 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCore Challenges in Embodied Vision-Language Planning
Apr 05, 2023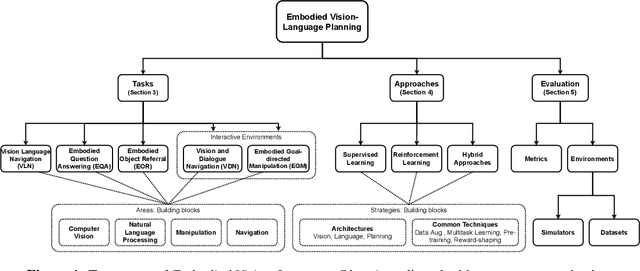
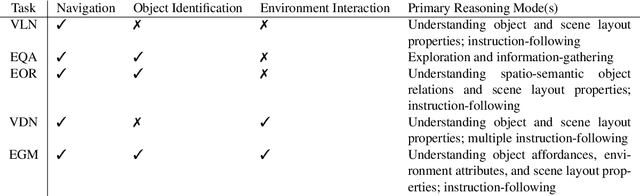
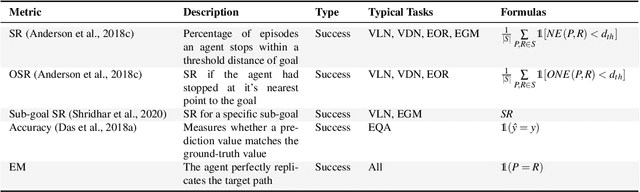

Recent advances in the areas of Multimodal Machine Learning and Artificial Intelligence (AI) have led to the development of challenging tasks at the intersection of Computer Vision, Natural Language Processing, and Robotics. Whereas many approaches and previous survey pursuits have characterised one or two of these dimensions, there has not been a holistic analysis at the center of all three. Moreover, even when combinations of these topics are considered, more focus is placed on describing, e.g., current architectural methods, as opposed to also illustrating high-level challenges and opportunities for the field. In this survey paper, we discuss Embodied Vision-Language Planning (EVLP) tasks, a family of prominent embodied navigation and manipulation problems that jointly leverage computer vision and natural language for interaction in physical environments. We propose a taxonomy to unify these tasks and provide an in-depth analysis and comparison of the current and new algorithmic approaches, metrics, simulators, and datasets used for EVLP tasks. Finally, we present the core challenges that we believe new EVLP works should seek to address, and we advocate for task construction that enables model generalisability and furthers real-world deployment.
OmDet: Language-Aware Object Detection with Large-scale Vision-Language Multi-dataset Pre-training
Sep 10, 2022


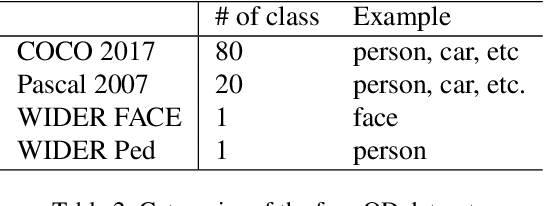
Advancing object detection to open-vocabulary and few-shot transfer has long been a challenge for computer vision research. This work explores a continual learning approach that enables a detector to expand its zero/few-shot capabilities via multi-dataset vision-language pre-training. Using natural language as knowledge representation, we explore methods to accumulate "visual vocabulary" from different training datasets and unify the task as a language-conditioned detection framework. Specifically, we propose a novel language-aware detector OmDet and a novel training mechanism. The proposed multimodal detection network can resolve the technical challenges in multi-dataset joint training and it can generalize to arbitrary number of training datasets without the requirements for manual label taxonomy merging. Experiment results on COCO, Pascal VOC, and Wider Face/Pedestrian confirmed the efficacy by achieving on par or higher scores in joint training compared to training separately. Moreover, we pre-train on more than 20 million images with 4 million unique object vocabulary, and the resulting model is evaluated on 35 downstream tasks of ODinW. Results show that OmDet is able to achieve the state-of-the-art fine-tuned performance on ODinW. And analysis shows that by scaling up the proposed pre-training method, OmDet continues to improve its zero/few-shot tuning performance, suggesting a promising way for further scaling.
