 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRAC: Principal-Random Subspace for LLM Activation Compression and Memory-Efficient Training
Feb 26, 2026Activations have become the primary memory bottleneck in large-batch LLM training. However, existing compression methods fail to exploit the spectral structure of activations, resulting in slow convergence or limited compression. To address this, we bridge the relationship between the algorithm's fast convergence and the requirements for subspace projection, and show that an effective compression should yield an unbiased estimate of the original activation with low variance. We propose Principal-Random Subspace for LLM Activation Compression (PRAC), which novelly decomposes activations into two components: a principal subspace captured via SVD to retain dominant information, and a random subspace sampled from the orthogonal complement to approximate the tail. By introducing a precise scaling factor, we prove that PRAC yields an unbiased gradient estimator with minimum variance under certain conditions. Extensive experiments on pre-training and fine-tuning tasks demonstrate that PRAC achieves up to 36% total memory reduction with negligible performance degradation and minimal computational cost.
SimSort: A Powerful Framework for Spike Sorting by Large-Scale Electrophysiology Simulation
Feb 05, 2025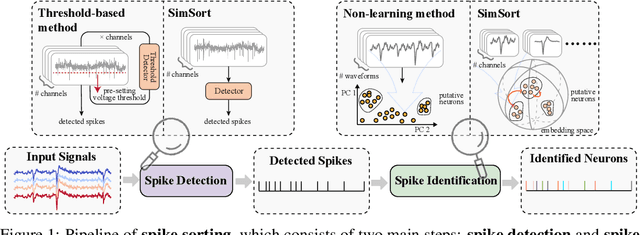

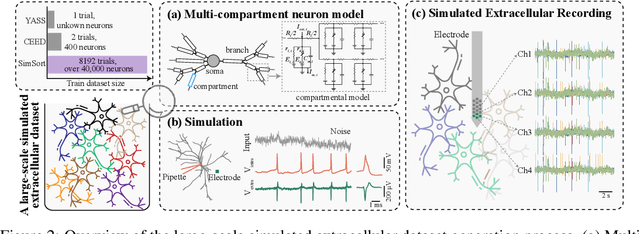
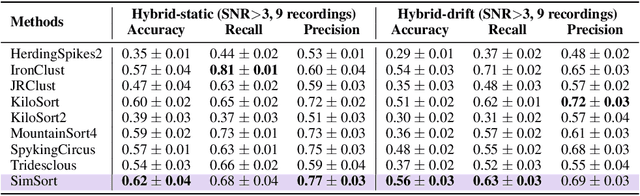
Spike sorting is an essential process in neural recording, which identifies and separates electrical signals from individual neurons recorded by electrodes in the brain, enabling researchers to study how specific neurons communicate and process information. Although there exist a number of spike sorting methods which have contributed to significant neuroscientific breakthroughs, many are heuristically designed, making it challenging to verify their correctness due to the difficulty of obtaining ground truth labels from real-world neural recordings. In this work, we explore a data-driven, deep learning-based approach. We begin by creating a large-scale dataset through electrophysiology simulations using biologically realistic computational models. We then present \textbf{SimSort}, a pretraining framework for spike sorting. Remarkably, when trained on our simulated dataset, SimSort demonstrates strong zero-shot generalization to real-world spike sorting tasks, significantly outperforming existing methods. Our findings underscore the potential of data-driven techniques to enhance the reliability and scalability of spike sorting in experimental neuroscience.