 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKuramoto Oscillatory Phase Encoding: Neuro-inspired Synchronization for Improved Learning Efficiency
Apr 09, 2026Spatiotemporal neural dynamics and oscillatory synchronization are widely implicated in biological information processing and have been hypothesized to support flexible coordination such as feature binding. By contrast, most deep learning architectures represent and propagate information through activation values, neglecting the joint dynamics of rate and phase. In this work, we introduce Kuramoto oscillatory Phase Encoding (KoPE) as an additional, evolving phase state to Vision Transformers, incorporating a neuro-inspired synchronization mechanism to advance learning efficiency. We show that KoPE can improve training, parameter, and data efficiency of vision models through synchronization-enhanced structure learning. Moreover, KoPE benefits tasks requiring structured understanding, including semantic and panoptic segmentation, representation alignment with language, and few-shot abstract visual reasoning (ARC-AGI). Theoretical analysis and empirical verification further suggest that KoPE can accelerate attention concentration for learning efficiency. These results indicate that synchronization can serve as a scalable, neuro-inspired mechanism for advancing state-of-the-art neural network models.
Improving Diffusion Planners by Self-Supervised Action Gating with Energies
Mar 03, 2026Diffusion planners are a strong approach for offline reinforcement learning, but they can fail when value-guided selection favours trajectories that score well yet are locally inconsistent with the environment dynamics, resulting in brittle execution. We propose Self-supervised Action Gating with Energies (SAGE), an inference-time re-ranking method that penalises dynamically inconsistent plans using a latent consistency signal. SAGE trains a Joint-Embedding Predictive Architecture (JEPA) encoder on offline state sequences and an action-conditioned latent predictor for short horizon transitions. At test time, SAGE assigns each sampled candidate an energy given by its latent prediction error and combines this feasibility score with value estimates to select actions. SAGE can integrate into existing diffusion planning pipelines that can sample trajectories and select actions via value scoring; it requires no environment rollouts and no policy re-training. Across locomotion, navigation, and manipulation benchmarks, SAGE improves the performance and robustness of diffusion planners.
Chain-of-Model Learning for Language Model
May 17, 2025In this paper, we propose a novel learning paradigm, termed Chain-of-Model (CoM), which incorporates the causal relationship into the hidden states of each layer as a chain style, thereby introducing great scaling efficiency in model training and inference flexibility in deployment. We introduce the concept of Chain-of-Representation (CoR), which formulates the hidden states at each layer as a combination of multiple sub-representations (i.e., chains) at the hidden dimension level. In each layer, each chain from the output representations can only view all of its preceding chains in the input representations. Consequently, the model built upon CoM framework can progressively scale up the model size by increasing the chains based on the previous models (i.e., chains), and offer multiple sub-models at varying sizes for elastic inference by using different chain numbers. Based on this principle, we devise Chain-of-Language-Model (CoLM), which incorporates the idea of CoM into each layer of Transformer architecture. Based on CoLM, we further introduce CoLM-Air by introducing a KV sharing mechanism, that computes all keys and values within the first chain and then shares across all chains. This design demonstrates additional extensibility, such as enabling seamless LM switching, prefilling acceleration and so on. Experimental results demonstrate our CoLM family can achieve comparable performance to the standard Transformer, while simultaneously enabling greater flexiblity, such as progressive scaling to improve training efficiency and offer multiple varying model sizes for elastic inference, paving a a new way toward building language models. Our code will be released in the future at: https://github.com/microsoft/CoLM.
SimSort: A Powerful Framework for Spike Sorting by Large-Scale Electrophysiology Simulation
Feb 05, 2025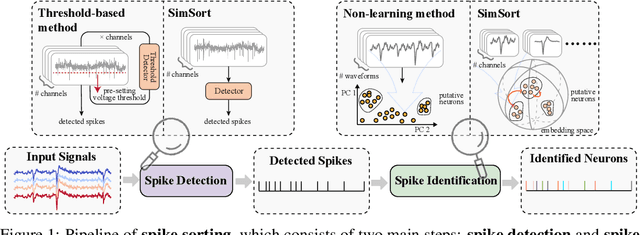

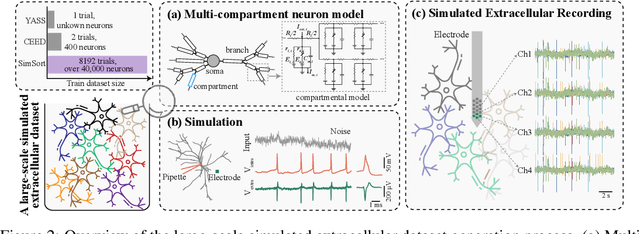
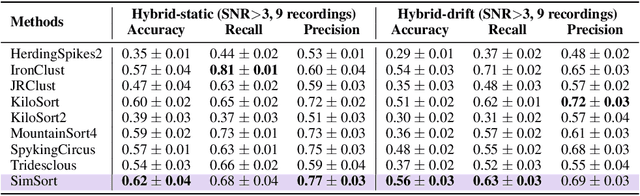
Spike sorting is an essential process in neural recording, which identifies and separates electrical signals from individual neurons recorded by electrodes in the brain, enabling researchers to study how specific neurons communicate and process information. Although there exist a number of spike sorting methods which have contributed to significant neuroscientific breakthroughs, many are heuristically designed, making it challenging to verify their correctness due to the difficulty of obtaining ground truth labels from real-world neural recordings. In this work, we explore a data-driven, deep learning-based approach. We begin by creating a large-scale dataset through electrophysiology simulations using biologically realistic computational models. We then present \textbf{SimSort}, a pretraining framework for spike sorting. Remarkably, when trained on our simulated dataset, SimSort demonstrates strong zero-shot generalization to real-world spike sorting tasks, significantly outperforming existing methods. Our findings underscore the potential of data-driven techniques to enhance the reliability and scalability of spike sorting in experimental neuroscience.
