 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Multimodal Physiological Foundation Models: Handling Arbitrary Missing Modalities
Apr 28, 2025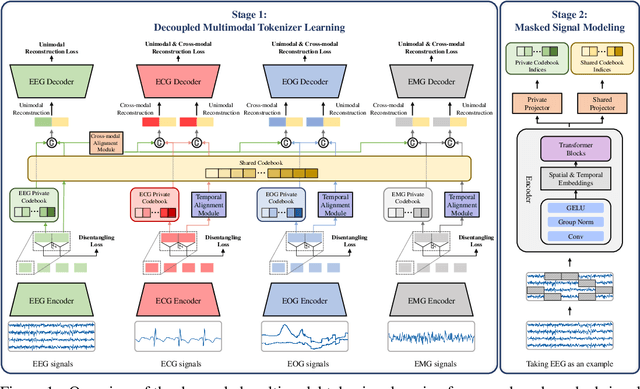

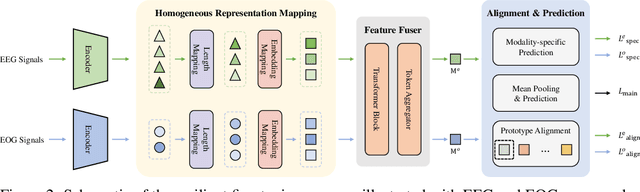
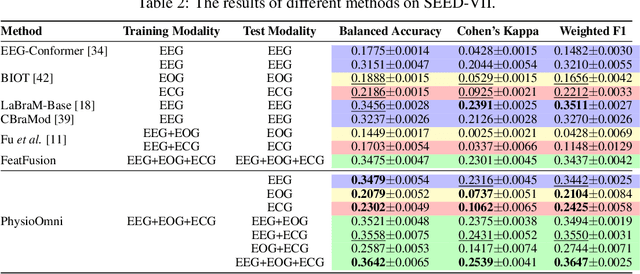
Multimodal physiological signals, such as EEG, ECG, EOG, and EMG, are crucial for healthcare and brain-computer interfaces. While existing methods rely on specialized architectures and dataset-specific fusion strategies, they struggle to learn universal representations that generalize across datasets and handle missing modalities at inference time. To address these issues, we propose PhysioOmni, a foundation model for multimodal physiological signal analysis that models both homogeneous and heterogeneous features to decouple multimodal signals and extract generic representations while maintaining compatibility with arbitrary missing modalities. PhysioOmni trains a decoupled multimodal tokenizer, enabling masked signal pre-training via modality-invariant and modality-specific objectives. To ensure adaptability to diverse and incomplete modality combinations, the pre-trained encoders undergo resilient fine-tuning with prototype alignment on downstream datasets. Extensive experiments on four downstream tasks, emotion recognition, sleep stage classification, motor prediction, and mental workload detection, demonstrate that PhysioOmni achieves state-of-the-art performance while maintaining strong robustness to missing modalities. Our code and model weights will be released.
NeuroLM: A Universal Multi-task Foundation Model for Bridging the Gap between Language and EEG Signals
Aug 27, 2024Recent advancements for large-scale pre-training with neural signals such as electroencephalogram (EEG) have shown promising results, significantly boosting the development of brain-computer interfaces (BCIs) and healthcare. However, these pre-trained models often require full fine-tuning on each downstream task to achieve substantial improvements, limiting their versatility and usability, and leading to considerable resource wastage. To tackle these challenges, we propose NeuroLM, the first multi-task foundation model that leverages the capabilities of Large Language Models (LLMs) by regarding EEG signals as a foreign language, endowing the model with multi-task learning and inference capabilities. Our approach begins with learning a text-aligned neural tokenizer through vector-quantized temporal-frequency prediction, which encodes EEG signals into discrete neural tokens. These EEG tokens, generated by the frozen vector-quantized (VQ) encoder, are then fed into an LLM that learns causal EEG information via multi-channel autoregression. Consequently, NeuroLM can understand both EEG and language modalities. Finally, multi-task instruction tuning adapts NeuroLM to various downstream tasks. We are the first to demonstrate that, by specific incorporation with LLMs, NeuroLM unifies diverse EEG tasks within a single model through instruction tuning. The largest variant NeuroLM-XL has record-breaking 1.7B parameters for EEG signal processing, and is pre-trained on a large-scale corpus comprising approximately 25,000-hour EEG data. When evaluated on six diverse downstream datasets, NeuroLM showcases the huge potential of this multi-task learning paradigm.
Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI
May 29, 2024The current electroencephalogram (EEG) based deep learning models are typically designed for specific datasets and applications in brain-computer interaction (BCI), limiting the scale of the models and thus diminishing their perceptual capabilities and generalizability. Recently, Large Language Models (LLMs) have achieved unprecedented success in text processing, prompting us to explore the capabilities of Large EEG Models (LEMs). We hope that LEMs can break through the limitations of different task types of EEG datasets, and obtain universal perceptual capabilities of EEG signals through unsupervised pre-training. Then the models can be fine-tuned for different downstream tasks. However, compared to text data, the volume of EEG datasets is generally small and the format varies widely. For example, there can be mismatched numbers of electrodes, unequal length data samples, varied task designs, and low signal-to-noise ratio. To overcome these challenges, we propose a unified foundation model for EEG called Large Brain Model (LaBraM). LaBraM enables cross-dataset learning by segmenting the EEG signals into EEG channel patches. Vector-quantized neural spectrum prediction is used to train a semantically rich neural tokenizer that encodes continuous raw EEG channel patches into compact neural codes. We then pre-train neural Transformers by predicting the original neural codes for the masked EEG channel patches. The LaBraMs were pre-trained on about 2,500 hours of various types of EEG signals from around 20 datasets and validated on multiple different types of downstream tasks. Experiments on abnormal detection, event type classification, emotion recognition, and gait prediction show that our LaBraM outperforms all compared SOTA methods in their respective fields. Our code is available at https://github.com/935963004/LaBraM.
Du-IN: Discrete units-guided mask modeling for decoding speech from Intracranial Neural signals
May 19, 2024Invasive brain-computer interfaces have garnered significant attention due to their high performance. The current intracranial stereoElectroEncephaloGraphy (sEEG) foundation models typically build univariate representations based on a single channel. Some of them further use Transformer to model the relationship among channels. However, due to the locality and specificity of brain computation, their performance on more difficult tasks, e.g., speech decoding, which demands intricate processing in specific brain regions, is yet to be fully investigated. We hypothesize that building multi-variate representations within certain brain regions can better capture the specific neural processing. To explore this hypothesis, we collect a well-annotated Chinese word-reading sEEG dataset, targeting language-related brain networks, over 12 subjects. Leveraging this benchmark dataset, we developed the Du-IN model that can extract contextual embeddings from specific brain regions through discrete codebook-guided mask modeling. Our model achieves SOTA performance on the downstream 61-word classification task, surpassing all baseline models. Model comparison and ablation analysis reveal that our design choices, including (i) multi-variate representation by fusing channels in vSMC and STG regions and (ii) self-supervision by discrete codebook-guided mask modeling, significantly contribute to these performances. Collectively, our approach, inspired by neuroscience findings, capitalizing on multi-variate neural representation from specific brain regions, is suitable for invasive brain modeling. It marks a promising neuro-inspired AI approach in BCI.