VL-CheckList: Evaluating Pre-trained Vision-Language Models with Objects, Attributes and Relations
Jul 01, 2022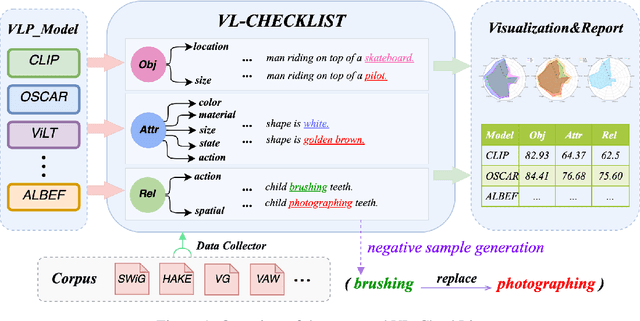
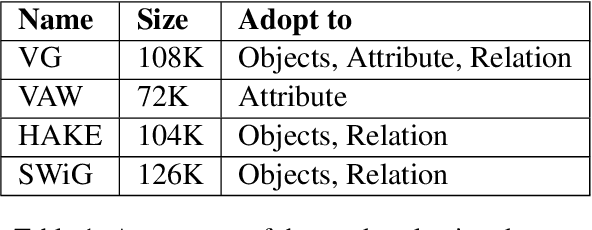
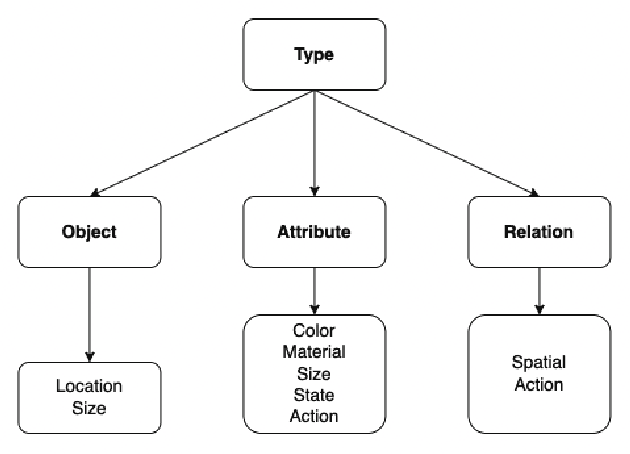
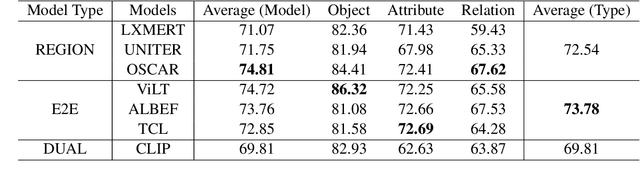
Vision-Language Pretraining (VLP) models have recently successfully facilitated many cross-modal downstream tasks. Most existing works evaluated their systems by comparing the fine-tuned downstream task performance. However, only average downstream task accuracy provides little information about the pros and cons of each VLP method, let alone provides insights on how the community can improve the systems in the future. Inspired by the CheckList for testing natural language processing, we introduce VL-CheckList, a novel framework to understand the capabilities of VLP models. The proposed method divides the image-texting ability of a VLP model into three categories: objects, attributes, and relations, and uses a novel taxonomy to further break down these three aspects. We conduct comprehensive studies to analyze seven recently popular VLP models via the proposed framework. Results confirm the effectiveness of the proposed method by revealing fine-grained differences among the compared models that were not visible from downstream task-only evaluation. Further results show promising research direction in building better VLP models. Data and Code: https://github.com/om-ai-lab/VL-CheckList
Localize, Group, and Select: Boosting Text-VQA by Scene Text Modeling
Aug 20, 2021
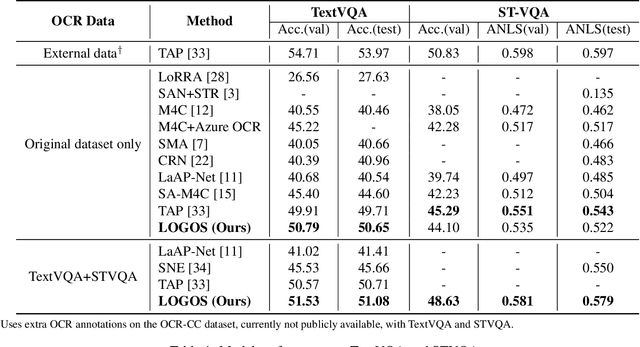
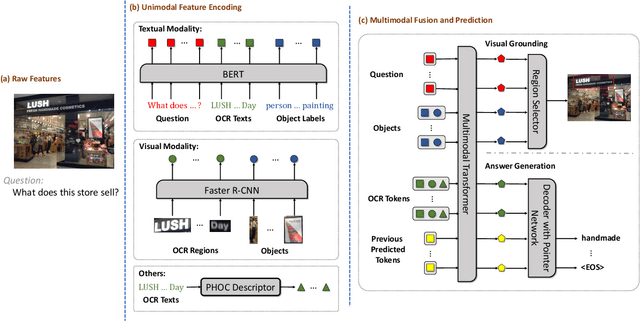
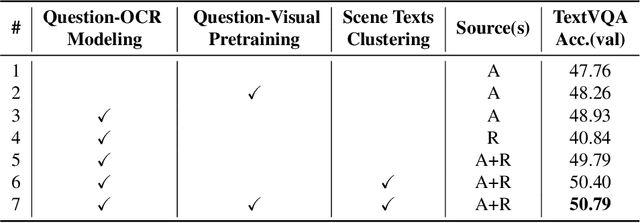