Toward Relative Positional Encoding in Spiking Transformers
Jan 28, 2025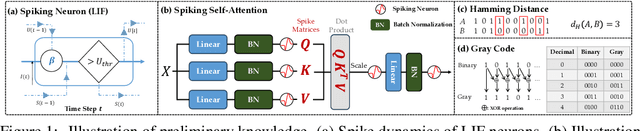

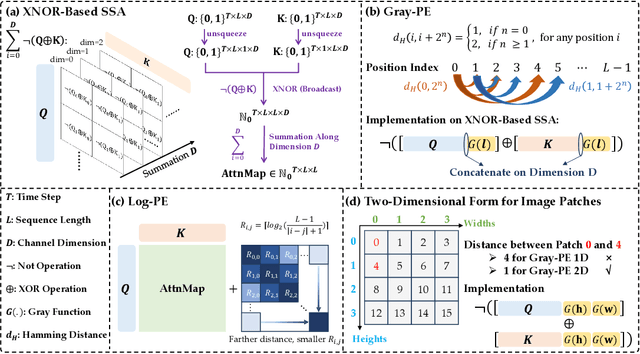

Spiking neural networks (SNNs) are bio-inspired networks that model how neurons in the brain communicate through discrete spikes, which have great potential in various tasks due to their energy efficiency and temporal processing capabilities. SNNs with self-attention mechanisms (Spiking Transformers) have recently shown great advancements in various tasks such as sequential modeling and image classifications. However, integrating positional information, which is essential for capturing sequential relationships in data, remains a challenge in Spiking Transformers. In this paper, we introduce an approximate method for relative positional encoding (RPE) in Spiking Transformers, leveraging Gray Code as the foundation for our approach. We provide comprehensive proof of the method's effectiveness in partially capturing relative positional information for sequential tasks. Additionally, we extend our RPE approach by adapting it to a two-dimensional form suitable for image patch processing. We evaluate the proposed RPE methods on several tasks, including time series forecasting, text classification, and patch-based image classification. Our experimental results demonstrate that the incorporation of RPE significantly enhances performance by effectively capturing relative positional information.
Translating Mental Imaginations into Characters with Codebooks and Dynamics-Enhanced Decoding
Sep 25, 2024



Advancements in non-invasive electroencephalogram (EEG)-based Brain-Computer Interface (BCI) technology have enabled communication through brain activity, offering significant potential for individuals with motor impairments. Existing methods for decoding characters or words from EEG recordings either rely on continuous external stimulation for high decoding accuracy or depend on direct intention imagination, which suffers from reduced discrimination ability. To overcome these limitations, we introduce a novel EEG paradigm based on mental tasks that achieves high discrimination accuracy without external stimulation. Specifically, we propose a codebook in which each letter or number is associated with a unique code that integrates three mental tasks, interleaved with eye-open and eye-closed states. This approach allows individuals to internally reference characters without external stimuli while maintaining reasonable accuracy. For enhanced decoding performance, we apply a Temporal-Spatial-Latent-Dynamics (TSLD) network to capture latent dynamics of spatiotemporal EEG signals. Experimental results demonstrate the effectiveness of our proposed EEG paradigm which achieves five times higher accuracy over direct imagination. Additionally, the TSLD network improves baseline methods by approximately 8.5%. Further more, we observe consistent performance improvement throughout the data collection process, suggesting that the proposed paradigm has potential for further optimization with continued use.
