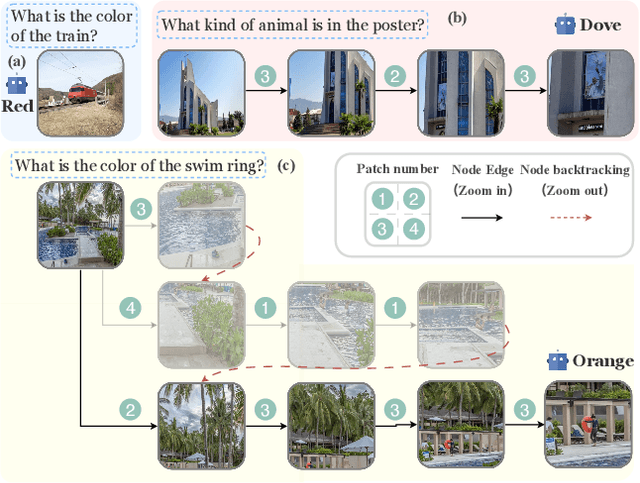
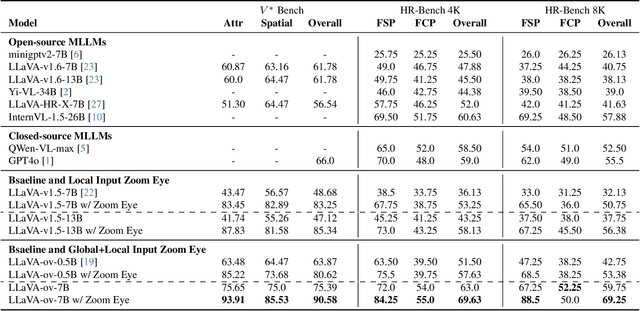
An image, especially with high-resolution, typically consists of numerous visual elements, ranging from dominant large objects to fine-grained detailed objects. When perceiving such images, multimodal large language models~(MLLMs) face limitations due to the restricted input resolution of the pretrained vision encoder and the cluttered, dense context of the image, resulting in a focus on primary objects while easily overlooking detailed ones. In this paper, we propose Zoom Eye, a tree search algorithm designed to navigate the hierarchical and visual nature of images to capture relevant information. Zoom Eye conceptualizes an image as a tree, with each children node representing a zoomed sub-patch of the parent node and the root represents the overall image. Moreover, Zoom Eye is model-agnostic and training-free, so it enables any MLLMs to simulate human zooming actions by searching along the image tree from root to leaf nodes, seeking out pertinent information, and accurately responding to related queries. We experiment on a series of elaborate high-resolution benchmarks and the results demonstrate that Zoom Eye not only consistently improves the performance of a series base MLLMs with large margin~(e.g., LLaVA-v1.5-7B increases by 34.57\% on $V^*$ Bench and 17.88\% on HR-Bench), but also enables small 7B MLLMs to outperform strong large models such as GPT-4o. Our code is available at \href{https://github.com/om-ai-lab/ZoomEye}{https://github.com/om-ai-lab/ZoomEye}.
The intelligent prediction and assessment of financial information risk in the cloud computing model
Apr 14, 2024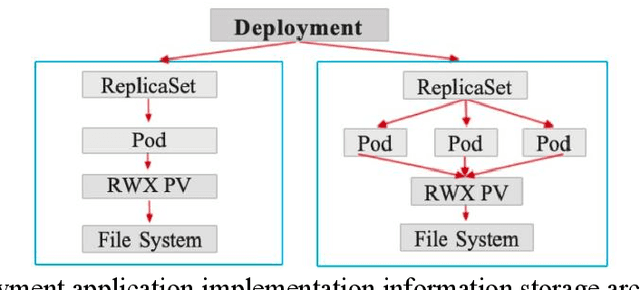
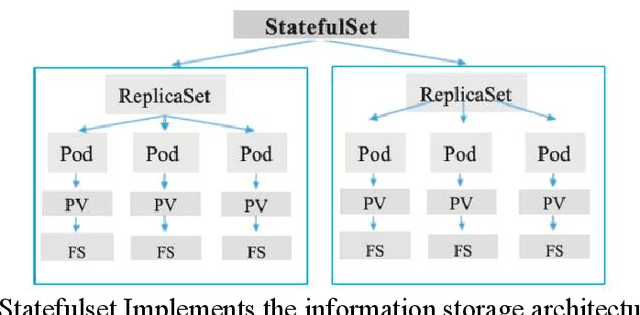

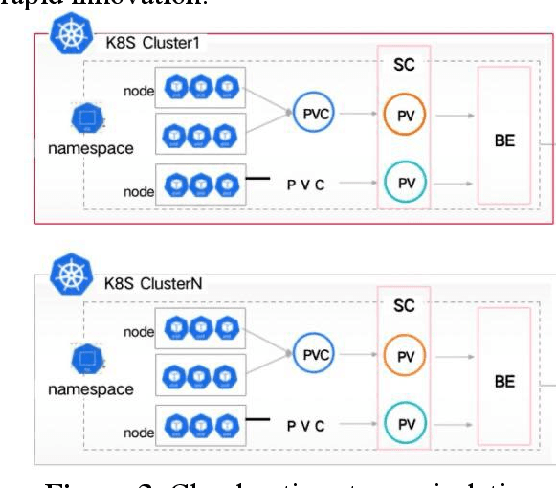
Cloud computing (cloud computing) is a kind of distributed computing, referring to the network "cloud" will be a huge data calculation and processing program into countless small programs, and then, through the system composed of multiple servers to process and analyze these small programs to get the results and return to the user. This report explores the intersection of cloud computing and financial information processing, identifying risks and challenges faced by financial institutions in adopting cloud technology. It discusses the need for intelligent solutions to enhance data processing efficiency and accuracy while addressing security and privacy concerns. Drawing on regulatory frameworks, the report proposes policy recommendations to mitigate concentration risks associated with cloud computing in the financial industry. By combining intelligent forecasting and evaluation technologies with cloud computing models, the study aims to provide effective solutions for financial data processing and management, facilitating the industry's transition towards digital transformation.