As an important task in multimodal context understanding, Text-VQA (Visual Question Answering) aims at question answering through reading text information in images. It differentiates from the original VQA task as Text-VQA requires large amounts of scene-text relationship understanding, in addition to the cross-modal grounding capability. In this paper, we propose Localize, Group, and Select (LOGOS), a novel model which attempts to tackle this problem from multiple aspects. LOGOS leverages two grounding tasks to better localize the key information of the image, utilizes scene text clustering to group individual OCR tokens, and learns to select the best answer from different sources of OCR (Optical Character Recognition) texts. Experiments show that LOGOS outperforms previous state-of-the-art methods on two Text-VQA benchmarks without using additional OCR annotation data. Ablation studies and analysis demonstrate the capability of LOGOS to bridge different modalities and better understand scene text.
CIGLI: Conditional Image Generation from Language & Image
Aug 20, 2021
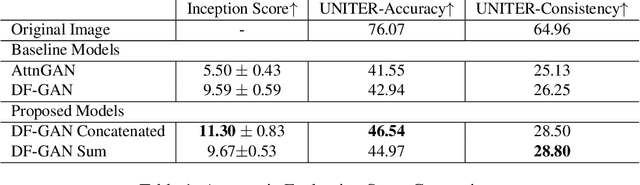


Multi-modal generation has been widely explored in recent years. Current research directions involve generating text based on an image or vice versa. In this paper, we propose a new task called CIGLI: Conditional Image Generation from Language and Image. Instead of generating an image based on text as in text-image generation, this task requires the generation of an image from a textual description and an image prompt. We designed a new dataset to ensure that the text description describes information from both images, and that solely analyzing the description is insufficient to generate an image. We then propose a novel language-image fusion model which improves the performance over two established baseline methods, as evaluated by quantitative (automatic) and qualitative (human) evaluations. The code and dataset is available at https://github.com/vincentlux/CIGLI.