NeuroLM: A Universal Multi-task Foundation Model for Bridging the Gap between Language and EEG Signals
Aug 27, 2024Recent advancements for large-scale pre-training with neural signals such as electroencephalogram (EEG) have shown promising results, significantly boosting the development of brain-computer interfaces (BCIs) and healthcare. However, these pre-trained models often require full fine-tuning on each downstream task to achieve substantial improvements, limiting their versatility and usability, and leading to considerable resource wastage. To tackle these challenges, we propose NeuroLM, the first multi-task foundation model that leverages the capabilities of Large Language Models (LLMs) by regarding EEG signals as a foreign language, endowing the model with multi-task learning and inference capabilities. Our approach begins with learning a text-aligned neural tokenizer through vector-quantized temporal-frequency prediction, which encodes EEG signals into discrete neural tokens. These EEG tokens, generated by the frozen vector-quantized (VQ) encoder, are then fed into an LLM that learns causal EEG information via multi-channel autoregression. Consequently, NeuroLM can understand both EEG and language modalities. Finally, multi-task instruction tuning adapts NeuroLM to various downstream tasks. We are the first to demonstrate that, by specific incorporation with LLMs, NeuroLM unifies diverse EEG tasks within a single model through instruction tuning. The largest variant NeuroLM-XL has record-breaking 1.7B parameters for EEG signal processing, and is pre-trained on a large-scale corpus comprising approximately 25,000-hour EEG data. When evaluated on six diverse downstream datasets, NeuroLM showcases the huge potential of this multi-task learning paradigm.
The VEP Booster: A Closed-Loop AI System for Visual EEG Biomarker Auto-generation
Jul 21, 2024


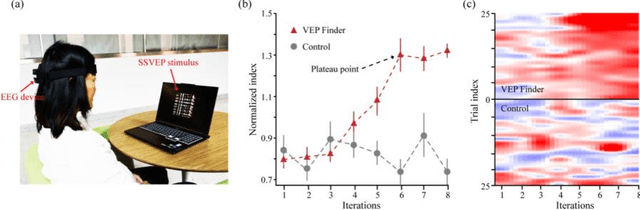
Effective visual brain-machine interfaces (BMI) is based on reliable and stable EEG biomarkers. However, traditional adaptive filter-based approaches may suffer from individual variations in EEG signals, while deep neural network-based approaches may be hindered by the non-stationarity of EEG signals caused by biomarker attenuation and background oscillations. To address these challenges, we propose the Visual Evoked Potential Booster (VEP Booster), a novel closed-loop AI framework that generates reliable and stable EEG biomarkers under visual stimulation protocols. Our system leverages an image generator to refine stimulus images based on real-time feedback from human EEG signals, generating visual stimuli tailored to the preferences of primary visual cortex (V1) neurons and enabling effective targeting of neurons most responsive to stimuli. We validated our approach by implementing a system and employing steady-state visual evoked potential (SSVEP) visual protocols in five human subjects. Our results show significant enhancements in the reliability and utility of EEG biomarkers for all individuals, with the largest improvement in SSVEP response being 105%, the smallest being 28%, and the average increase being 76.5%. These promising results have implications for both clinical and technological applications
Advancing Spiking Neural Networks for Sequential Modeling with Central Pattern Generators
May 23, 2024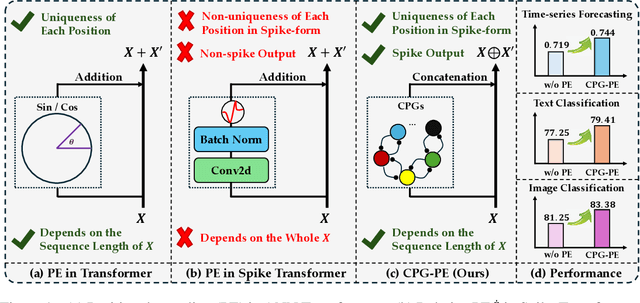
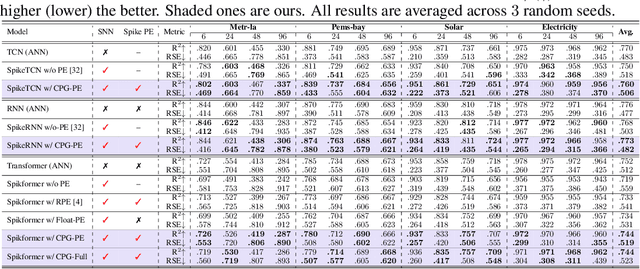
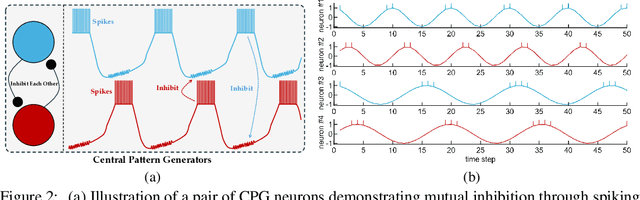

Spiking neural networks (SNNs) represent a promising approach to developing artificial neural networks that are both energy-efficient and biologically plausible. However, applying SNNs to sequential tasks, such as text classification and time-series forecasting, has been hindered by the challenge of creating an effective and hardware-friendly spike-form positional encoding (PE) strategy. Drawing inspiration from the central pattern generators (CPGs) in the human brain, which produce rhythmic patterned outputs without requiring rhythmic inputs, we propose a novel PE technique for SNNs, termed CPG-PE. We demonstrate that the commonly used sinusoidal PE is mathematically a specific solution to the membrane potential dynamics of a particular CPG. Moreover, extensive experiments across various domains, including time-series forecasting, natural language processing, and image classification, show that SNNs with CPG-PE outperform their conventional counterparts. Additionally, we perform analysis experiments to elucidate the mechanism through which SNNs encode positional information and to explore the function of CPGs in the human brain. This investigation may offer valuable insights into the fundamental principles of neural computation.