Intelligent Classification and Personalized Recommendation of E-commerce Products Based on Machine Learning
Mar 28, 2024With the rapid evolution of the Internet and the exponential proliferation of information, users encounter information overload and the conundrum of choice. Personalized recommendation systems play a pivotal role in alleviating this burden by aiding users in filtering and selecting information tailored to their preferences and requirements. Such systems not only enhance user experience and satisfaction but also furnish opportunities for businesses and platforms to augment user engagement, sales, and advertising efficacy.This paper undertakes a comparative analysis between the operational mechanisms of traditional e-commerce commodity classification systems and personalized recommendation systems. It delineates the significance and application of personalized recommendation systems across e-commerce, content information, and media domains. Furthermore, it delves into the challenges confronting personalized recommendation systems in e-commerce, including data privacy, algorithmic bias, scalability, and the cold start problem. Strategies to address these challenges are elucidated.Subsequently, the paper outlines a personalized recommendation system leveraging the BERT model and nearest neighbor algorithm, specifically tailored to address the exigencies of the eBay e-commerce platform. The efficacy of this recommendation system is substantiated through manual evaluation, and a practical application operational guide and structured output recommendation results are furnished to ensure the system's operability and scalability.
GroundVLP: Harnessing Zero-shot Visual Grounding from Vision-Language Pre-training and Open-Vocabulary Object Detection
Dec 22, 2023



Visual grounding, a crucial vision-language task involving the understanding of the visual context based on the query expression, necessitates the model to capture the interactions between objects, as well as various spatial and attribute information. However, the annotation data of visual grounding task is limited due to its time-consuming and labor-intensive annotation process, resulting in the trained models being constrained from generalizing its capability to a broader domain. To address this challenge, we propose GroundVLP, a simple yet effective zero-shot method that harnesses visual grounding ability from the existing models trained from image-text pairs and pure object detection data, both of which are more conveniently obtainable and offer a broader domain compared to visual grounding annotation data. GroundVLP proposes a fusion mechanism that combines the heatmap from GradCAM and the object proposals of open-vocabulary detectors. We demonstrate that the proposed method significantly outperforms other zero-shot methods on RefCOCO/+/g datasets, surpassing prior zero-shot state-of-the-art by approximately 28\% on the test split of RefCOCO and RefCOCO+. Furthermore, GroundVLP performs comparably to or even better than some non-VLP-based supervised models on the Flickr30k entities dataset. Our code is available at https://github.com/om-ai-lab/GroundVLP.