SF-QA: Simple and Fair Evaluation Library for Open-domain Question Answering
Jan 06, 2021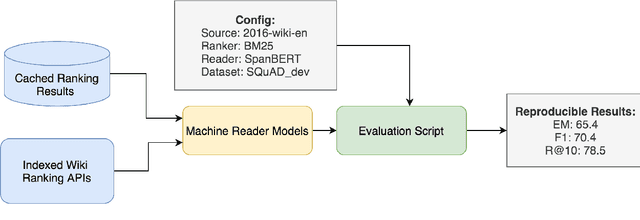
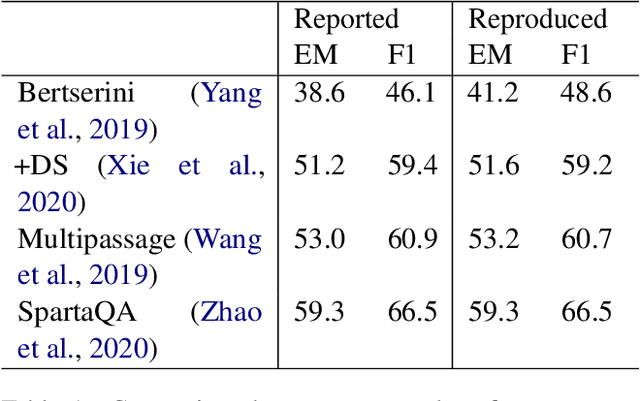
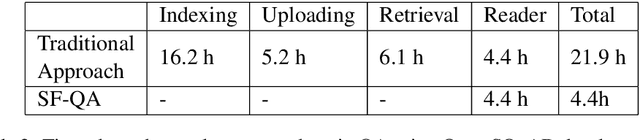

Although open-domain question answering (QA) draws great attention in recent years, it requires large amounts of resources for building the full system and is often difficult to reproduce previous results due to complex configurations. In this paper, we introduce SF-QA: simple and fair evaluation framework for open-domain QA. SF-QA framework modularizes the pipeline open-domain QA system, which makes the task itself easily accessible and reproducible to research groups without enough computing resources. The proposed evaluation framework is publicly available and anyone can contribute to the code and evaluations.
VisualSparta: Sparse Transformer Fragment-level Matching for Large-scale Text-to-Image Search
Jan 01, 2021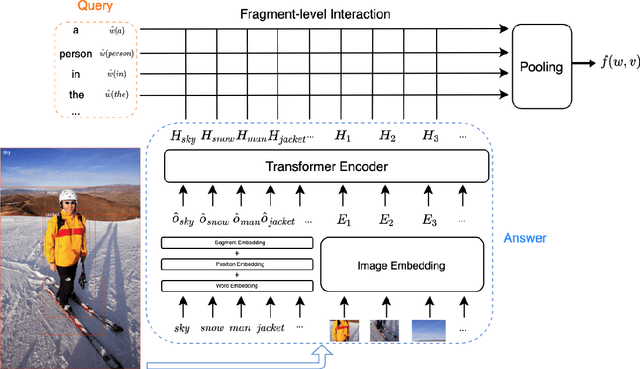
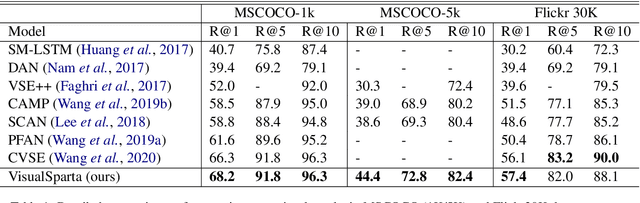
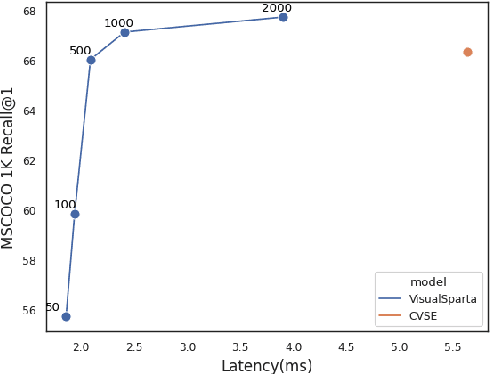
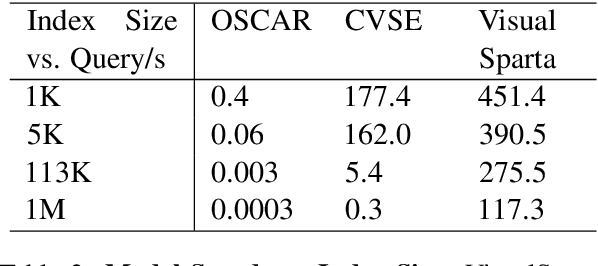
Text-to-image retrieval is an essential task in multi-modal information retrieval, i.e. retrieving relevant images from a large and unlabelled image dataset given textual queries. In this paper, we propose VisualSparta, a novel text-to-image retrieval model that shows substantial improvement over existing models on both accuracy and efficiency. We show that VisualSparta is capable of outperforming all previous scalable methods in MSCOCO and Flickr30K. It also shows substantial retrieving speed advantages, i.e. for an index with 1 million images, VisualSparta gets over 391x speed up compared to standard vector search. Experiments show that this speed advantage even gets bigger for larger datasets because VisualSparta can be efficiently implemented as an inverted index. To the best of our knowledge, VisualSparta is the first transformer-based text-to-image retrieval model that can achieve real-time searching for very large dataset, with significant accuracy improvement compared to previous state-of-the-art methods.