A Large-scale Medical Visual Task Adaptation Benchmark
Apr 19, 2024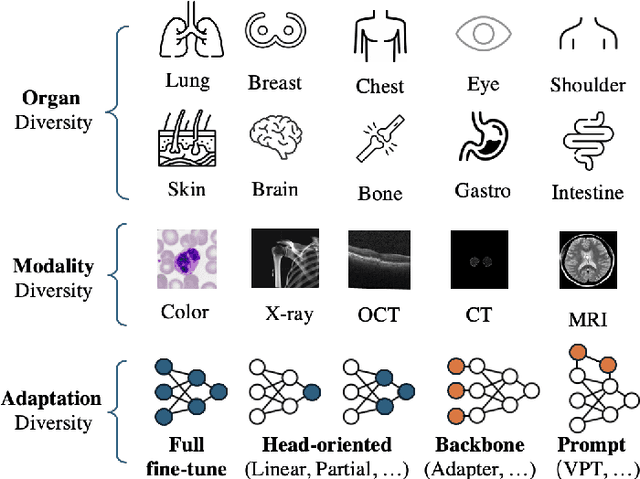
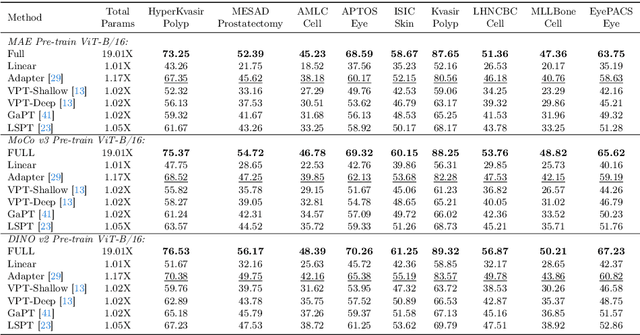
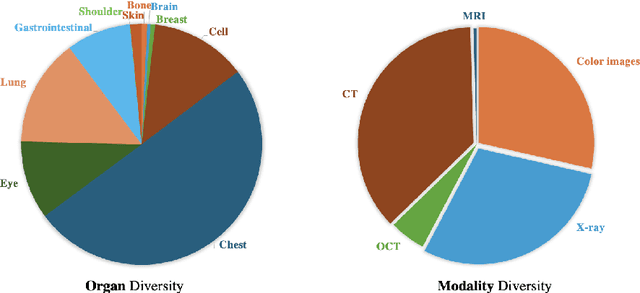
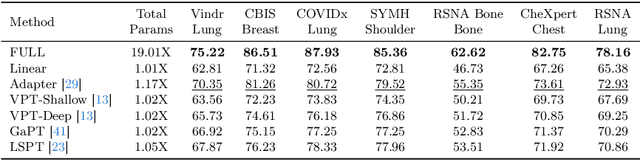
Visual task adaptation has been demonstrated to be effective in adapting pre-trained Vision Transformers (ViTs) to general downstream visual tasks using specialized learnable layers or tokens. However, there is yet a large-scale benchmark to fully explore the effect of visual task adaptation on the realistic and important medical domain, particularly across diverse medical visual modalities, such as color images, X-ray, and CT. To close this gap, we present Med-VTAB, a large-scale Medical Visual Task Adaptation Benchmark consisting of 1.68 million medical images for diverse organs, modalities, and adaptation approaches. Based on Med-VTAB, we explore the scaling law of medical prompt tuning concerning tunable parameters and the generalizability of medical visual adaptation using non-medical/medical pre-train weights. Besides, we study the impact of patient ID out-of-distribution on medical visual adaptation, which is a real and challenging scenario. Furthermore, results from Med-VTAB indicate that a single pre-trained model falls short in medical task adaptation. Therefore, we introduce GMoE-Adapter, a novel method that combines medical and general pre-training weights through a gated mixture-of-experts adapter, achieving state-of-the-art results in medical visual task adaptation.