Benchmarking Sequential Visual Input Reasoning and Prediction in Multimodal Large Language Models
Oct 20, 2023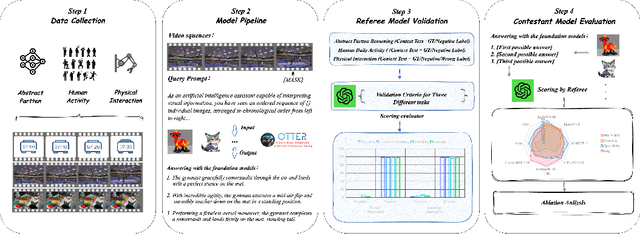
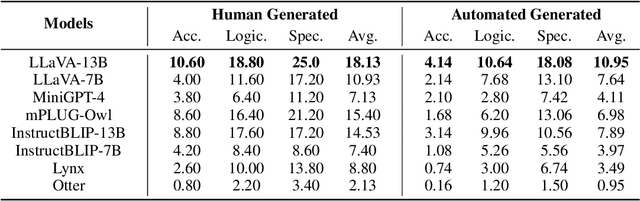

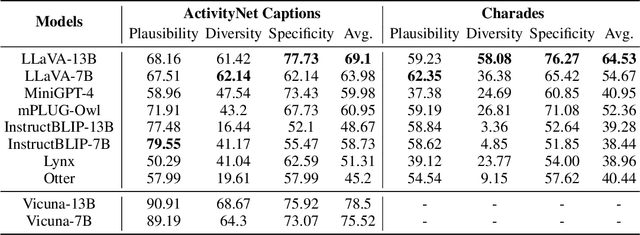
Multimodal large language models (MLLMs) have shown great potential in perception and interpretation tasks, but their capabilities in predictive reasoning remain under-explored. To address this gap, we introduce a novel benchmark that assesses the predictive reasoning capabilities of MLLMs across diverse scenarios. Our benchmark targets three important domains: abstract pattern reasoning, human activity prediction, and physical interaction prediction. We further develop three evaluation methods powered by large language model to robustly quantify a model's performance in predicting and reasoning the future based on multi-visual context. Empirical experiments confirm the soundness of the proposed benchmark and evaluation methods via rigorous testing and reveal pros and cons of current popular MLLMs in the task of predictive reasoning. Lastly, our proposed benchmark provides a standardized evaluation framework for MLLMs and can facilitate the development of more advanced models that can reason and predict over complex long sequence of multimodal input.
VL-CheckList: Evaluating Pre-trained Vision-Language Models with Objects, Attributes and Relations
Jul 01, 2022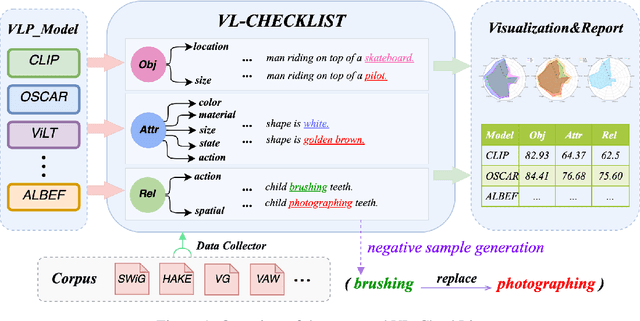
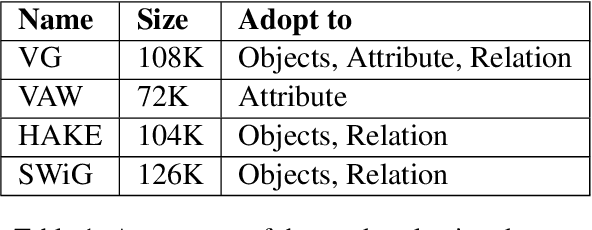
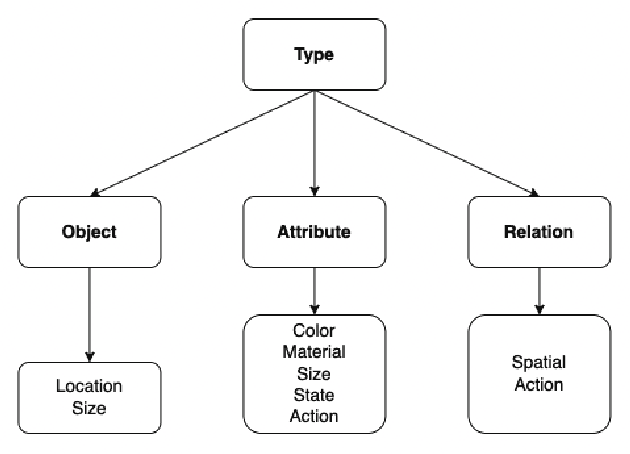
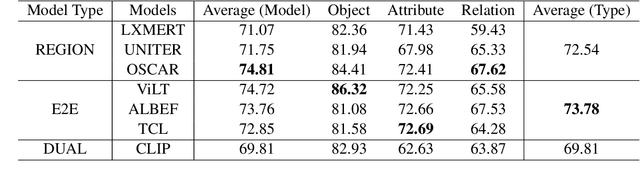
Vision-Language Pretraining (VLP) models have recently successfully facilitated many cross-modal downstream tasks. Most existing works evaluated their systems by comparing the fine-tuned downstream task performance. However, only average downstream task accuracy provides little information about the pros and cons of each VLP method, let alone provides insights on how the community can improve the systems in the future. Inspired by the CheckList for testing natural language processing, we introduce VL-CheckList, a novel framework to understand the capabilities of VLP models. The proposed method divides the image-texting ability of a VLP model into three categories: objects, attributes, and relations, and uses a novel taxonomy to further break down these three aspects. We conduct comprehensive studies to analyze seven recently popular VLP models via the proposed framework. Results confirm the effectiveness of the proposed method by revealing fine-grained differences among the compared models that were not visible from downstream task-only evaluation. Further results show promising research direction in building better VLP models. Data and Code: https://github.com/om-ai-lab/VL-CheckList