SPARTA: Efficient Open-Domain Question Answering via Sparse Transformer Matching Retrieval
Sep 28, 2020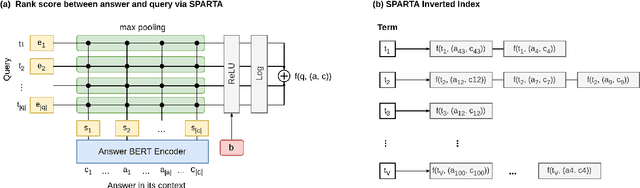
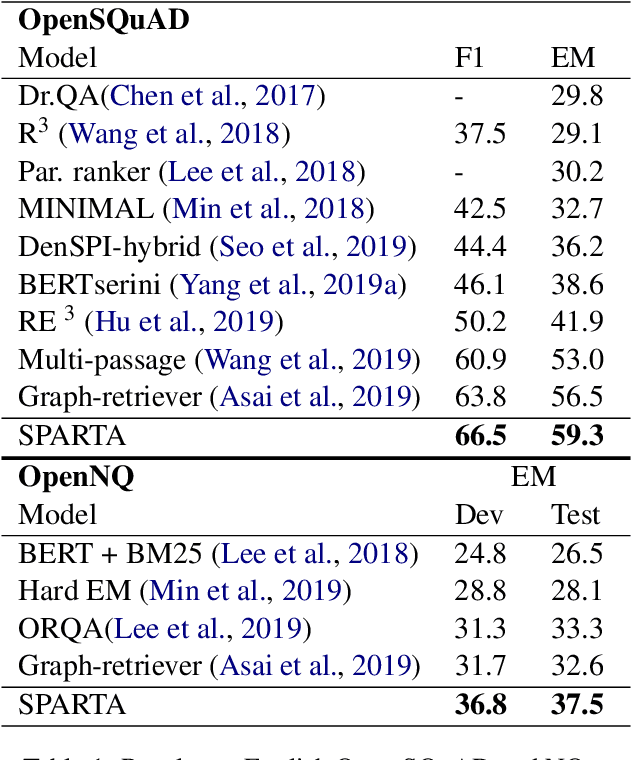
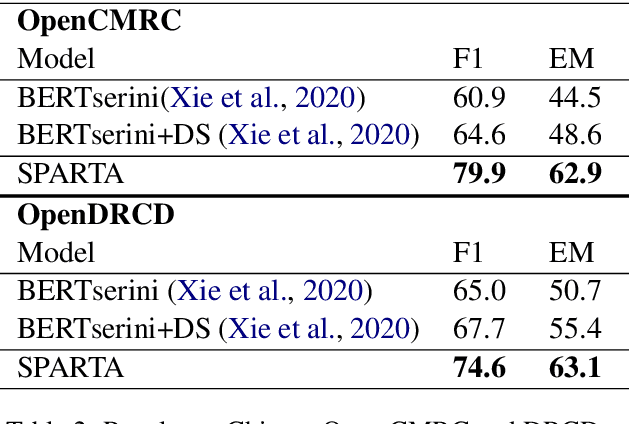
We introduce SPARTA, a novel neural retrieval method that shows great promise in performance, generalization, and interpretability for open-domain question answering. Unlike many neural ranking methods that use dense vector nearest neighbor search, SPARTA learns a sparse representation that can be efficiently implemented as an Inverted Index. The resulting representation enables scalable neural retrieval that does not require expensive approximate vector search and leads to better performance than its dense counterpart. We validated our approaches on 4 open-domain question answering (OpenQA) tasks and 11 retrieval question answering (ReQA) tasks. SPARTA achieves new state-of-the-art results across a variety of open-domain question answering tasks in both English and Chinese datasets, including open SQuAD, Natuarl Question, CMRC and etc. Analysis also confirms that the proposed method creates human interpretable representation and allows flexible control over the trade-off between performance and efficiency.